https://blog.csdn.net/NW_NW_NW/article/details/75045966
https://blog.csdn.net/NW_NW_NW/article/details/75090101
https://blog.csdn.net/NW_NW_NW/article/details/75647220
https://blog.csdn.net/NW_NW_NW/article/details/76022117
https://blog.csdn.net/NW_NW_NW/article/details/76153027
https://blog.csdn.net/NW_NW_NW/article/details/76204707
https://blog.csdn.net/NW_NW_NW/article/details/76674232
https://blog.csdn.net/NW_NW_NW/article/details/76710941
桥初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
static int __init br_init(void)
{
int err;
/*注册协议生成树收包函数*/
err = stp_proto_register(&br_stp_proto);
if (err < 0) {
pr_err("bridge: can't register sap for STP\n");
return err;
}
/*转发数据库初始化*/
err = br_fdb_init();
if (err)
goto err_out;
/*在/proc目录下生成任何与bridge相关的目录,如果我们想在/proc下生成bridge相关的子目录或子文件*/
err = register_pernet_subsys(&br_net_ops);
if (err)
goto err_out1;
/*目前好像没有什么实际作用,在内核中所注册的函数为空*/
err = br_nf_core_init();
if (err)
goto err_out2;
/*注册相关网络设备的事件通知连*/
err = register_netdevice_notifier(&br_device_notifier);
if (err)
goto err_out3;
/*注册通知连,主要针对桥转发表事件的相关信息*/
err = register_switchdev_notifier(&br_switchdev_notifier);
if (err)
goto err_out4;
/*进行netlink的初始化*/
err = br_netlink_init();
if (err)
goto err_out5;
/*用来处理ioctl命令的函数,比如添加和删除网桥*/
brioctl_set(br_ioctl_deviceless_stub);
#if IS_ENABLED(CONFIG_ATM_LANE)
br_fdb_test_addr_hook = br_fdb_test_addr;
#endif
return 0;
}
了解了桥初始化大致要做的事情后,我们再来看看这些初始化或者注册的事情到底干了些什么?
1.注册协议生成树收包函数stp_proto_register
在桥初始化的时候,注册了一个br_stp_proto参数,此参数的具体模样是这样子的
1
2
3
static const struct stp_proto br_stp_proto = {
.rcv = br_stp_rcv,
};
br_stp_rcv函数在/net/bridge/br_stp_bpdu.c中主要针对网桥进行协议交换的帧(BPDU)进行配置操作。
2.桥转发数据库初始化br_fdb_init
此函数就是在内存中建立一块slab cache,以存放net_bridge_fdb_entry
其中:net_bridge_fdb_entry是一个结构体,用来转发数据库的记录项网桥所学到对的每个MAC地址都有这样一个记录
3.在proc目录下生成相关文件的注册函数register_pernet_subsys,初始化的时候给这个函数传递了一个参数br_net_ops,这个参数的模样是这样的
1
2
3
static struct pernet_operations br_net_ops = {
.exit = br_net_exit,
};
但是在桥初始化的时候,仅仅注册了br_net_exit,这个函数会将桥下面的所有文件全部清空。
4.通知链的相关函数注册register_netdevice_notifier这个注册函数主要针对设备信息的变化,注册参数br_device_notifier,具体如下:
1
2
3
static struct notifier_block br_device_notifier = {
.notifier_call = br_device_event
};
br_device_event函数是用来当桥上的设备状态或者设备信息发生改变时做相应的处理,该函数在/net/bridge/br.c中
5.注册通知连,主要针对桥转发表事件的相关信息register_switchdev_notifier,传入的参数br_switchdev_notifier详细信息如下:
1
2
3
