

1 Linux 中的进程与线程
对于 Linux 来讲,所有的线程都当作进程来实现,因为没有单独为线程定义特定的调度算法,也没有单独为线程定义特定的数据结构(所有的线程或进程的核心数据结构都是 task_struct)。
对于一个进程,相当于是它含有一个线程,就是它自身。对于多线程来说,原本的进程称为主线程,它们在一起组成一个线程组。
进程拥有自己的地址空间,所以每个进程都有自己的页表。而线程却没有,只能和其它线程共享某一个地址空间和同一份页表。
这个区别的 根本原因 是,在进程/线程创建时,因是否拷贝当前进程的地址空间还是共享当前进程的地址空间,而使得指定的参数不同而导致的。
具体地说,进程和线程的创建都是执行 clone 系统调用进行的。而 clone 系统调用会执行 do_fork 内核函数,而它则又会调用 copy_process 内核函数来完成。主要包括如下操作:
在调用 copy_process 的过程中,会创建并拷贝当前进程的 task_stuct,同时还会创建属于子进程的 thread_info 结构以及内核栈。
此后,会为创建好的 task_stuct 指定一个新的 pid(在 task_struct 结构体中)。
然后根据传递给 clone 的参数标志,来选择拷贝还是共享打开的文件,文件系统信息,信号处理函数,进程地址空间等。这就是进程和线程不一样地方的本质所在。
2 三个数据结构
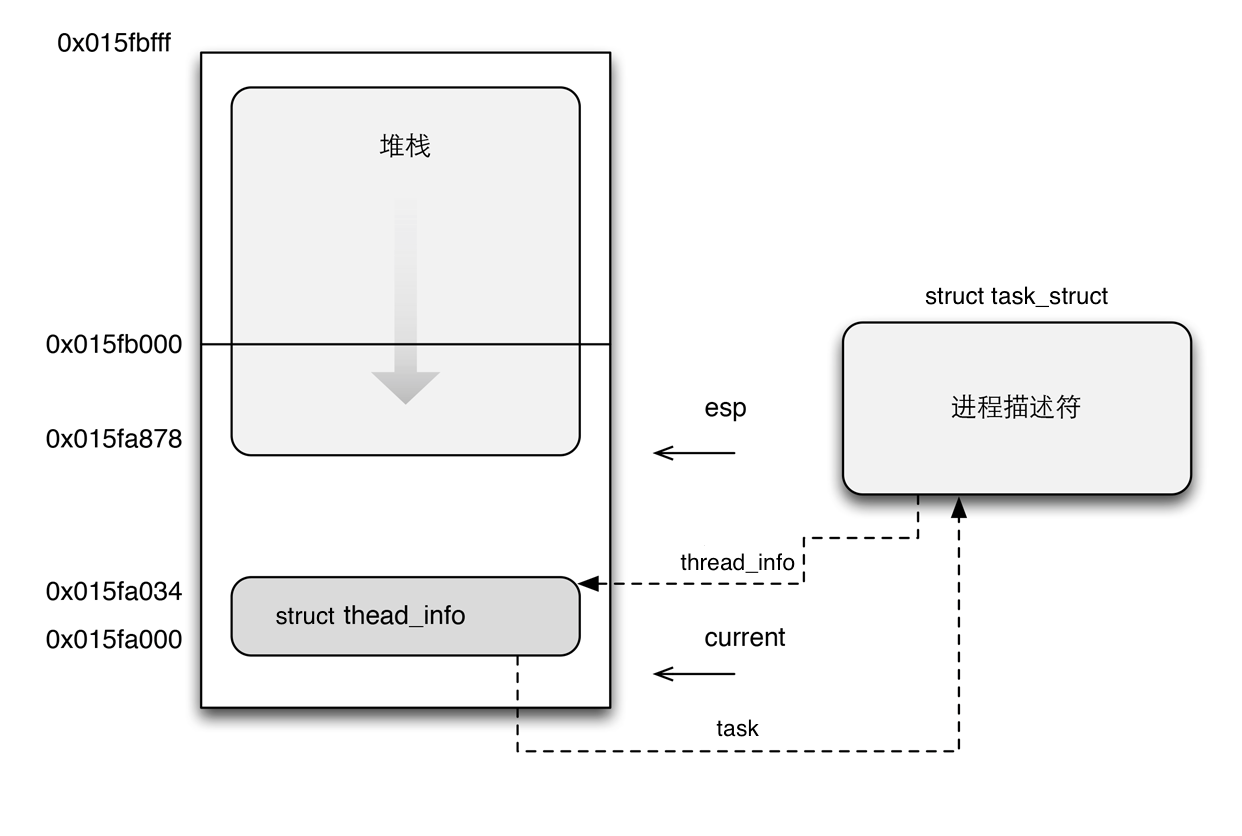
每个进程或线程都有三个数据结构,分别是 struct thread_info, struct task_struct 和 内核栈。
注意,虽然线程与主线程共享地址空间,但是线程也是有自己独立的内核栈的。
thread_info 对象中存放的进程/线程的基本信息,它和这个进程/线程的内核栈存放在内核空间里的一段 2 倍页长的空间中。其中 thread_info 结构存放在低地址段的末尾,其余空间用作内核栈。内核使用 伙伴系统 为每个进程/线程分配这块空间。
thread_info 结构体中有一个 struct task_struct *task,task 指向的就是这个进程或线程相关的 task_struct 对象(也在内核空间中),这个对象叫做进程描述符(叫做任务描述符更为贴切,因为每个线程也都有自己的 task_struct)。内核使用 slab 分配器为每个进程/线程分配这块空间。
如下图所示:
3 task_struct 结构体
每个进程或线程都有只属于自己的 task_struct 对象,是它们各自最为核心的数据结构。
3.1 task_struct 结构体中的主要元素
1 2 3 4 5 6 | |
3.2 task_struct 结构体中的三个 ID 与一个指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
4 虚拟内存地址空间
4.1 内存管理
内存是由内核来管理的。
内存被分为 n 个页框,然后进一步组织为多个区。而装入页框中的内容称为页。
当内核函数申请内存时,内核总是立即满足(因为内核完全信任它们,所以优先级最高)。在分配适当内存空间后,将其映射到内核地址空间中(3-4GB 中的某部分空间),然后将地址映射写入页表。
申请内存空间的内核函数有 vmalloc, kmalloc, alloc_pages, __get_free_pages 等。
