

https://blog.csdn.net/weixin_44652157/article/details/100095620
发现没有你的服务器会额外多出一个以太网口来,那个网口是专门用来访问管理控制器(BMC)的,当然也可以通过普通网口的共享模式访问BMC。
什么是共享网口方式?
这里要简单地提到NC-SI(Network Controller – Sideband Interface)技术,即网络控制器边带接口技术。这一技术是用来实现BMC芯片和以太网控制器之间信息传递的,它使得BMC芯片能够像使用独立管理网口那样使用主板上的网络接口。以下是共享访问模式的实现结构图:
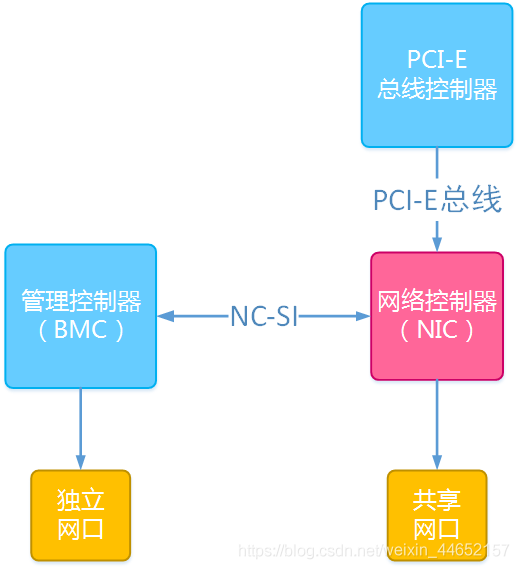
NCSI
简单理解:BMC其实是一个单片机,它有自己独立的IO设备,而独立网口就是其中之一。将BMC芯片和网络控制器之间互联,并通过NC-SI技术使得BMC芯片能够使用网络控制器上的接口。 为何要使用共享网口访问管理控制器?
1、减少物料成本:共享访问模式能够为单机节省一根网线;
2、减少人力成本:如果业务网只需要接一根网线,共享方案可以减少一半的布线人力支出;
3、减少交换机投入:独立网口会多占用一个交换机端口,增加交换机采购数量,使用共享模式减少了这部分的支出和额外的交换机运维成本;
如何实现共享网口模式?
1、BIOS或者WEB bmc界面中将IPMI访问方式修改为share(共享模式);
2、为共享网口独立分配一个VLAN号和IP地址,以便和业务网剥离;
3、在交换机端开启802.1q协议,并分配相同的VLAN号。