static struct notifier_block br_switchdev_notifier = {
.notifier_call = br_switchdev_event,
};
br_switchdev_event,主要针对桥转发表的事件做出相应的处理该函数在/net/bridge/br.c中
6.brioctl_set用来处理ioctl命令的函数,比如添加和删除网桥,br_ioctl_deviceless_stub给回调函数br_ioctl_hook,而br_ioctl_hook在sock_ioctl中
使用,这样通过在应用层调用socket的ioctl函数,就能够进行网桥的添加与删除了,函数用来处理添加和删除网桥的相关操作
以上就是网桥初始化的相关操作。
添加一个桥设备——br_add_bridge
我们先来看一个命令:brctl addbr br1
上节我们提到一个用来处理ioctl命令的函数br_ioctl_deviceless_stub通过调用brioctl_set,
将br_ioctl_deviceless_stub赋值给回调函数br_ioctl_hook,而br_ioctl_hook在sock_ioctl中使用。
这样通过在应用层调用socket的ioctl函数,就能够进行网桥的添加与删除了。
如果我们想增加新的ioctl,用于我们新开放的功能,就可以在该函数里增加新的case即可。
当我们输入上面命令时,就会触发br_ioctl_deviceless_stub函数来响应br_add_bridge函数,当命令执行完成以后,
使用brctl show命令就可以看见我们添加的br1这个网桥设备已经生成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int br_ioctl_deviceless_stub(struct net *net, unsigned int cmd, void __user *uarg)
{
switch (cmd) {
case SIOCGIFBR:
case SIOCSIFBR:
return old_deviceless(net, uarg);
case SIOCBRADDBR:
case SIOCBRDELBR:
{
char buf[IFNAMSIZ];
if (!ns_capable(net->user_ns, CAP_NET_ADMIN))
return -EPERM;
if (copy_from_user(buf, uarg, IFNAMSIZ))
return -EFAULT;
buf[IFNAMSIZ-1] = 0;
if (cmd == SIOCBRADDBR)
return br_add_bridge(net, buf);/*添加网桥设备的操作*/
return br_del_bridge(net, buf);
}
}
return -EOPNOTSUPP;
}
该函数注册在,桥设备添加时候dev->netdev_ops = &br_netdev_ops;
在br_netdev_ops有一个函数指针.ndo_do_ioctl= br_dev_ioctl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
int br_add_if(struct net_bridge *br, struct net_device *dev)
{
struct net_bridge_port *p;
int err = 0;
unsigned br_hr, dev_hr;
bool changed_addr;
/* Don't allow bridging non-ethernet like devices, or DSA-enabled
* master network devices since the bridge layer rx_handler prevents
* the DSA fake ethertype handler to be invoked, so we do not strip off
* the DSA switch tag protocol header and the bridge layer just return
* RX_HANDLER_CONSUMED, stopping RX processing for these frames.
*/
if ((dev->flags & IFF_LOOPBACK) ||
dev->type != ARPHRD_ETHER || dev->addr_len != ETH_ALEN ||
!is_valid_ether_addr(dev->dev_addr) ||
netdev_uses_dsa(dev))
return -EINVAL;
/* No bridging of bridges */
if (dev->netdev_ops->ndo_start_xmit == br_dev_xmit)
return -ELOOP;
/* Device is already being bridged */
if (br_port_exists(dev))
return -EBUSY;
/* No bridging devices that dislike that (e.g. wireless) */
if (dev->priv_flags & IFF_DONT_BRIDGE)
