https://www.zhihu.com/question/19765436
这种数字字形设计叫「old-style figures」,又称「non-lining figures」、「text figures」等(「figures」即「数字
」)。与之相对的是 lining figures(和「A」、「B」等字母占位一致的数字设计)。
阿拉伯数字
最初于中世纪传到欧洲之后,old-style 数字是最常见、最自然的数字写法之一,它和小写拉丁字母的字形韵律一致,同样拥有上伸部和下延部
。具体的写法经数百年时间演变,成为事实标准,于是今天的 old-style 数字一般都是这样的:
像「a」一样没有上伸部或下延部的:0、1、2像「b」一样有上伸部的:6、8像「g」一样有下延部的:3、4、5、7、9
下图为 Adobe Garamond Pro (Regular) 的变宽 old-style 数字:
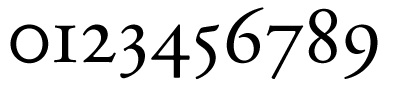
这样理所当然的传统数字写法后来也就刻进了印刷字体
中,但后来等高的 lining 数字变得越来越常见。
Lining 数字的
设计一般是兼顾大小写拉丁字母的,像大写字母一样只占一行的中上部,但顶部又比大写字母矮一些,以便和小写字母混排时不会高得太突兀。这大概是一种妥协,可以减少排字时需要的字形数量(不必为大写字母和小写字母分别提供数字字形),简化排字工艺,也让数字「整齐划一」,有现代感。
一些字体的数字设计是 old-style 的,比如 Georgia、Hoefler Text;一些专业字体基于强大的 OpenType 技术提供多种数字设计(比如 old-style、lining、与大写字母搭配的、与小型大写字母搭配的、上标、下标、分子
、分母)可选,比如 Arno Pro、Myriad Pro。
还有一些字体受技术限制而分别提供 old-style 和 lining 数字设计
的版本,仅数字设计不同,比如 Bodoni SvtyTwo OS ITC TT 和 Bodoni SvtyTwo ITC TT,前者字体族名的「OS」就是「Old-Style」的简写。还有些字体会标成「OSF」,也就是「Old-Style Figures」。
西文文字设计
(typography、字体排印
)界向来认为,old-style 数字更适合大小写混合的正文排版,因为与小写字母协调。比如,专业的西文小说排版中,一般都是 old-style 数字。
因为汉字的高度一致,所以 lining 数字倒是更适合汉字——就像很多人觉得中西文
混排时西文全大写才和中文协调。所以生活在汉字世界
的人很少见到 old-style 数字。
另外,lining
与否和等宽与否是数字设计的两大参数,它俩组合出四种最常见的数字设计:
变宽 old-style(non-lining)数字:最自然的传统数字设计,old-style 数字一般都是这样。等宽 old-style(non-lining)数字:可用于表格,保持上伸部和下延部韵律的同时又能保证行与行之间的数字纵向对齐,一般仅专业字体提供。变宽 lining 数字:高度一致,但宽度不一致,随字形自由设定(比如「1」窄而「0」宽),这样能保证字符之间的距离均匀。等宽 lining 数字:如今最常见的数字设计,最现代、最整齐、最死板。

