

https://blog.csdn.net/lishenglong666/article/details/45536611
poll/select/epoll的实现都是基于文件提供的poll方法(f_op->poll), 该方法利用poll_table提供的qproc方法向文件内部事件掩码key对应的的一个或多个等待队列(wait_queue_head_t)上添加包含唤醒函数(wait_queue_t.func)的节点(wait_queue_t),并检查文件当前就绪的状态返回给poll的调用者(依赖于文件的实现)。 当文件的状态发生改变时(例如网络数据包到达),文件就会遍历事件对应的等待队列并调用回调函数(wait_queue_t.func)唤醒等待线程。
通常的file.f_ops.poll实现及相关结构体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
poll 和 select
poll和select的实现基本上是一致的,只是传递参数有所不同,他们的基本流程如下:
复制用户数据到内核空间
估计超时时间
遍历每个文件并调用f_op->poll 取得文件当前就绪状态, 如果前面遍历的文件都没有就绪,向文件插入wait_queue节点
遍历完成后检查状态:
a). 如果已经有就绪的文件转到5;
b). 如果有信号产生,重启poll或select(转到 1或3);
c). 否则挂起进程等待超时或唤醒,超时或被唤醒后再次遍历所有文件取得每个文件的就绪状态
将所有文件的就绪状态复制到用户空间
清理申请的资源
关键结构体
下面是poll/select共用的结构体及其相关功能:
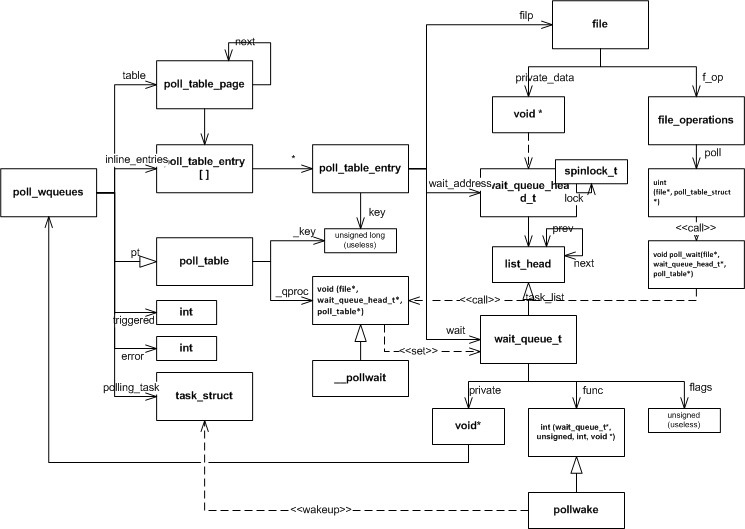
poll_wqueues 是 select/poll 对poll_table接口的具体化实现,其中的table, inline_index和inline_entries都是为了管理内存。 poll_table_entry 与一个文件相关联,用于管理插入到文件的wait_queue节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
公共函数
下面是poll/select公用的一些函数,这些函数实现了poll和select的核心功能。
poll_initwait 用于初始化poll_wqueues,
__pollwait 实现了向文件中添加回调节点的逻辑,
pollwake 当文件状态发生改变时,由文件调用,用来唤醒线程,
poll_get_entry,free_poll_entry,poll_freewait用来申请释放poll_table_entry 占用的内存,并负责释放文件上的wait_queue节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | |
poll,select对poll_table_entry的申请和释放采用的是类似内存池的管理方式,先使用预分配的空间,预分配的空间不足时,分配一个内存页,使用内存页上的空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
poll/select核心结构关系
下图是 poll/select 实现公共部分的关系图,包含了与文件直接的关系,以及函数之间的依赖。
poll的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 | |
select 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 | |
epoll实现
epoll 的实现比poll/select 复杂一些,这是因为:
- epoll_wait, epoll_ctl 的调用完全独立开来,内核需要锁机制对这些操作进行保护,并且需要持久的维护添加到epoll的文件
- epoll本身也是文件,也可以被poll/select/epoll监视,这可能导致epoll之间循环唤醒的问题
- 单个文件的状态改变可能唤醒过多监听在其上的epoll,产生唤醒风暴
epoll各个功能的实现要非常小心面对这些问题,使得复杂度大大增加。
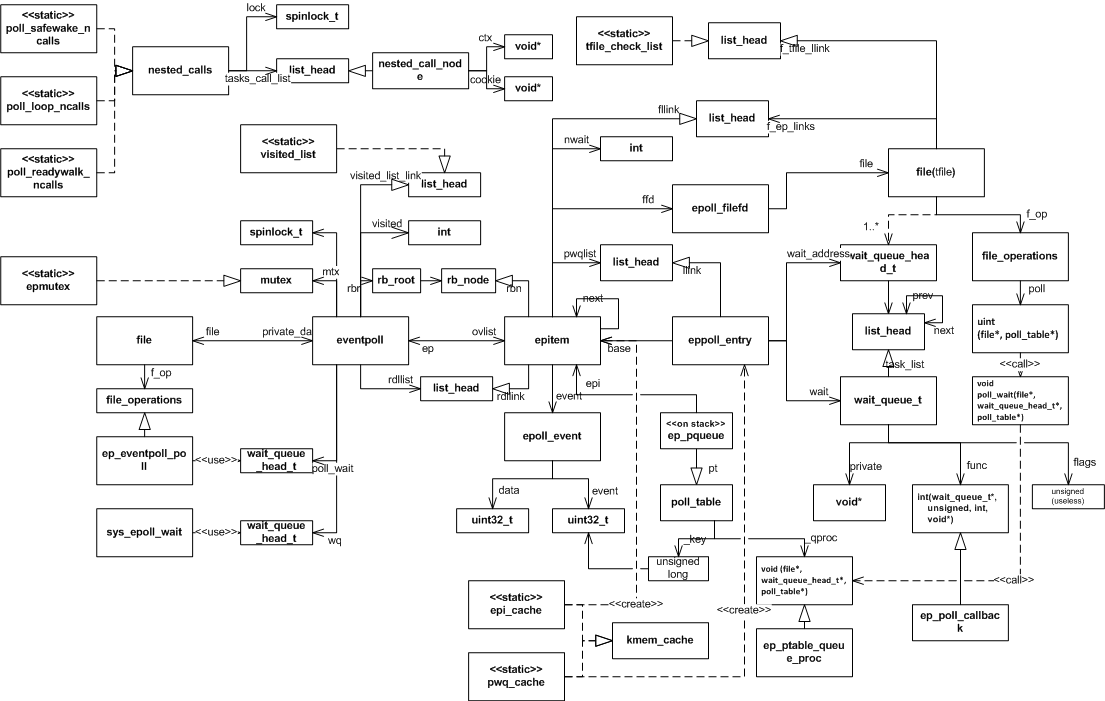
epoll的核心数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | |
文件系统初始化和epoll_create
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | |
epoll中的递归死循环和深度检查
递归深度检测(ep_call_nested)
epoll本身也是文件,也可以被poll/select/epoll监视,如果epoll之间互相监视就有可能导致死循环。epoll的实现中,所有可能产生递归调用的函数都由函函数ep_call_nested进行包裹,递归调用过程中出现死循环或递归过深就会打破死循环和递归调用直接返回。该函数的实现依赖于一个外部的全局链表nested_call_node(不同的函数调用使用不同的节点),每次调用可能发生递归的函数(nproc)就向链表中添加一个包含当前函数调用上下文ctx(进程,CPU,或epoll文件)和处理的对象标识cookie的节点,通过检测是否有相同的节点就可以知道是否发生了死循环,检查链表中同一上下文包含的节点个数就可以知道递归的深度。以下就是这一过程的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | |
循环检测(ep_loop_check)
循环检查(ep_loop_check),该函数递归调用ep_loop_check_proc利用ep_call_nested来实现epoll之间相互监视的死循环。因为ep_call_nested中已经对死循环和过深的递归做了检查,实际的ep_loop_check_proc的实现只是递归调用自己。其中的visited_list和visited标记完全是为了优化处理速度,如果没有visited_list和visited标记函数也是能够工作的。该函数中得上下文就是当前的进程,cookie就是正在遍历的epoll结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | |
唤醒风暴检测(reverse_path_check)
当文件状态发生改变时,会唤醒监听在其上的epoll文件,而这个epoll文件还可能唤醒其他的epoll文件,这种连续的唤醒就形成了一个唤醒路径,所有的唤醒路径就形成了一个有向图。如果文件对应的epoll唤醒有向图的节点过多,那么文件状态的改变就会唤醒所有的这些epoll(可能会唤醒很多进程,这样的开销是很大的),而实际上一个文件经过少数epoll处理以后就可能从就绪转到未就绪,剩余的epoll虽然认为文件已就绪而实际上经过某些处理后已不可用。epoll的实现中考虑到了此问题,在每次添加新文件到epoll中时,就会首先检查是否会出现这样的唤醒风暴。
该函数的实现逻辑是这样的,递归调用reverse_path_check_proc遍历监听在当前文件上的epoll文件,在reverse_pach_check_proc中统计并检查不同路径深度上epoll的个数,从而避免产生唤醒风暴。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | |
epoll 的唤醒过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
epoll_ctl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 | |
EPOLL_CTL_ADD 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 | |
EPOLL_CTL_DEL
EPOLL_CTL_DEL 的实现调用的是 ep_remove 函数,函数只是清除ADD时, 添加的各种结构,EPOLL_CTL_MOD 的实现调用的是ep_modify,在ep_modify中用新的事件掩码调用f_ops->poll,检测事件是否已可用,如果可用就直接唤醒epoll,这两个的实现与EPOLL_CTL_ADD 类似,代码上比较清晰,这里就不具体分析了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | |
epoll_wait
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 | |
eventpoll_poll
由于epoll自身也是文件系统,其描述符也可以被poll/select/epoll监视,因此需要实现poll方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | |
epoll全景
以下是epoll使用的全部数据结构之间的关系图,采用的是一种类UML图,希望对理解epoll的内部实现有所帮助。
poll/select/epoll 对比
通过以上的分析可以看出,poll和select的实现基本是一致,只是用户到内核传递的数据格式有所不同,
select和poll即使只有一个描述符就绪,也要遍历整个集合。如果集合中活跃的描述符很少,遍历过程的开销就会变得很大,而如果集合中大部分的描述符都是活跃的,遍历过程的开销又可以忽略。
epoll的实现中每次只遍历活跃的描述符(如果是水平触发,也会遍历先前活跃的描述符),在活跃描述符较少的情况下就会很有优势,在代码的分析过程中可以看到epoll的实现过于复杂并且其实现过程中需要同步处理(锁),如果大部分描述符都是活跃的,epoll的效率可能不如select或poll。(参见epoll 和poll的性能测试 http://jacquesmattheij.com/Poll+vs+Epoll+once+again)
select能够处理的最大fd无法超出FDSETSIZE。
select会复写传入的fd_set 指针,而poll对每个fd返回一个掩码,不更改原来的掩码,从而可以对同一个集合多次调用poll,而无需调整。
select对每个文件描述符最多使用3个bit,而poll采用的pollfd需要使用64个bit,epoll采用的 epoll_event则需要96个bit
如果事件需要循环处理select, poll 每一次的处理都要将全部的数据复制到内核,而epoll的实现中,内核将持久维护加入的描述符,减少了内核和用户复制数据的开销。