4.2 内核常驻内存
就是说,内核地址空间(3-4GB)中的页面所映射的页框始终在物理内存中存在,不会被换出。即使是 vmalloc 动态申请的页面也会一直在物理内存中,直至通过相关内核函数释放掉。
其原因在于,一方面内核文件不是太大,完全可以一次性装入物理内存;另一方面在于即使是动态申请内存空间,也能立即得到满足。
因此,处于内核态的普通进程或内核线程(后面会提到)不会因为页面没有在内存中而产生缺页异常(不过处于内核态的普通进程会因为页表项没有同步的原因而产生缺页异常)。
4.3 为什么要有虚拟地址空间
普通进程在申请内存空间时会被内核认为是不紧要的,优先级较低。因而总是延迟处理,在之后的某个时候才会真正为其分配物理内存空间。
比如,普通进程中的 malloc 函数在申请物理内存空间时,内核不会直接为其分配页框。
另一方面,普通进程对应的可执行程序文件较大,不能够立即装入内存,而是采取运行时按需装入。
要实现这种延迟分配策略,就需要引入一种新的地址空间,即 虚拟地址空间。可执行文件在装入时或者进程在执行 malloc 时,内核只会为其分配适当大小的虚拟地址空间。
虚拟地址空间并不单纯地指线性地址空间。准确地说,指的是页面不能因为立即装入物理内存而采取折衷处理后拥有的线性地址空间。 因此,虽然普通进程的虚拟地址空间为 4GB,但是从内核的角度来说,内核地址空间(也是线性空间)不能称为虚拟地址空间,内核线程不拥有也不需要虚拟地址空间。 因此,虚拟地址空间只针对普通进程。
当然,这样的话就会产生所要访问的页面不在物理内存中而发生缺页异常。
4.4 虚拟地址空间的划分
每一个普通进程都拥有 4GB 的虚拟地址空间(对于 32 位的 CPU 来说,即 232 B)。
主要分为两部分,一部分是用户空间(0-3GB),一部分是内核空间(3-4GB)。每个普通进程都有自己的用户空间,但是内核空间被所有普通进程所共享。
如下图所示:
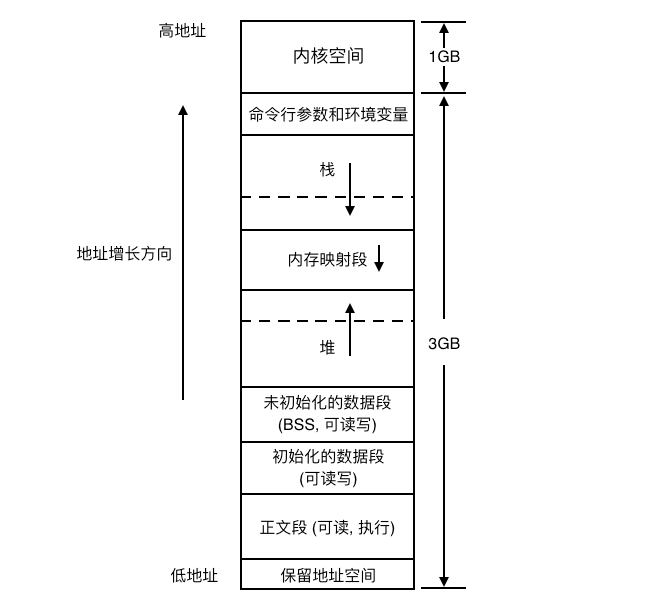
之所以能够使用 3-4GB 的虚拟地址空间(对于普通进程来说),是因为每个进程的页全局目录(后面会提到)中的后面部分存放的是内核页全局目录的所有表项。当通过系统调用或者发生异常而陷入内核时,不会切换进程的页表。此时,处于内核态的普通进程将会直接使用进程页表中前面的页表项即可。这也是为什么在执行系统调用或者处理异常时没有发生进程的上下文切换的真实原因。 同样,正因为每个进程的也全局目录中的后面部分存放的是内核页全局目录中的所有表项,所以所有普通进程共享内核空间。
另外,
用户态下的普通进程只能访问 0-3GB 的用户空间; 内核态下的普通进程既能访问 0-3GB 的用户空间,也能访问 3-4GB 的内核空间(内核态下的普通进程有时也会需要访问用户空间)。
4.5 普通线程的用户堆栈与寄存器
对于多线程环境,虽然所有线程都共享同一片虚拟地址空间,但是每个线程都有自己的用户栈空间和寄存器,而用户堆仍然是所有线程共享的。
栈空间的使用是有明确限制的,栈中相邻的任意两条数据在地址上都是连续的。试想,假设多个普通线程函数都在执行递归操作。如果多个线程共有用户栈空间,由于线程是异步执行的,那么某个线程从栈中取出数据时,这条数据就很有可能是其它线程之前压入的,这就导致了冲突。所以,每个线程都应该有自己的用户栈空间。
寄存器也是如此,如果共用寄存器,很可能出现使用混乱的现象。