return -EOPNOTSUPP;
/*分配一个新网桥端口并对其初始化*/
p = new_nbp(br, dev);
if (IS_ERR(p))
return PTR_ERR(p);
/*调用设备通知链,告诉网络有这样一个设备*/
call_netdevice_notifiers(NETDEV_JOIN, dev);
/**向设备添加或删除所有多播帧的接收。*/
err = dev_set_allmulti(dev, 1);
if (err)
goto put_back;
err = kobject_init_and_add(&p->kobj, &brport_ktype, &(dev->dev.kobj),
SYSFS_BRIDGE_PORT_ATTR);
if (err)
goto err1;
/*把链路添加到sysfs*/
err = br_sysfs_addif(p);
if (err)
goto err2;
err = br_netpoll_enable(p);
if (err)
goto err3;
/*注册设备接收帧函数*/
err = netdev_rx_handler_register(dev, br_handle_frame, p);
if (err)
goto err4;
/*给该端口指派默认优先权*/
dev->priv_flags |= IFF_BRIDGE_PORT;
/*向上级设备添加主链路*/
err = netdev_master_upper_dev_link(dev, br->dev, NULL, NULL);
if (err)
goto err5;
/*禁用网络设备上的大型接收卸载(LRO)。
必须在RTNL下调用。
如果接收到的数据包可能转发到另一个接口,
则需要这样做。*/
dev_disable_lro(dev);
list_add_rcu(&p->list, &br->port_list);
/*更新桥上的端口数,如果有更新,再进一步将其设为混杂模式*/
nbp_update_port_count(br);
/* 重新计算dev->features并发送通知(如果已更改)。
应该调用驱动程序或硬件依赖条件可能会改变影响功能。*/
netdev_update_features(br->dev);
br_hr = br->dev->needed_headroom;
dev_hr = netdev_get_fwd_headroom(dev);
if (br_hr < dev_hr)
update_headroom(br, dev_hr);
else
netdev_set_rx_headroom(dev, br_hr);
/*把dev的mac添加到转发数据库中*/
if (br_fdb_insert(br, p, dev->dev_addr, 0))
netdev_err(dev, "failed insert local address bridge forwarding table\n");
/*初始化该桥端口的vlan*/
err = nbp_vlan_init(p);
if (err) {
netdev_err(dev, "failed to initialize vlan filtering on this port\n");
goto err6;
}
spin_lock_bh(&br->lock);
/*更新网桥id*/
changed_addr = br_stp_recalculate_bridge_id(br);
/*设备是否启动,桥是否启动,设备上是否有载波信号(网桥没有载波状态,因为网桥是虚拟设备)*/
if (netif_running(dev) && netif_oper_up(dev) &&
(br->dev->flags & IFF_UP))
/*启动网桥端口*/
br_stp_enable_port(p);
spin_unlock_bh(&br->lock);
br_ifinfo_notify(RTM_NEWLINK, p);
/*如果网桥的地址改变,则调用通知连相关的函数*/
if (changed_addr)
call_netdevice_notifiers(NETDEV_CHANGEADDR, br->dev);
/*更新网桥mtu*/
dev_set_mtu(br->dev, br_min_mtu(br));
br_set_gso_limits(br);
/*添加一个内核对象*/
kobject_uevent(&p->kobj, KOBJ_ADD);
return 0;
err6:
list_del_rcu(&p->list);
br_fdb_delete_by_port(br, p, 0, 1);
nbp_update_port_count(br);
netdev_upper_dev_unlink(dev, br->dev);
err5:
dev->priv_flags &= ~IFF_BRIDGE_PORT;
netdev_rx_handler_unregister(dev);
err4:
br_netpoll_disable(p);
err3:
sysfs_remove_link(br->ifobj, p->dev->name);
err2:
kobject_put(&p->kobj);
p = NULL; /* kobject_put frees */
err1:
