

http://blog.csdn.net/vanbreaker/article/details/7855007
在32位的系统上,线性地址空间可达到4GB,这4GB一般按照3:1的比例进行分配,也就是说用户进程享有前3GB线性地址空间,而内核独享最后1GB线性地址空间。由于虚拟内存的引入,每个进程都可拥有3GB的虚拟内存,并且用户进程之间的地址空间是互不可见、互不影响的,也就是说即使两个进程对同一个地址进行操作,也不会产生问题。在前面介绍的一些分配内存的途径中,无论是伙伴系统中分配页的函数,还是slab分配器中分配对象的函数,它们都会尽量快速地响应内核的分配请求,将相应的内存提交给内核使用,而内核对待用户空间显然不能如此。用户空间动态申请内存时往往只是获得一块线性地址的使用权,而并没有将这块线性地址区域与实际的物理内存对应上,只有当用户空间真正操作申请的内存时,才会触发一次缺页异常,这时内核才会分配实际的物理内存给用户空间。
用户进程的虚拟地址空间包含了若干区域,这些区域的分布方式是特定于体系结构的,不过所有的方式都包含下列成分:
可执行文件的二进制代码,也就是程序的代码段
存储全局变量的数据段
用于保存局部变量和实现函数调用的栈
环境变量和命令行参数
程序使用的动态库的代码
用于映射文件内容的区域
由此可以看到进程的虚拟内存空间会被分成不同的若干区域,每个区域都有其相关的属性和用途,一个合法的地址总是落在某个区域当中的,这些区域也不会重叠。在linux内核中,这样的区域被称之为虚拟内存区域(virtual memory areas),简称vma。一个vma就是一块连续的线性地址空间的抽象,它拥有自身的权限(可读,可写,可执行等等) ,每一个虚拟内存区域都由一个相关的struct vm_area_struct结构来描述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | |
进程的若干个vma区域都得按一定的形式组织在一起,这些vma都包含在进程的内存描述符中,也就是struct mm_struct中,这些vma在mm_struct以两种方式进行组织,一种是链表方式,对应于mm_struct中的mmap链表头,一种是红黑树方式,对应于mm_struct中的mm_rb根节点,和内核其他地方一样,链表用于遍历,红黑树用于查找。
下面以文件映射为例,来阐述文件的address_space和与其建立映射关系的vma是如何联系上的。首先来看看struct address_space中与vma相关的变量
1 2 3 4 5 6 7 | |
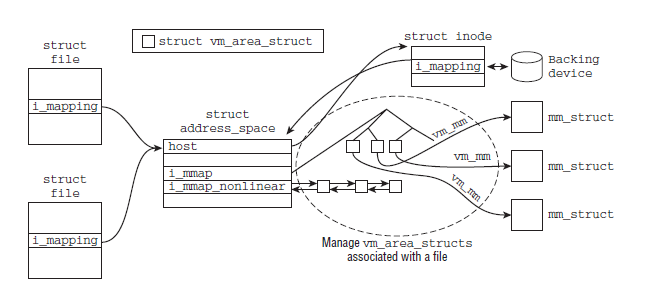
与此同时,struct file和struct inode中都包含有一个struct address_space的指针,分别为f_mapping和i_mapping。struct file是一个特定于进程的数据结构,而struct inode则是一个特定于文件的数据结构。每当进程打开一个文件时,都会将file->f_mapping设置到inode->i_mapping,下图则给出了文件和与其建立映射关系的vma的联系
下面来看几个vma的基本操作函数,这些函数都是后面实现具体功能的基础
find_vma()用来寻找一个针对于指定地址的vma,该vma要么包含了指定的地址,要么位于该地址之后并且离该地址最近,或者说寻找第一个满足addr<vma_end的vma
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
当一个新区域被加到进程的地址空间时,内核会检查它是否可以与一个或多个现存区域合并,vma_merge()函数在可能的情况下,将一个新区域与周边区域进行合并。参数:
mm:新区域所属的进程地址空间
prev:在地址上紧接着新区域的前面一个vma
addr:新区域的起始地址
end:新区域的结束地址
vm_flags:新区域的标识集
anon_vma:新区域所属的匿名映射
file:新区域映射的文件
pgoff:新区域映射文件的偏移
policy:和NUMA相关
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | |
vma_adjust会执行具体的合并调整操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 | |
insert_vm_struct()函数用于插入一块新区域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
在创建新的vma区域之前先要寻找一块足够大小的空闲区域,该项工作由get_unmapped_area()函数完成,而实际的工作将会由mm_struct中定义的辅助函数来完成。根据进程虚拟地址空间的布局,会选择使用不同的映射函数,在这里考虑大多数系统上采用的标准函数arch_get_unmapped_area();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | |