

http://blog.csdn.net/qy532846454/article/details/6423496
http://blog.csdn.net/qy532846454/article/details/6726171
http://blog.csdn.net/qy532846454/article/details/7568994
路由表
在内核中存在路由表fib_table_hash和路由缓存表rt_hash_table。路由缓存表主要是为了加速路由的查找,每次路由查询都会先查找路由缓存,再查找路由表。这和cache是一个道理,缓存存储最近使用过的路由项,容量小,查找快速;路由表存储所有路由项,容量大,查找慢。
首先,应该先了解路由表的意义,下面是route命令查看到的路由表:
1 2 3 4 | |
一条路由其实就是告知主机要到达一个目的地址,下一跳应该走哪里。比如发往192.168.22.3报文通过查路由表,会得到下一跳为192.168.123.254,再将其发送出去。在路由表项中,还有一个很重要的属性-scope,它代表了到目的网络的距离。
路由scope可取值:RT_SCOPE_UNIVERSE, RT_SCOPE_LINK, RT_SCOPE_HOST
在报文的转发过程中,显然是每次转发都要使到达目的网络的距离要越来越小或不变,否则根本到达不了目的网络。上面提到的scope很好的实现这个功能,在查找路由表中,表项的scope一定是更小或相等的scope(比如RT_SCOPE_LINK,则表项scope只能为RT_SCOPE_LINK或RT_SCOPE_HOST)。
路由缓存
路由缓存用于加速路由的查找,当收到报文或发送报文时,首先会查询路由缓存,在内核中被组织成hash表,就是rt_hash_table。
1
| |
通过ip_route_input()进行查询,首先是缓存操作时,通过[src_ip, dst_ip, iif,rt_genid]计算出hash值
1
| |
此时rt_hash_table[hash].chain就是要操作的缓存表项的链表,比如遍历该链表
1
| |
因此,在缓存中查找一个表项,首先计算出hash值,取出这组表项,然后遍历链表,找出指定的表项,这里需要完全匹配[src_ip, dst_ip, iif, tos, mark, net],实际上struct rtable中有专门的属性用于缓存的查找键值 – struct flowi。
1 2 | |
当找到表项后会更新表项的最后访问时间,并取出dst
1 2 | |
路由缓存的创建
inet_init() -> ip_init() -> ip_rt_init()
1 2 3 4 5 6 7 8 9 10 | |
其中rt_hash_mask表示表的大小,rt_hash_log = log(rt_hash_mask),创建后的结构如图所示:
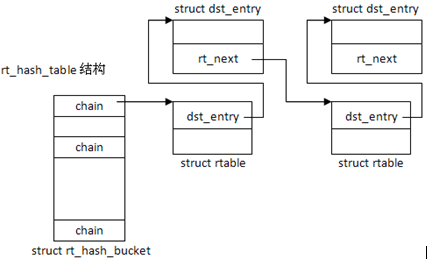
路由缓存插入条目
函数rt_intern_hash()
要插入的条目是rt,相应散列值是hash,首先通过hash值找到对应的bucket
1
| |
然后对bucket进行一遍查询,这次查询的目的有两个:如果是超时的条目,则直接删除;如果是与rt相同键值的条目,则删除并将rt插入头部返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
在扫描一遍后,如rt还未存在,则将其插入头部
1 2 | |
如果新插入rt满足一定条件,还要与ARP邻居表进行绑定
Hint:缓存的每个bucket是没有头结点的,单向链表,它所使用的插入和删除操作是值得学习的,简单实用。
路由缓存删除条目
rt_del()
要删除的条目是rt,相应散列值是hash,首先通过hash值找到对应的bucket,然后遍历,如果条目超时,或找到rt,则删除它。
1 2 3 4 5 6 7 8 9 10 11 12 | |
路由表的创建
inet_init() -> ip_init() -> ip_fib_init() -> fib_net_init() -> ip_fib_net_init()[net/ipv4/fib_frontend.c]