dev_set_allmulti(dev, -1);
put_back:
dev_put(dev);
kfree(p);
return err;
}
在桥上添加接口的基本步骤,如上,删除桥端口,主要是把建立接口时所做的事情撤销,如添加接口出错时的一些处理。
桥设备及端口的开启和关闭
关于设备的添加删除的基本动作,我们已经知道。
这节,我们看看关于网桥设备以及桥设备上的端口的启动和关闭。
我们说过,在初始化一个桥设备的时候有这样一个操作:
dev->netdev_ops = &br_netdev_ops;
br_netdev_ops这个参数,注册了很多函数,其中包括网桥设备的启动和关闭函数
br_dev_open和br_dev_stop,这两个函数的工作主要是初始化桥设备的一些队列和
桥设备上端口的一些启动和关闭动作。
启动和关闭网桥设备
1
2
3
4
5
6
7
8
9
10
11
12
13
static int br_dev_open(struct net_device *dev)
{
struct net_bridge *br = netdev_priv(dev);
/*重新更新网桥设备功能*/
netdev_update_features(dev);
/*函数启动进行设备传输*/
netif_start_queue(dev);
/*启动网桥设备*/
br_stp_enable_bridge(br);
/*初始化网桥本身的多播对列*/
br_multicast_open(br);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
static int br_dev_stop(struct net_device *dev)
{
struct net_bridge *br = netdev_priv(dev);
/*关闭网桥设备*/
br_stp_disable_bridge(br);
/*关闭网桥设备的多播队列*/
br_multicast_stop(br);
/*关闭设备的传输,任何企图在设备上传输信息的尝试都会被拒绝*/
netif_stop_queue(dev);
return 0;
}
启动网桥设备,当启动网桥设备时,先前绑定在该设备上的端口也会跟着启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void br_stp_enable_bridge(struct net_bridge *br)
{
struct net_bridge_port *p;
/*锁定网桥*/
spin_lock_bh(&br->lock);
if (br->stp_enabled == BR_KERNEL_STP)
mod_timer(&br->hello_timer, jiffies + br->hello_time);
/* 当网桥启动时,设置次定时器,1/10秒到期一次 */
mod_timer(&br->gc_timer, jiffies + HZ/10);
/*TX配置bpdu*/
br_config_bpdu_generation(br);
list_for_each_entry(p, &br->port_list, list) {
if (netif_running(p->dev) && netif_oper_up(p->dev))
br_stp_enable_port(p);/*启动网桥设备的每个端口*/
}
/*给网桥解锁*/
spin_unlock_bh(&br->lock);
}
关闭网桥设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void br_stp_disable_bridge(struct net_bridge *br)
{
struct net_bridge_port *p;
spin_lock_bh(&br->lock);
list_for_each_entry(p, &br->port_list, list) {
if (p->state != BR_STATE_DISABLED)
br_stp_disable_port(p);/*关闭网桥设备的每个端口*/
}
/*重新设置拓扑标识*/
br->topology_change = 0;
br->topology_change_detected = 0;
spin_unlock_bh(&br->lock);
/*删除在初始化桥设备时的定时器*/
del_timer_sync(&br->hello_timer);
del_timer_sync(&br->topology_change_timer);
del_timer_sync(&br->tcn_timer);
del_timer_sync(&br->gc_timer);
}
启动和关闭网桥端口
要启动网桥端口,必须满足下列几个条件
1.被管理的相关设备已用管理手段启动
2.被绑定的相关设备有载波状态
3.相关的网桥设备已用管理手段启动
注意:网桥设备上没有载波状态,因为网桥是虚拟设备。
当网桥是以用户空间命令建起来并且先前三个条件都满足时,该网桥端口就可以立即启用了
但是,假设当端口建立时,由于上述三项条件至少有一项不满足无法启动端口时,下面的条件是
每项条件最终满足时启用端口的场合:
1.当被关闭的网桥设备重新启动时,其所有关闭的端口就会启用
