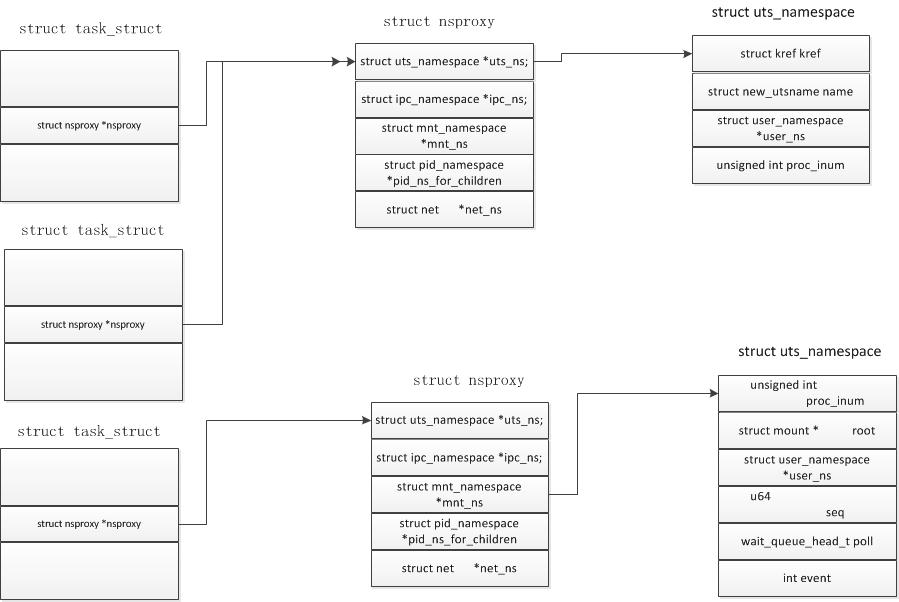
Linux Namespaces机制提供一种资源隔离方案。PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他namespace下的资源都是透明,不可见的。因此在操作系统层面上看,就会出现多个相同pid的进程。系统中可以同时存在两个进程号为0,1,2的进程,由于属于不同的namespace,所以它们之间并不冲突。而在用户层面上只能看到属于用户自己namespace下的资源,例如使用ps命令只能列出自己namespace下的进程。这样每个namespace看上去就像一个单独的Linux系统。
/* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};
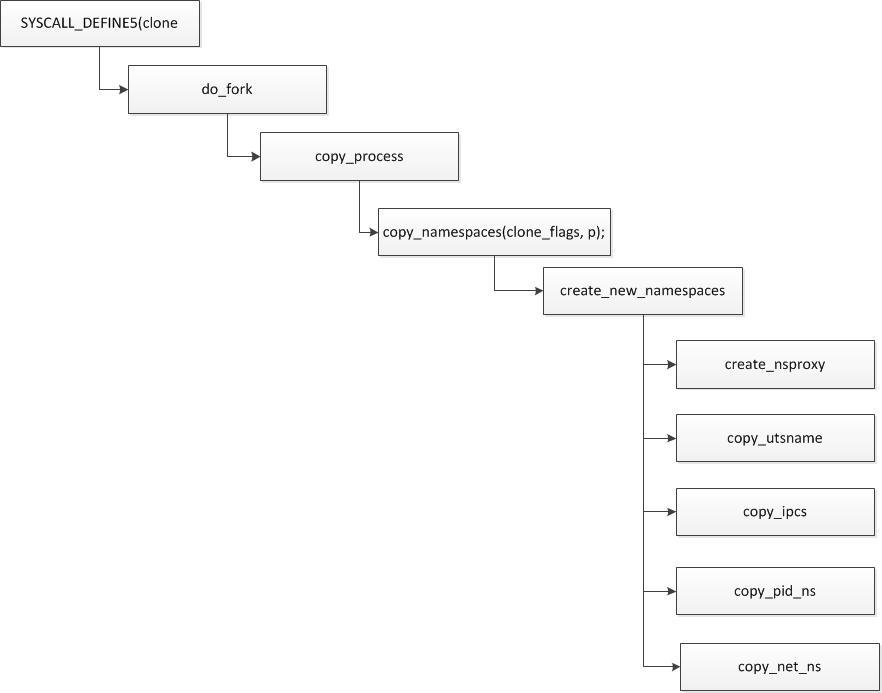
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
/*首先检查flag,如果flag标志不是下面的五种之一,就会调用get_nsproxy对old_ns递减引用计数,然后直接返回0*/
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))) {
get_nsproxy(old_ns);
return 0;
}
/*当前进程是否有超级用户的权限*/
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
/*
* CLONE_NEWIPC must detach from the undolist: after switching
* to a new ipc namespace, the semaphore arrays from the old
* namespace are unreachable. In clone parlance, CLONE_SYSVSEM
* means share undolist with parent, so we must forbid using
* it along with CLONE_NEWIPC.