首先为路由表分配空间,这里的每个表项hlist_head实际都会链接一个单独的路由表,FIB_TABLE_HASHSZ表示了分配多少个路由表,一般情况下至少有两个 – LOCAL和MAIN。注意这里仅仅是表头的空间分配,还没有真正分配路由表空间。
1 2 | |
ip_fib_net_init() -> fib4_rules_init(),这里真正分配了路由表空间
1 2 | |
然后将local和main表链入之前的fib_table_hash中
1 2 3 4 5 | |
最终生成结构如图,LOCAL表位于fib_table_hash[0],MAIN表位于fib_table_hash[1];两张表通过结构tb_hlist链入链表,而tb_id则标识了功能,255是LOCAL表,254是MAIN表。
关于这里的struct fn_hash,它表示了不同子网掩码长度的hash表[即fn_zone],对于ipv4,从0~32共33个。而fn_hash的实现则是fib_table的最后一个参数unsigned char tb_data[0]。
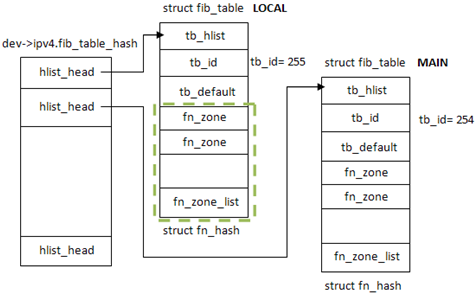
注意到这里fn_zone还只是空指针,我们还只完成了路由表初始化的一部分。在启动阶段还会调用inet_rtm_newroute() -> fib_table_insert() -> fn_new_zone() [fib_hash.c]来创建fn_zone结构,前面已经讲过,fn_zone一共有33个,其中掩码长度为0[/0]表示为默认路由,fn_zone可以理解为相同掩码的地址集合。
首先为fn_zone分配空间
1
| |
传入参数z代表掩码长度, z = 0的掩码用于默认路由,一般只有一个,所以fz_divisor只需设为1;其它设为16;这里要提到fz_divisor的作用,fz->fz_hash并不是个单链表,而是一个哈希表,而哈希表的大小就是fz_divisor。
1 2 3 4 5 | |
fz_hashmask实际是用于求余数的,当算出hash值,再hash & fz_hashmask就得出了在哈希表的位置;而fz_hash就是下一层的哈希表了,前面已经提过路由表被多组分层了,这里fz_hash就是根据fz_divisor大小来创建的;fz_order就是子网掩码长度;fz_mask就是子网掩码。
1 2 3 4 | |
从子网长度大于新添加fz的fn_zone中挑选一个不为空的fn_zones[i],将新创建的fz设成fn_zones[i].next;然后将fz根据掩码长度添加到fn_zones[]中相应位置;fn_zone_list始终指向掩码长度最长的fn_zone。
1 2 3 4 5 6 7 8 9 10 11 | |
这里的fn_hash是数组与链表的结合体,看下fn_hash定义
1 2 3 4 | |
fn_hash包含33数组元素,每个元素存放一定掩码长度的fn_zone,其中fn_zone[i]存储掩码长度为i。而fn_zone通过内部属性fz_next又彼此串连起来,形成单向链表,其中fn_zone_list可以看作链表头,而这里链表的组织顺序是倒序的,即从掩码长到短。
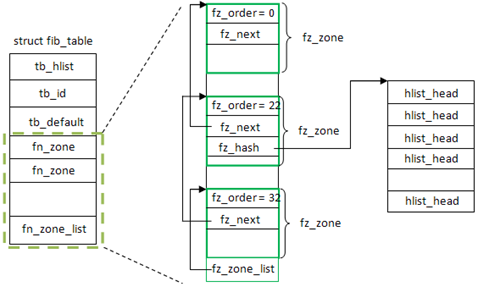
到这里,fz_hash所分配的哈希表还没有插入内容,这部分为fib_insert_node()完成。
inet_rtm_newroute() -> fib_table_insert() -> fib_insert_node() [net/ipv4/fib_hash.c]
这里f是fib_node,可以理解为具有相同网络地址的路由项集合。根据fn_key(网络地址)和fz(掩码长度)来计算hash值,决定将f插入fz_hash的哪个项。
1 2 | |
如何fib_node还不存在,则会创建它,这里的kmem_cache_zalloc()其实就是内存分配
1 2 3 4 5 6 7 | |