而堆空间的使用则并没有这样明确的限制,某个线程在申请堆空间时,内核只要从堆空间中分配一块大小合适的空间给线程就行了。所以,多个线程同时执行时不会出现向栈那样产生冲突的情况,因而线程组中的所有线程共享用户堆。
那么在创建线程时,内核是怎样为每个线程分配栈空间的呢?
由之前所讲解可知,进程/线程的创建主要是由 clone 系统调用完成的。而 clone 系统调用的参数中有一个 void *child_stack,它就是用来指向所创建的进程/线程的堆栈指针。
而在该进程/线程在用户态下是通过调用 pthread_create 库函数而陷入内核的。对于 pthread_create 函数,它则会调用一个名为 pthread_allocate_stack 的函数,专门用来为所创建的线程分配的栈空间(通过 mmap 系统调用)。然后再将这个栈空间的地址传递给 clone 系统调用。这也是为什么线程组中的每个线程都有自己的栈空间。
4.6 普通进程的页表
有两种页表,一种是内核页表(会在后面说明),另一种是进程页表。
普通进程使用的则是进程页表,而且每个普通进程都有自己的进程页表。如果是多线程,则这些线程共享的是主线程的进程页表。
4.6.1 四级页表
现在的 Linux 内核中采用四级页表,分别为:
1 2 3 4 | |
task_struct 中的 mm_struct 对象用于管理该进程(或者线程共享的)页表。准确地说,mm_struct 中的 pgd 指针指向着该进程的页全局目录。
4.6.2 普通进程的页全局目录
普通进程的页全局目录中,第一部分表项映射的线性地址为 0-3GB 部分,剩余部分存放的是主内核页全局目录(后面会提到)中的所有表项。
5 内核线程
内核线程是一种只运行在内核地址空间的线程。所有的内核线程共享内核地址空间(对于 32 位系统来说,就是 3-4GB 的虚拟地址空间),所以也共享同一份内核页表。这也是为什么叫内核线程,而不叫内核进程的原因。
由于内核线程只运行在内核地址空间中,只会访问 3-4GB 的内核地址空间,不存在虚拟地址空间,因此每个内核线程的 task_struct 对象中的 mm 为 NULL。
普通线程虽然也是同主线程共享地址空间,但是它的 task_struct 对象中的 mm 不为空,指向的是主线程的 mm_struct 对象。
普通进程与内核线程有如下区别:
内核线程只运行在内核态,而普通进程既可以运行在内核态,也可以运行在用户态;
内核线程只使用 3-4GB (假设为 32 位系统) 的内核地址空间(共享的),但普通进程由于既可以运行在用户态,又可以运行在内核态,因此可以使用 4GB 的虚拟地址空间。
系统在正式启动内核时,会执行 start_kernel 函数。在这个函数中,会自动创建一个进程,名为 init_task。其 PID 为 0,运行在内核态中。然后开始执行一系列初始化。
5.1 init 内核线程
init_task 在执行 rest_init 函数时,会执行 kernel_thread 创建 init 内核线程。它的 PID 为 1,用来完成内核空间初始化。
在内核空间完成初始化后,会调用 exceve 执行 init 可执行程序 (/sbin/init)。之后,init 内核线程变成了一个普通的进程,运行在用户空间中。