对CLONE_NEWIPC进行特殊的判断,*/
if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) ==
(CLONE_NEWIPC | CLONE_SYSVSEM))
return -EINVAL;
/*为进程创建新的namespace*/
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
if (IS_ERR(new_ns))
return PTR_ERR(new_ns);
tsk->nsproxy = new_ns;
return 0;
}
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#include <sched.h>
#include <string.h>
static int fork_child(void *arg)
{
int a = (int)arg;
int i;
pid_t pid;
char *cmd = "ps -el;
printf("In the container, my pid is: %d\n", getpid());
/*ps命令是解析procfs的内容得到结果的,而procfs根目录的进程pid目录是基于mount当时的pid namespace的,这个在procfs的get_sb回调中体现的。因此只需要重新mount一下proc, mount -t proc proc /proc*/
mount("proc", "/proc", "proc", 0, "");
for (i = 0; i <a; i++) {
pid = fork();
if (pid <0)
return pid;
else if (pid)
printf("pid of my child is %d\n", pid);
else if (pid == 0) {
sleep(30);
exit(0);
}
}
execl("/bin/bash", "/bin/bash","-c",cmd, NULL);
return 0;
}
int main(int argc, char *argv[])
{
int cpid;
void *childstack, *stack;
int flags;
int ret = 0;
int stacksize = getpagesize() * 4;
if (argc != 2) {
fprintf(stderr, "Wrong usage.\n");
return -1;
}
stack = malloc(stacksize);
if(stack == NULL)
{
return -1;
}
printf("Out of the container, my pid is: %d\n", getpid());
childstack = stack + stacksize;
flags = CLONE_NEWPID | CLONE_NEWNS;
cpid = clone(fork_child, childstack, flags, (void *)atoi(argv[1]));
printf("cpid: %d\n", cpid);
if (cpid <0) {
perror("clone");
ret = -1;
goto out;
}
fprintf(stderr, "Parent sleeping 20 seconds\n");
sleep(20);
ret = 0;
out:
free(stack);
return ret;
}
运行结果:
123456789101112131415161718192021
root@Ubuntu:~/c_program# ./namespace 7
Out of the container, my pid is: 8684
cpid: 8685
Parent sleeping 20 seconds
In the container, my pid is: 1
pid of my child is 2
pid of my child is 3
pid of my child is 4
pid of my child is 5
pid of my child is 6
pid of my child is 7
pid of my child is 8
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 R 0 1 0 0 80 0 - 1085 - pts/0 00:00:00 ps
1 S 0 2 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 3 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 4 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 5 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 6 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 7 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
1 S 0 8 1 0 80 0 - 458 hrtime pts/0 00:00:00 namespace
#define _GNU_SOURCE
#include <sys/wait.h>
#include <sys/utsname.h>
#include <sched.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
static int /* Start function for cloned child */
childFunc(void *arg)
{
struct utsname uts;
/* Change hostname in UTS namespace of child */
if (sethostname(arg, strlen(arg)) == -1)
errExit("sethostname");
/* Retrieve and display hostname */
if (uname(&uts) == -1)
errExit("uname");
printf("uts.nodename in child: %s\n", uts.nodename);
/* Keep the namespace open for a while, by sleeping.
* This allows some experimentation--for example, another
* process might join the namespace. */
sleep(200);
return 0; /* Child terminates now */
}
#define STACK_SIZE (1024 * 1024) /* Stack size for cloned child */
int
main(int argc, char *argv[])
{
char *stack; /* Start of stack buffer */
char *stackTop; /* End of stack buffer */
pid_t pid;
struct utsname uts;
if (argc < 2) {
fprintf(stderr, "Usage: %s <child-hostname>\n", argv[0]);
exit(EXIT_SUCCESS);
}
/* Allocate stack for child */
stack = malloc(STACK_SIZE);
if (stack == NULL)
errExit("malloc");
stackTop = stack + STACK_SIZE; /* Assume stack grows downward */
/* Create child that has its own UTS namespace;
* child commences execution in childFunc() */
pid = clone(childFunc, stackTop, CLONE_NEWUTS | SIGCHLD, argv[1]);
if (pid == -1)
errExit("clone");
printf("clone() returned %ld\n", (long) pid);
/* Parent falls through to here */
sleep(1); /* Give child time to change its hostname */
/* Display hostname in parent's UTS namespace. This will be
* different from hostname in child's UTS namespace. */
if (uname(&uts) == -1)
errExit("uname");
printf("uts.nodename in parent: %s\n", uts.nodename);
if (waitpid(pid, NULL, 0) == -1) /* Wait for child */
errExit("waitpid");
printf("child has terminated\n");
exit(EXIT_SUCCESS);
}
1234
root@ubuntu:~/c_program# ./namespace_1 test
clone() returned 4101
uts.nodename in child: test
uts.nodename in parent: ubuntu