路由表最后一层是fib_info,具体的路由信息都存储在此,它由fib_create_info()创建。
首先为fib_info分配空间,由于fib_info的最后一个属性是struct fib_nh fib_nh[0],因此大小是fib_info + nhs * fib_nh,这里的fib_nh代表了下一跳(next hop)的信息,nhs代表了下一跳的数目,一般情况下nhs=1,除非配置了支持多路径。
1
| |
设置fi的相关属性
1 2 3 4 5 6 | |
使fi后面所有的nh->nh_parent指向fi,设置后如图所示
1 2 3 | |
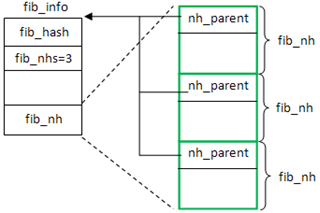
设置fib_nh的属性,这里仅展示了单一路径的情况:
1 2 3 4 | |
然后,再根据cfg->fc_scope值来设置nh的其余属性。如果scope是RT_SCOPE_HOST,则设置下一跳scope为RT_SCOPE_NOWHERE
1 2 3 4 5 | |
如果scope是RT_SCOPE_LINK或RT_SCOPE_UNIVERSE,则设置下跳
1 2 3 4 | |
最后,将fi链入链表中,这里要注意的是所有的fib_info(只要创建了的)都会加入fib_info_hash中,如果路由项使用了优先地址属性,还会加入fib_info_laddrhash中。
1 2 3 4 5 6 7 8 | |
无论fib_info在路由表中位于哪个掩码、哪个网段结构下,都与fib_info_hash和fib_info_laddrhash无关,这两个哈希表与路由表独立,主要是用于加速路由信息fib_info的查找。哈希表的大小为fib_hash_size,当超过这个限制时,fib_hash_size * 2(如果哈希函数够好,每个bucket都有一个fib_info)。fib_info在哈希表的图示如下:
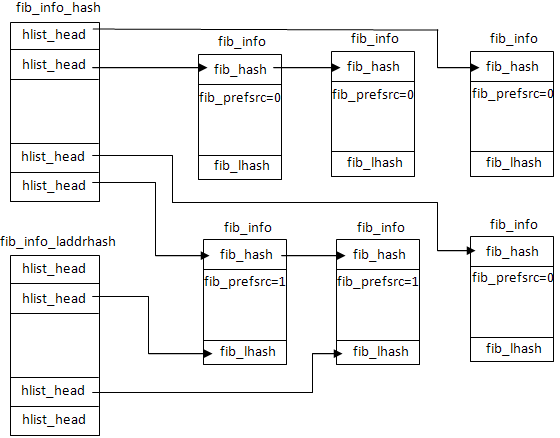
由于路由表信息也可能要以设备dev为键值搜索,因此还存在fib_info_devhash哈希表,用于存储nh的设置dev->ifindex。
1 2 3 4 5 | |
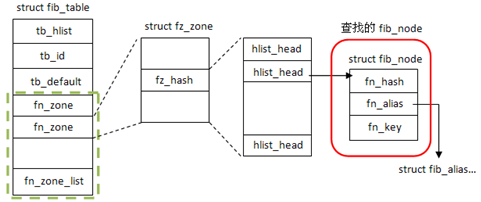
上面讲过了路由表各个部分的创建,现在来看下它们是如何一起工作的,在fib_table_insert()[net/ipv4/fib_hash.c]完成整个的路由表创建过程。下面来看下fib_table_insert()函数:
从fn_zones中取出掩码长度为fc_dst_len的项,如果该项不存在,则创建它[fn_zone的创建前面已经讲过]。
1 2 3 | |
然后创建fib_info结构,[前面已经讲过]
1
| |
然后在掩码长度相同项里查找指定网络地址key(如145.222.33.0/24),查找的结果如图所示
1
| |
如果不存在该网络地址项,则创建相应的fib_node,并加入到链表fz_hash中
1 2 3 4 5 6 7 8 9 10 11 12 | |
如果存在该网络地址项,则在fib_node的属性fn_alias中以tos和fi->fib_priority作为键值查找。一个fib_node可以有多个fib_alias相对应,这些fib_alias以链表形式存在,并按tos并从大到小的顺序排列。因此,fib_find_alias查找到的是第一个fib_alias->tos不大于tos的fib_alias项。
1
| |
如果查找到的fa与与要插入的路由项完全相同,则按照设置的标置位进行操作,NLM_F_REPLACE则替换掉旧的,NLM_F_APPEND添加在后面。
设置要插入的fib_alias的属性,包括最重要的fib_alias->fa_info设置为fi
1 2 3 4 5 | |
如果没有要插入路由的网络地址项fib_node,则之前已经创建了新的,现在将它插入到路由表中fib_insert_node();然后将new_fa链入到fib_node->fn_alias中
1 2 3 4 5 | |