init 内核线程没有地址空间,且它的 task_struct 对象中的 mm 为 NULL。因此,执行 exceve 会使这个 mm 指向一个 mm_struct,而不会影响到 init_task 进程的地址空间。 也正因为此,init 在转变为进程后,其 PID 没变,仍为 1。
创建完 init 内核线程后,init_task 进程演变为 idle 进程(PID 仍为 0)。
之后,init 进程再根据再启动其它系统进程 (/etc/init.d 目录下的各个可执行文件)。
5.2 kthreadd 内核线程
init_task 进程演变为 idle 进程后,idle 进程会执行 kernel_thread 来创建 kthreadd 内核线程(仍然在 rest_init 函数中)。它的 PID 为 2,用来创建并管理其它内核线程(用 kthread_create, kthread_run, kthread_stop 等内核函数)。
系统中有很多内核守护进程 (线程),可以通过:
1
| |
进行查看,其中带有 [] 号的就属于内核守护进程。它们的祖先都是这个 kthreadd 内核线程。
5.3 主内核页全局目录
内核维持着一组自己使用的页表,也即主内核页全局目录。当内核在初始化完成后,其存放在 swapper_pg_dir 中,而且所有的普通进程和内核线程就不再使用它了。
5.4 内核线程如何访问页表
5.4.1 active_mm
对于内核线程,虽然它的 task_struct 中的 mm 为 NULL,但是它仍然需要访问内核空间,因此需要知道关于内核空间映射到物理内存的页表。然而不再使用 swapper_pg_dir,因此只能另外想法解决。
由于所有的普通进程的页全局目录中的后面部分为主内核页全局目录,因此内核线程只需要使用某个普通进程的页全局目录就可以了。
在 Linux 中,task_struct 中还有一个很重要的元素为 active_mm,它主要就是用于内核线程访问主内核页全局目录。
对于普通进程来说,task_struct 中的 mm 和 active_mm 指向的是同一片区域; 然而对内核线程来说,task_struct 中的 mm 为 NULL,active_mm 指向的是前一个普通进程的 mm_struct 对象。
5.4.2 mm_users 和 mm_count
但是这样还是不行,因为如果因为前一个普通进程退出了而导致它的 mm_struct 对象也被释放了,则内核线程就访问不到了。
为此,mm_struct 对象维护了一个计数器 mm_count,专门用来对引用这个 mm_struct 对象的自身及内核线程进行计数。初始时为 1,表示普通进程本身引用了它自己的 mm_struct 对象。只有当这个引用计数为 0 时,才会真正释放这个 mm_struct 对象。
另外,mm_struct 中还定义了一个 mm_users 计数器,它主要是用来对共享地址空间的线程计数。事实上,就是这个主线程所在线程组中线程的总个数。初始时为 1。
注意,两者在实质上都是针对引用 mm_struct 对象而设置的计数器。 不同的是,mm_count 是专门针对自身及内核线程或引用 mm_struct 而进行计数;而 mm_users 是专门针对该普通线程所在线程组的所有普通线程而进行计数。 另外,只有当 mm_count 为 0 时,才会释放 mm_struct 对象,并不会因为 mm_users 为 0 就进行释放。