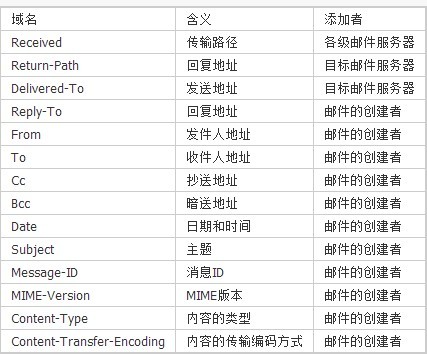
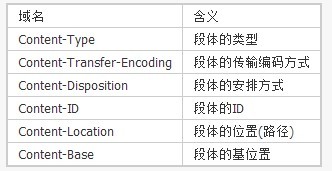
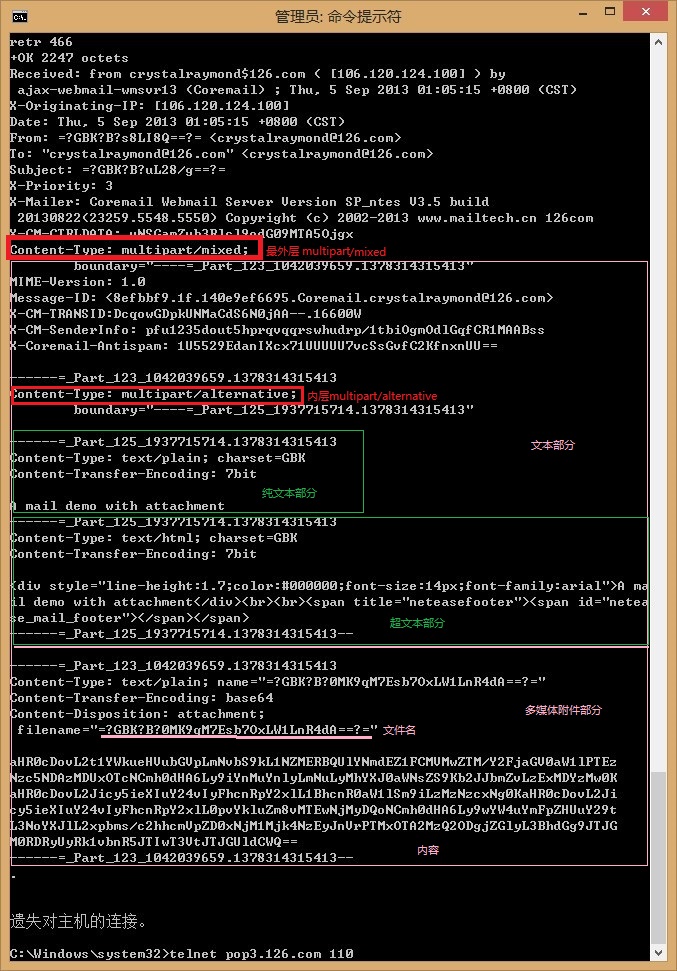
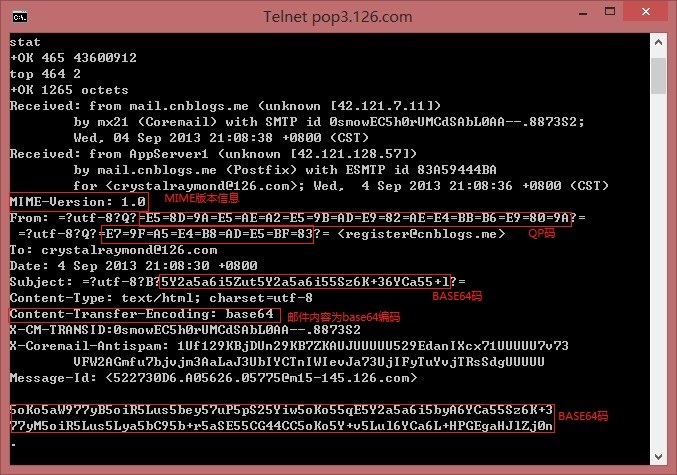
1 2 3 4 | |
https://blog.csdn.net/huangzx3/article/details/86526068
1 、什么是DNSSEC
DNSSEC(DNS Security Extension)—-DNS安全扩展,主要是为了解决DNS欺骗和缓存污染问题而设计的一种安全机制。
1.1 DNS欺骗&缓存污染
客户端(pc)发起域名(例如:www.baidu.com)请求的时候,如果在本地缓存没有的情况下,会往递归服务器发送域名查询请求(我们也称之为localdns),递归服务器再一层层递归从.到com.再到baidu.com.(即到.的权威服务器–>com.的权威服务器–>baidu.com.的权威服务器),最终取到www.baidu.com.对应的解析A记录返回给客户端。在整个查询过程中,攻击者可以假冒任何一个应答方:递归服务器–>.的权威服务器–>com.的权威服务器–>baidu.com.的权威服务器,给请求方发送一个伪造的响应(UDP包极其容易伪造),其中响应的解析记录给了一个错误的IP地址或者其他类型的解析记录(比如NXDomain、ServFail或者cname到错误的域名地址去等)。客户端或者是解析服务器在没有经过数据来源正确性校验的情况下接受了伪造的应答,直接将导致客户端无法正常访问网站或者其他资源或者客户端请求重定向到了伪造的网站上去。另外由于DNS当中存在着缓存,这种错误的记录将随着攻击者设定的TTL进行存活缓存,如果是递归服务器受到DNS欺骗那将会导致自身以及大面积的客户端缓存了错误的解析记录(可以通过清除缓存解决)。