2.当被绑定的设备检测到载波状态时,桥程序会收到NETDE_CHANGE通知消息
3.当被关掉的版定设备重启时,桥程序会收到NETDEV_UP的通知消息
如若还不满足,网桥端口就会被关闭
启动网桥上的端口
1
2
3
4
5
6
7
8
9
void br_stp_enable_port(struct net_bridge_port *p)
{
/*初始化端口*/
br_init_port(p);
/*遍历所有端口,为端口指定合适的状态*/
br_port_state_selection(p->br);
/*捕捉一个端口变化信息的通知*/
br_ifinfo_notify(RTM_NEWLINK, p);
}
关闭网桥上的端口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
void br_stp_disable_port(struct net_bridge_port *p)
{
struct net_bridge *br = p->br;
int wasroot;
/*判断是否是根网桥*/
wasroot = br_is_root_bridge(br);
/*分配制定角色*/
br_become_designated_port(p);
/*将关闭位置位*/
br_set_state(p, BR_STATE_DISABLED);
p->topology_change_ack = 0;
p->config_pending = 0;
br_ifinfo_notify(RTM_NEWLINK, p);
/*删除定时器*/
del_timer(&p->message_age_timer);
del_timer(&p->forward_delay_timer);
del_timer(&p->hold_timer);
/*更改转发表信息*/
br_fdb_delete_by_port(br, p, 0, 0);
br_multicast_disable_port(p);
/*更改桥的bpdu信息*/
br_configuration_update(br);
/*更新所有桥上端口的状态*/
br_port_state_selection(br);
/*处理非根网桥到根网桥的转移*/
if (br_is_root_bridge(br) && !wasroot)
br_become_root_bridge(br);
}
注意,当网桥端口关闭时,非根网桥可能会变成根网桥
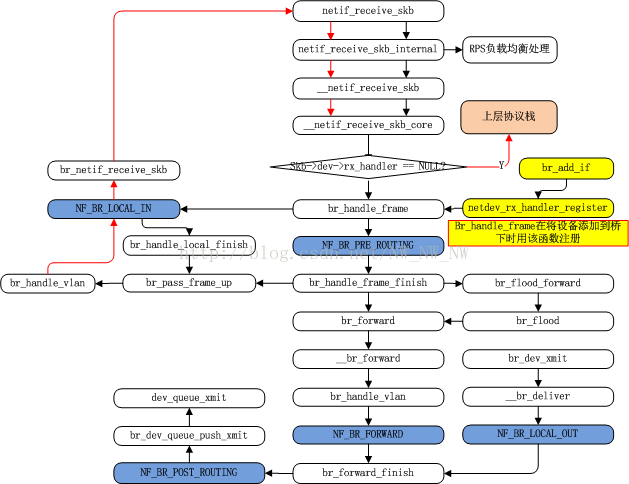
skb桥转发蓝图
需要说明的是:
1.我们先暂时忽略数据包从一开始是怎么从驱动进入到netif_receive_skb的,因为这个暂时不影响我们理解这幅图的流程。
2.由于桥转发的篇幅较大,图中没有标示出,数据包中途被丢弃的情况。约定数据包会发送成功。
现在数据包(skb)已经准备好了装备要闯关了
1.首先skb从驱动经过繁杂的路线走到了netif_receive_skb这个函数中经过一些小波折到达__netif_receive_skb_core中时遇到了第一个十字路口是看了看自己有没有skb->dev->rx_handler(注1)这个装备,如果有,则进入br_handle_frame(注2).如果没有则直接上协议栈。
注1:桥下的设备注册过rx_handler函数,所以数据包会进入桥,br_pass_frame_up函数将原先的设备换成了桥设备, 而桥设备没有注册过rx_handler函数,所以数据包不会二次进入桥。
注2:br_handle_frame我们在前几节提到过,是skb进入桥的入口函数,在br_add_if的时候会注册该函数。
2.skb注定要经历一番劫难,刚进入br_handle_frame又将陷入两难境地,此时有两个入口,这两个是netfilter设下的连个hook点,分别是,NF_BR_PRE_ROUTING,和NF_BR_LOCAL_IN,两种路径,如果数据包只想去本地,则会选择NF_BR_LOCAL_IN入口,然后发往本地,如果暂时还确定不了,则先进入NF_BR_PRE_ROUTING入口.
3.进入NF_BR_PRE_ROUTING入口后,会遇到br_handle_frame_finish函数,这个函数决定了skb的何去何从,(1)如果是转发,则在经过NF_BR_FORWARD钩子点进入转发阶段的障碍,最后在进入NF_BR_POST_ROUTING,以及最终的dev_queue_xmit,实现最终转发。(2)如果发往本地则重新进入NF_BR_LOCAL_IN最后在进入netif_receive_skb,进行转发。skb在经过目前口述的磨练最终得以释放。
4.如果是如果是本地发出的数据包,经过NF_BR_LOCAL_OUT钩子点然后进入最后阶段的NF_BR_POST_ROUTING,进行相应的转发。
桥数据包接收—-br_handle_frame
一个很重要的函数br_handle_frame这个函数的初始注册地点是在桥添加接口的时候,注册在桥某一个接口上
1
2
3
4
5
6
7
int br_add_if(struct net_bridge *br, struct net_device *dev)
{
........
/*注册设备接收帧函数*/
err = netdev_rx_handler_register(dev, br_handle_frame, p);
........