最后,由于新插入的路由表项,会发出通告,告知所以加入RTNLGRP_IPV4_ROUTE组的成员,这个功能可以在linux中使用”ip route monitor”来测试。最终的路由表如图所示:
1
| |
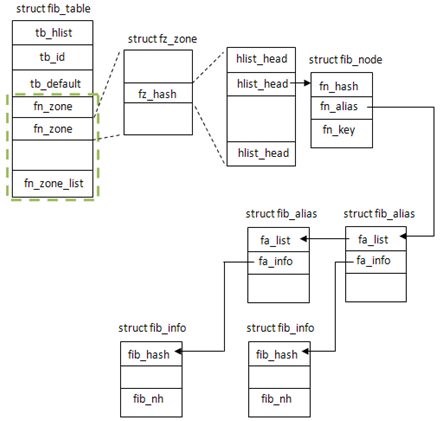
至此,就完成了路由表项的插入,加上之前的路由表的初始化,整个路由表的创建过程就讲解完了,小小总结一下:
路由表的查找效率是第一位的,因此内核在实现时使用了多级索引来进行加速
第一级:fn_zone 按不同掩码长度分类(如/5和/24)
第二级:fib_node 按不同网络地址分类(如124.44.33.0/24)
第三级:fib_info 下一跳路由信息
路由可以分为两部分:路由缓存(rt_hash_table)和路由表()
路由缓存顾名思义就是加速路由查找的,路由缓存的插入是由内核控制的,而非人为的插入,与之相对比的是路由表是人为插入的,而非内核插入的。在内核中,路由缓存组织成rt_hash_table的结构。
下面是一段IP层协议的代码段[net/ipv4/route.c],传入IP层的协议在查找路由时先在路由缓存中查找,如果已存在,则skb_dst_set(skb, &rth->u.dst)并返回;否则在路由表中查询。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
在ip_route_input()中查询完陆由缓存后会处理组播地址,如果是组播地址,则下面判断会成功:ipv4_is_multicast(daddr)。
然后执行ip_route_input_mc(),它的主要作用就是生成路由缓存项rth,并插入缓存。rth的生成与初始化只给出了input函数的,其它略去了,可以看出组播报文会通过ip_local_deliver()继续向上传递。
1 2 3 | |
路由表又可以分为两个:RT_TABLE_LOCAL和RT_TABLE_MAIN
RT_TABLE_LOCAL存储目的地址是本机的路由表项,这些目的地址就是为各个网卡配置的IP地址;
RT_TABLE_MAIN存储到其它主机的路由表项;
显然,RT_TABLE_MAIN路由表只有当主机作为路由器时才有作用,一般主机该表是空的,因为主机不具有转发数据包的功能。RT_TABLE_LOCAL对主机就足够了,为各个网卡配置的IP地址都会加入RT_TABLE_LOCAL中,如为eth1配置了1.2.3.4的地址,则RT_TABLE_LOCAL中会存在1.2.3.4的路由项。只有本地的网卡地址会被加入,比如lo、eth1。IP模块在初始化时ip_init() -> ip_rt_init() - > ip_fib_init()会注册notifier机制,当为网卡地址配置时会执行fib_netdev_notifier和fib_inetaddr_notifier,使更改反映到RT_TABLE_LOCAL中。
1 2 | |
而当在路由缓存中没有查找到缓存项时,会进行路由表查询,还是以IP层协议中的代码段为例[net/ipv4/route.c],fib_lookup()会在MAIN和LOCAL两张表中进行查找。
1 2 3 4 5 | |
如果主机配置成了支持转发,则无论在路由表中找到与否,都会生成这次查询的一个缓存,包括源IP、目的IP、接收的网卡,插入路由缓存中:
1 2 | |
不同的是,如果在路由表中查询失败,即数据包不是发往本机,也不能被本机转发,则会设置插入路由缓存的缓存项u.dst.input=ip_error,而u.dst.input即为IP层处理完后向上传递的函数,而ip_error()会丢弃数据包,被发送相应的ICMP错误报文。不在路由表中的路由项也要插入路由缓存,这可以看作路由学习功能,下次就可以直接在路由缓存中找到。
1 2 3 | |
但如果主机不支持转发,即没有路由功能,则只有在找到时才会添加路由缓存项,都不会生成路由缓存项。这是因为在LOCAL表中没有找到,表明数据包不是发往本机的,此时缓存这样的路由项对于主机的数据包传输没有一点意义。它只需要知道哪些数据包是发给它的,其余的一律不管!
