https://zhidao.baidu.com/question/562210466660809044.html
row_array()返回的仅仅是查询结果中的第一条数据(返回的是一维数组),
result_array()则会返回所有查询结果(返回的是二维数组),这就是区别


https://zhidao.baidu.com/question/562210466660809044.html
row_array()返回的仅仅是查询结果中的第一条数据(返回的是一维数组),
result_array()则会返回所有查询结果(返回的是二维数组),这就是区别
https://www.jb51.net/article/223573.htm
sqlplus / as sysdba
直接用sys登录,无须密码
sqlplus username/password@ip:port/sid
sqlplus username/password@orcl – 简写(前提:配置了 TNS),以下同
sqlplus /nolog
conn username/password@ip:port/sid
https://jingyan.baidu.com/article/67508eb43cf7879ccb1ce47e.html
右键点击“我的电脑”选择“管理”
在“计算机管理”界面找到“本地用户和组”-“组”。并在相应的页面中找到名字为:ora_dba的组。
点击这个ora_dba的组,在弹出页面中查看下当前登录用户是否在这个组内,如果没在,那么点击添加吧。
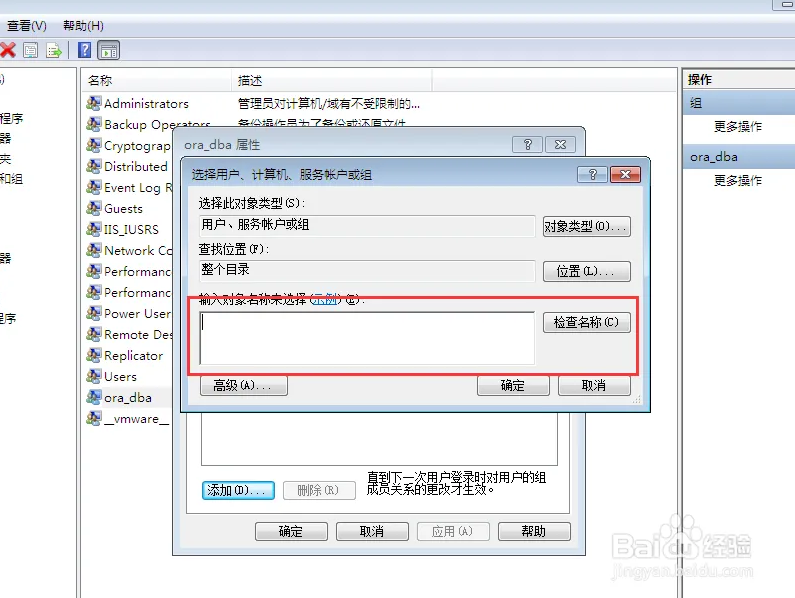
添加用户到ora_dba组的时候需要输入登录用户名。在“输入对象名称来选择”框中输入您希望使用sysdba登录的计算机用户,并点击检索名称。
https://blog.csdn.net/weixin_52479106/article/details/120007249
1 2 3 | |
或者也可用下面这个
1 2 3 | |
进入软件界面,点击“Configure”,然后选择“Preferences”;
找到“Appearance”在Language中选择“Chinese.lang”然后点击“OK”就成功设置成中文了
http://www.nndssk.com/upan/rjjc/15013.html
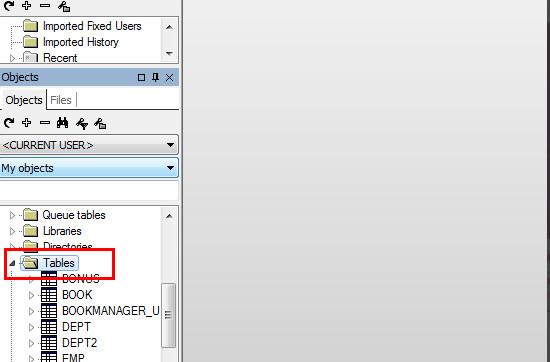
在对象浏览器选择“my object”
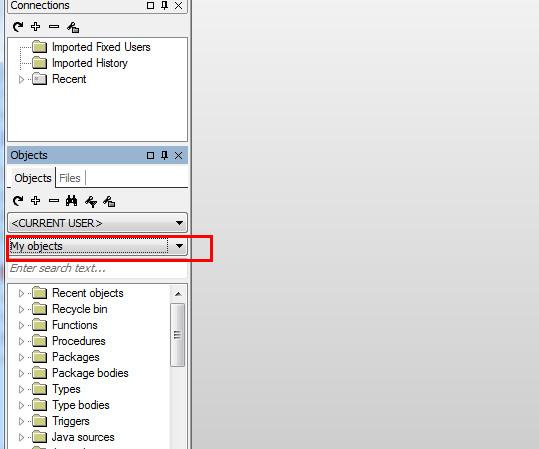
找到table文件夹,里边就是当前账户的所有表格