}
其次,那么__netif_receive_skb_core是怎样让数据包进入桥的呢?我们看看上面提到的netdev_rx_handler_register函数,具体做了什么
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int netdev_rx_handler_register(struct net_device *dev,
rx_handler_func_t *rx_handler,
void *rx_handler_data)
{
ASSERT_RTNL();
if (dev->rx_handler)
return -EBUSY;
/* Note: rx_handler_data must be set before rx_handler */
/*将dev->rx_handler_data,指向rx_handler_data(上面的p是桥端口信息)*/
rcu_assign_pointer(dev->rx_handler_data, rx_handler_data);
/*将dev->rx_handle指针指向rx_handler*/
rcu_assign_pointer(dev->rx_handler, rx_handler);
return 0;
}
看完这个函数,我们就明白了为什么在__netif_receive_skb_core中可以用skb->dev->rx_handle将数据包传入br_handle_frame函数,也就是将数据包传入了桥。
值得注意的是:上面的dev是桥下的设备,不是桥设备,桥设备(比如br0)是没有注册rx_handle这个函数的
好,了解到,桥的注册函数和如何接收数据包后,然后一起来看看br_handle_frame是如何操作的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
/*
* Return NULL if skb is handled
* note: already called with rcu_read_lock
*/
rx_handler_result_t br_handle_frame(struct sk_buff **pskb)
{
struct net_bridge_port *p;
struct sk_buff *skb = *pskb;
const unsigned char *dest = eth_hdr(skb)->h_dest;
br_should_route_hook_t *rhook;
if (unlikely(skb->pkt_type == PACKET_LOOPBACK))
return RX_HANDLER_PASS;
/*判断是否是有效的mac地址,即不是多播地址也不是全00地址*/
if (!is_valid_ether_addr(eth_hdr(skb)->h_source))
goto drop;
/*判断是否是共享数据包,若果是则clone该数据包*/
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
return RX_HANDLER_CONSUMED;
/*获取数据包网桥端口的一些信息*/
p = br_port_get_rcu(skb->dev);
/*BPDU是网桥之间交流的报文,目标mac是 01:80:C2:00:00:00*/
if (unlikely(is_link_local_ether_addr(dest))) {
u16 fwd_mask = p->br->group_fwd_mask_required;
/*
* See IEEE 802.1D Table 7-10 Reserved addresses
*
* Assignment Value
* Bridge Group Address 01-80-C2-00-00-00
* (MAC Control) 802.3 01-80-C2-00-00-01
* (Link Aggregation) 802.3 01-80-C2-00-00-02
* 802.1X PAE address 01-80-C2-00-00-03
*
* 802.1AB LLDP 01-80-C2-00-00-0E
*
* Others reserved for future standardization
*/
switch (dest[5]) {
case 0x00: /* Bridge Group Address */
/* If STP is turned off,
then must forward to keep loop detection */
if (p->br->stp_enabled == BR_NO_STP ||
fwd_mask & (1u << dest[5]))
goto forward;
*pskb = skb;
__br_handle_local_finish(skb);
return RX_HANDLER_PASS;
case 0x01: /* IEEE MAC (Pause) */
goto drop;
case 0x0E: /* 802.1AB LLDP */
fwd_mask |= p->br->group_fwd_mask;
if (fwd_mask & (1u << dest[5]))
goto forward;
*pskb = skb;
__br_handle_local_finish(skb);
return RX_HANDLER_PASS;
default:
/* Allow selective forwarding for most other protocols */