路由查询整合起来,就是由ip_route_input()引入,然后依次进行路由缓存和路由表查询,并对路由缓存进行更新。路由缓存在每个数据包到来时都可能发生更新,但路由表则不一样,只能通过RTM机制更新,LOCAL表是在网卡配置时更新的,MAIN表则是由人工插入的(inet_rtm_newroute)。
ip_route_input()
- 路由缓存查询
- 路由表查询:ip_route_input_slow() -> fib_lookup()
这次将以更实际的例子来分析过程中路由表的使用情况,注意下文都是对路由缓存表的描述,因为路由表在配置完网卡地址后就不会再改变了(除非人为的去改动),测试环境如下图:

两台主机Host1与Host2,分别配置了IP地址192.168.1.1与192.168.1.2,两台主机间用网线直连。在两台主机上分别执行如下操作:
1. 在Host1上ping主机Host2
2. 在Host2上ping主机Host1
很简单常的两台主机互ping的例子,下面来分析这过程中路由表的变化,准备说是路由缓存的变化。首先,路由缓存会存在几个条目?答案不是2条而是3条,这点很关键,具体可以通过/proc/net/rt_cache来查看路由缓存表,下图是执行上述操作后得到的结果:

brcm0.1是Host主机上的网卡设备,等同于常用的eth0,lo是环路设备。对结果稍加分析,可以发现,条目1和条目2是完全一样的,除了计数的Use稍有差别,存在这种情况的原因是缓存表是以Hash表的形式存储的,尽管两者内容相同,在实际插入时使用的键值是不同的,下面以Host2主机的路由缓存表为视角,针对互ping的过程进行逐一分析。
假设brcm0.1设备的index = 2
步骤0:初始时陆由缓存为空
步骤1:主机Host1 ping 主机Host2
Host2收到来自Host1的echo报文(dst = 192.168.1.2, src = 192.168.1.1)
在报文进入IP层后会查询路由表,以确定报文的接收方式,相应调用流程:
ip_route_input() -> ip_route_input_slow()
在ip_route_input()中查询路由缓存,使用的键值是[192.168.1.2, 192.168.1.1, 2, id],由于缓存表为空,查询失败,继续走ip_route_input_slow()来创建并插入新的缓存项。
1
| |
在ip_route_input_slow()中查询路由表,因为发往本机,在会LOCAL表中匹配192.168.1.2条目,查询结果res.type==RTN_LOCAL。
1 2 3 4 5 | |
然后根据res.type跳转到local_input代码段,创建新的路由缓存项,并插入陆由缓存。
1 2 3 4 5 6 7 8 9 10 | |
因此插入的第一条缓存信息如下:
1 2 | |
步骤2:
主机Host2 发送echo reply报文给主机 Host1 (dst = 192.168.1.1 src = 192.168.1.2)
步骤2是紧接着步骤1的,Host2在收到echo报文后会立即回复echo reply报文,相应调用流程:
icmp_reply() -> ip_route_output_key() -> ip_route_output_flow() -> ip_route_output_key() -> ip_route_output_slow() -> ip_mkroute_output() -> mkroute_output()
在icmp_reply()中生成稍后路由查找中的关键数据flowi,可以看作查找的键值,由于是回复已收到的报文,因此目的与源IP地址者是已知的,下面结构中daddr=192.168.1.1,saddr=192.168.1.2。
1 2 3 4 5 | |
在__ip_route_output_key()时会查询路由缓存表,查询的键值是[192.168.1.1, 192.168.1.2, 0, id],由于此时路由缓存中只有一条刚刚插入的从192.168.1.1->192.168.1.2的缓存项,因而查询失败,继续走ip_route_output_slow()来创建并插入新的缓存项。