fwd_mask |= p->br->group_fwd_mask;
if (fwd_mask & (1u << dest[5]))
goto forward;
}
/* Deliver packet to local host only */
NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN, dev_net(skb->dev),
NULL, skb, skb->dev, NULL, br_handle_local_finish);
return RX_HANDLER_CONSUMED;
}
forward:
switch (p->state) {
case BR_STATE_FORWARDING:
/*ebtables获取路由的hook点*/
rhook = rcu_dereference(br_should_route_hook);
if (rhook) {/*如果是转发状态,则转发数据包,然后返回*/
if ((*rhook)(skb)) {
*pskb = skb;
return RX_HANDLER_PASS;
}
dest = eth_hdr(skb)->h_dest;
}
/* fall through */
case BR_STATE_LEARNING:
/*目的地址是否是设备链路层地址 */
if (ether_addr_equal(p->br->dev->dev_addr, dest))
skb->pkt_type = PACKET_HOST;
/*将数据包送入数据帧处理函数br_handle_frame_finish*/
NF_HOOK(NFPROTO_BRIDGE, NF_BR_PRE_ROUTING,
dev_net(skb->dev), NULL, skb, skb->dev, NULL,
br_handle_frame_finish);
break;
default:
drop:
kfree_skb(skb);
}
return RX_HANDLER_CONSUMED;
}
在br_handle_frame主要做一件事,就是将数据包放进那个钩子点。
说明:br_handle_frame函数中有两个hook函数,br_handle_local_finish和br_handle_frame_finish这两个函数只有在netfilter因其他原因没有丢弃或者消化该帧时才会被调用,ebtables也能查看帧。ebtables是一个架构,能提供一些netfilter所没有的提供的额外功能,尤其是,ebtables可以过滤和修改任何类型的帧,而非仅限于那些携带ip封包的帧。
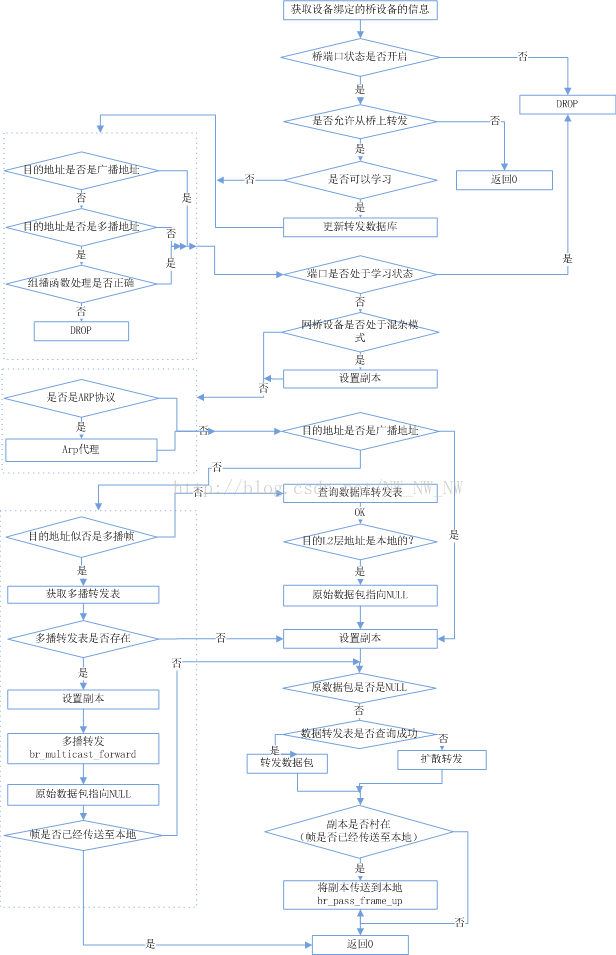
桥数据包处理函数——br_handle_frame_finish
br_handle_frame_finish.
作用:br_handle_frame_finish函数主要是决策将不同类别的数据包做不同的分发路径。
其函数处理的过程如下图所示:
首先判断该数据包是否符合桥转发的条件:
(1)桥端口状态是否是开启状态,如果没有开启则丢掉数据包
(2)是否允许从该桥上转发,如果不允许,则直接返回0
获得桥转发的条件以后,开始判断数据包的类型:
(1)判断此时桥的标志为允许做哪些事情,学习还是扩展
如果学习的标志位被至位,则更新数据转发表。否则继续向下走
(2)根据多播或者广播报文的类型决定数据包的去留
(3)判断此时端口的状态,如果是学习状态,则将数据包丢弃
(要注意的是:桥的端口状态(和上面的flag不冲突,上面的flag表示网桥可以做的事情)state表示网桥端口所处于的状态)
在处理完一些需要预备的事情之后,就要为数据包的转发开始做准备了
(1)网桥设备是否处于混杂模式,如果是则建立副本,为发往本地做个备份
(注意的是,所有网桥端口绑定的设备都会处于混杂模式,因为 网桥运行必须此模式。但除非明确的对其进行配置,否则网桥自己是不会处于混杂模式的)
(2)在次判断广播还是多播地址
广播地址:仅仅设置副本,进行广播转发和发往本地
多播地址:先查多播地址转发表,如果存在,设置副本,进行多播转发,原始数据包指向NULL,如果已经传送至本地,则会释放副本,不进行本地转发,否则重新转发到本地
(3)不是广播或者多播
判断是否本地地址,如果是本地地址,则将原始数据包指向NULL,发往本地。
否则进行数据包转发
桥数据包转发
无论是在发往本地还是转发,有一个函数的功能是不能忽略的,就是br_handle_vlan函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
struct sk_buff *br_handle_vlan(struct net_bridge *br,
struct net_bridge_vlan_group *vg,
struct sk_buff *skb)
{
struct br_vlan_stats *stats;
struct net_bridge_vlan *v;
u16 vid;
/* If this packet was not filtered at input, let it pass */
if (!BR_INPUT_SKB_CB(skb)->vlan_filtered)
goto out;
/* At this point, we know that the frame was filtered and contains
* a valid vlan id. If the vlan id has untagged flag set,
* send untagged; otherwise, send tagged.
*/
br_vlan_get_tag(skb, &vid);
/*find vid from vlan group*/
v = br_vlan_find(vg, vid);
/* Vlan entry must be configured at this point. The
* only exception is the bridge is set in promisc mode and the
* packet is destined for the bridge device. In this case
* pass the packet as is.
*/
if (!v || !br_vlan_should_use(v)) {
if ((br->dev->flags & IFF_PROMISC) && skb->dev == br->dev) {
goto out;
} else {
kfree_skb(skb);
return NULL;
}
}
/*statistacs the vlan if flow and if the vlan_stats_enabled is true */
if (br->vlan_stats_enabled) {
stats = this_cpu_ptr(v->stats);
u64_stats_update_begin(&stats->syncp);
stats->tx_bytes += skb->len;
stats->tx_packets++;
u64_stats_update_end(&stats->syncp);
}
if (v->flags & BRIDGE_VLAN_INFO_UNTAGGED)
skb->vlan_tci = 0;
out:
return skb;
}
这个函数的作用很简单就是,数据包是否要带tag,
过程:
在传递进来的vlan group中查找自己所处的vlan
如果该vlan不存在则判断当前模式是否是混杂模式和数据包的设备是否是桥下的设备,选择发包或者丢弃。
如果存在,且vlan是开启的,则统计vlan接口上的数据流量,最后根据vlan出口的标记位进行位运算判断是否要带tag.
然后我们来看一下上节提到的发往本地数据包的处理函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
static int br_pass_frame_up(struct sk_buff *skb)
{
struct net_device *indev, *brdev = BR_INPUT_SKB_CB(skb)->brdev;
struct net_bridge *br = netdev_priv(brdev);
struct net_bridge_vlan_group *vg;
struct pcpu_sw_netstats *brstats = this_cpu_ptr(br->stats);
/*统计该桥上的流量*/
u64_stats_update_begin(&brstats->syncp);
brstats->rx_packets++;
brstats->rx_bytes += skb->len;
u64_stats_update_end(&brstats->syncp);
/*获取该桥上的vlan组*/
vg = br_vlan_group_rcu(br);
/* Bridge is just like any other port. Make sure the
* packet is allowed except in promisc modue when someone
* may be running packet capture.
*/
if (!(brdev->flags & IFF_PROMISC) &&
!br_allowed_egress(vg, skb)) {
kfree_skb(skb);
return NET_RX_DROP;
}
/*替换掉数据包中的设备信息改为桥设备*/
indev = skb->dev;
skb->dev = brdev;
/*配置数据包vlan的相关信息*/
skb = br_handle_vlan(br, vg, skb);
if (!skb)
return NET_RX_DROP;
/*进入NF_BR_LOCAL_IN*/
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN,
dev_net(indev), NULL, skb, indev, NULL,
br_netif_receive_skb);
}
这个函数所做的事情很简单,就是配置vlan的相关信息后,然后发往本地的netfilter钩子函数中
最后重新回到netif_recive_skb.如下函数:
1
2
3
4
5
static int
br_netif_receive_skb(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return netif_receive_skb(skb);
}
再来看看数据包转发的函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
struct net_bridge_vlan_group *vg;
struct net_device *indev;
if (skb_warn_if_lro(skb)) {
kfree_skb(skb);
return;
}
/*获取vlan组,这个组中有许多的vlanid,br_handle_vlan函数就是要在这个组中查找自己的vid*/
vg = nbp_vlan_group_rcu(to);
/*添加vlan的相关配置*/
skb = br_handle_vlan(to->br, vg, skb);
if (!skb)
return;
indev = skb->dev;
skb->dev = to->dev;
skb_forward_csum(skb);
NF_HOOK(NFPROTO_BRIDGE, NF_BR_FORWARD,
dev_net(indev), NULL, skb, indev, skb->dev,
br_forward_finish);
}
int br_forward_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_POST_ROUTING,
net, sk, skb, NULL, skb->dev,
br_dev_queue_push_xmit);
}
整个数据包转发的过程与转发到本地的过程类似,只不过所进入的netfilter钩子点不同.
整个分析中不包含数据包从本地发出的数据包