1
| |
在ip_route_input_slow()中查询路由表,因为在同一网段,在会MAIN表中匹配192.168.1.0/24条目,查询结果res.type==RTN_UNICAST。
1 2 3 | |
然后调用__mkroute_output()来生成新的路由缓存,信息如下:
1 2 3 4 5 6 | |
插入路由缓存表时使用的键值是:
1
| |
这条语句很关键,缓存的存储形式是hash表,除了生成缓存信息外,还要有相应的键值,这句的hash就是产生的键值,可以看到,它是由(dst, src, oif, id)四元组生成的,dst和src很好理解,id对于net来说是定值,oif则是关键,注意这里用的是oldflp->oif(它的值为0),尽管路由缓存对应的出接口设备是dev_out。所以,第二条缓存信息的如下:
1 2 | |
步骤3:
主机Host2 ping 主机Host1
Host2向Host1发送echo报文(dst = 192.168.1.1, src = 192.168.1.2)
Host2主动发送echo报文,使用SOCK_RAW与IPPROTO_ICMP组合的套接字,相应调用流程:
raw_sendmsg() -> ip_route_output_flow() -> ip_route_output_key() -> ip_route_output_slow() -> ip_mkroute_output() -> mkroute_output()
在raw_sendmsg()中生成稍后路由查找中的关键数据flowi,可以看作查找的键值,由于是主动发送的报文,源IP地址者还是未知的,因为主机可能是多接口的,在查询完路由表后才能得到要走的设备接口和相应的源IP地址。下面结构中daddr=192.168.1.1,saddr=0。
1 2 3 4 5 6 7 8 9 | |
在__ip_route_output_key()时会查询路由缓存表,查询的键值是[192.168.1.1, 0, 0, id],尽管此时路由缓存中刚刚插入了192.168.1.2->192.168.1.1的条目,但由于两者的键值不同,因而查询依旧失败,继续走ip_route_output_slow()来创建并插入新的缓存项。
1
| |
与Host2回复Host1的echo报文相比,除了进入函数不同(前者为icmp_reply,后者为raw_sendmsg),后续调用流程是完全相同的,导致最终路由缓存不同(准确说是键值)是因为初始时flowi不同。
此处,raw_sendmsg()中,flowi的初始值:dst = 192.168.1.1, src = 0, oif = 0
对比icmp_reply()中,flowi的初始值:dst = 192.168.1.1, src = 192.168.1.2, oif = 0
在上述调用流程中,在__ip_route_output_key()中查找路由缓存,尽管此时路由缓存有从192.168.1.2到192.168.1.1的缓存项,但它的键值与此次查找的键值[192.168.1.1, 192.168.1.2, 0],从下表可以明显看出:
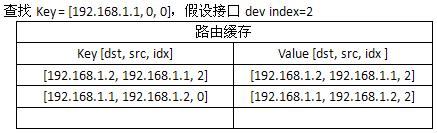
由于查找失败,生成新的路由缓存项并插入路由缓存表,注意在ip_route_output_slow()中查找完路由表后,设置了缓存的src。
1 2 | |
因此插入的第三条缓存信息如下,它与第二条缓存完成相同,区别在于键值不同:
1 2 | |
最终,路由缓存表如下:
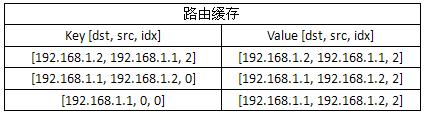
第三条缓存条目键值使用src=0, idx=0的原因是当主机要发送报文给192.168.1.1的主机时,直到IP层路由查询前,它都无法知道该使用的接口地址(如果没有绑定的话),而路由缓存的查找发生在路由查询之前,所以src=0,idx=0才能保证后续报文使用该条目。