2、DNSSEC原理
DNSSEC依靠数字签名来保证DNS应答报文的真实性和完整性。简单来说,权威服务器使用私钥对资源记录进行签名,递归服务器利用权威服务器的公钥对应答报文进行验证。如果验证失败,则说明这一报文可能是有问题的。
例子:
一台支持dnssec的递归服务器向支持dnssec的权威服务器发起paypal.com.的A记录请求,它除了得到A记录以外还得到了同名的RRSIG记录,其中包含了paypal.com.这个ZONE的权威数字签名,它使用paypal.com.的私钥来签名。为了验证这一签名是否正确,递归服务器再次向paypal.com.权威查询其公钥,即请求paypal.com.的dnskey类型的记录。递归服务器就可以使用公钥来验证收到的A记录是否是真实且完整的。但是注意:这种状态下,这台权威服务器可能是假冒的,递归服务器请求这台假冒的权威服务器,那么对于解析结果的正确性和完整性的验证上认为是正确的,但其实这个解析结果是假冒的,怎么发现?DNSSEC需要一条信任链,即必须要有一个或者多个相信的公钥,这些公钥被称为信任锚。理想情况下,假设dnssec已经实现了全部署,那每个递归服务器只需要保留根域名服务器的dnskey。
如下:
3、DNSSEC的资源记录
为了实现资源记录的签名和验证,DNSSEC增加了四种类型的资源记录:RRSIG(Resource Record Signature)、DNSKEY(DNS Public Key)、DS(Delegation Signer)、NSEC(Next Secure)
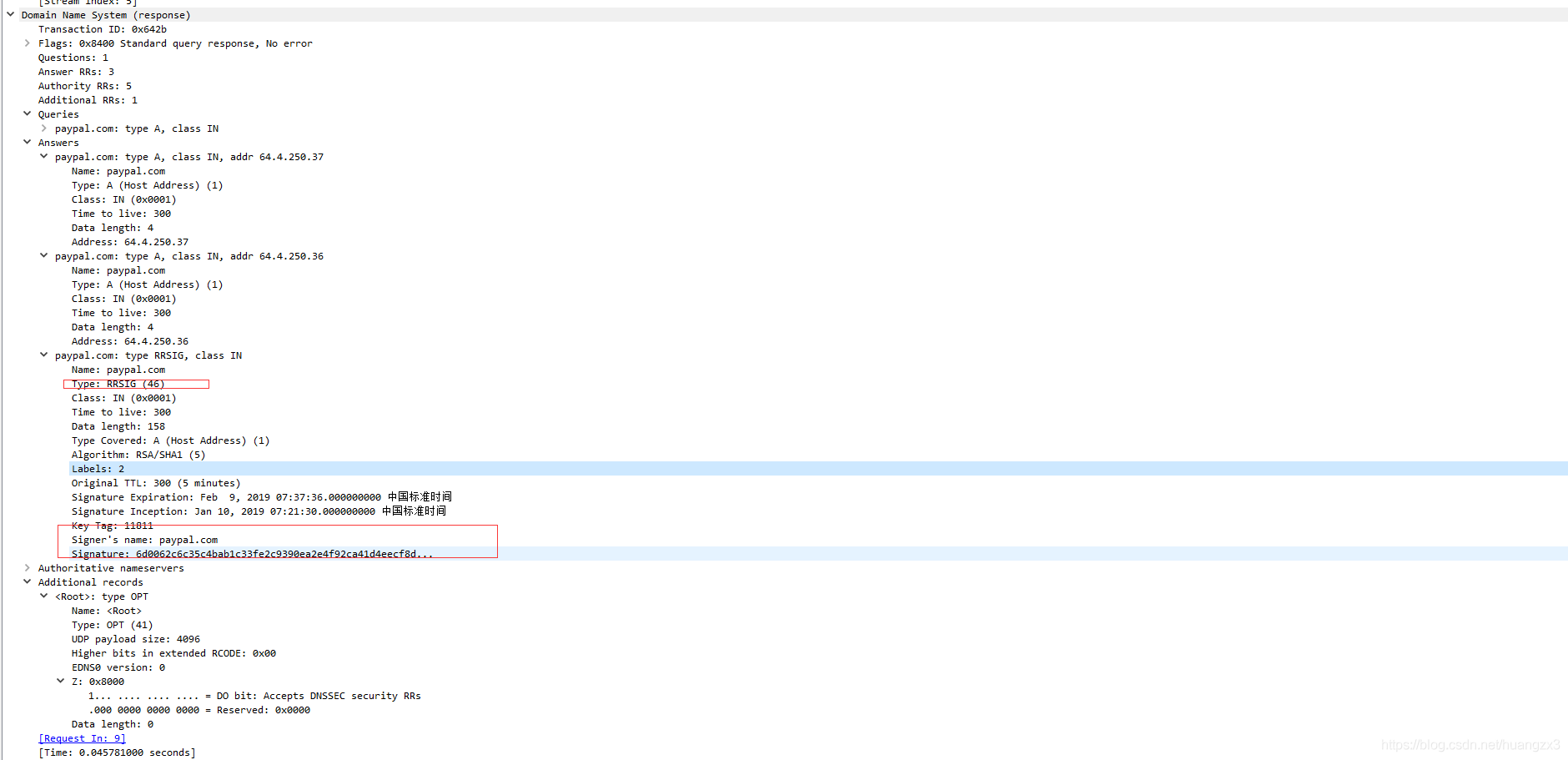
3.1 RRSIG记录
RRSIG资源记录存储的是对资源记录集合(RRSets)的数字签名。如下:
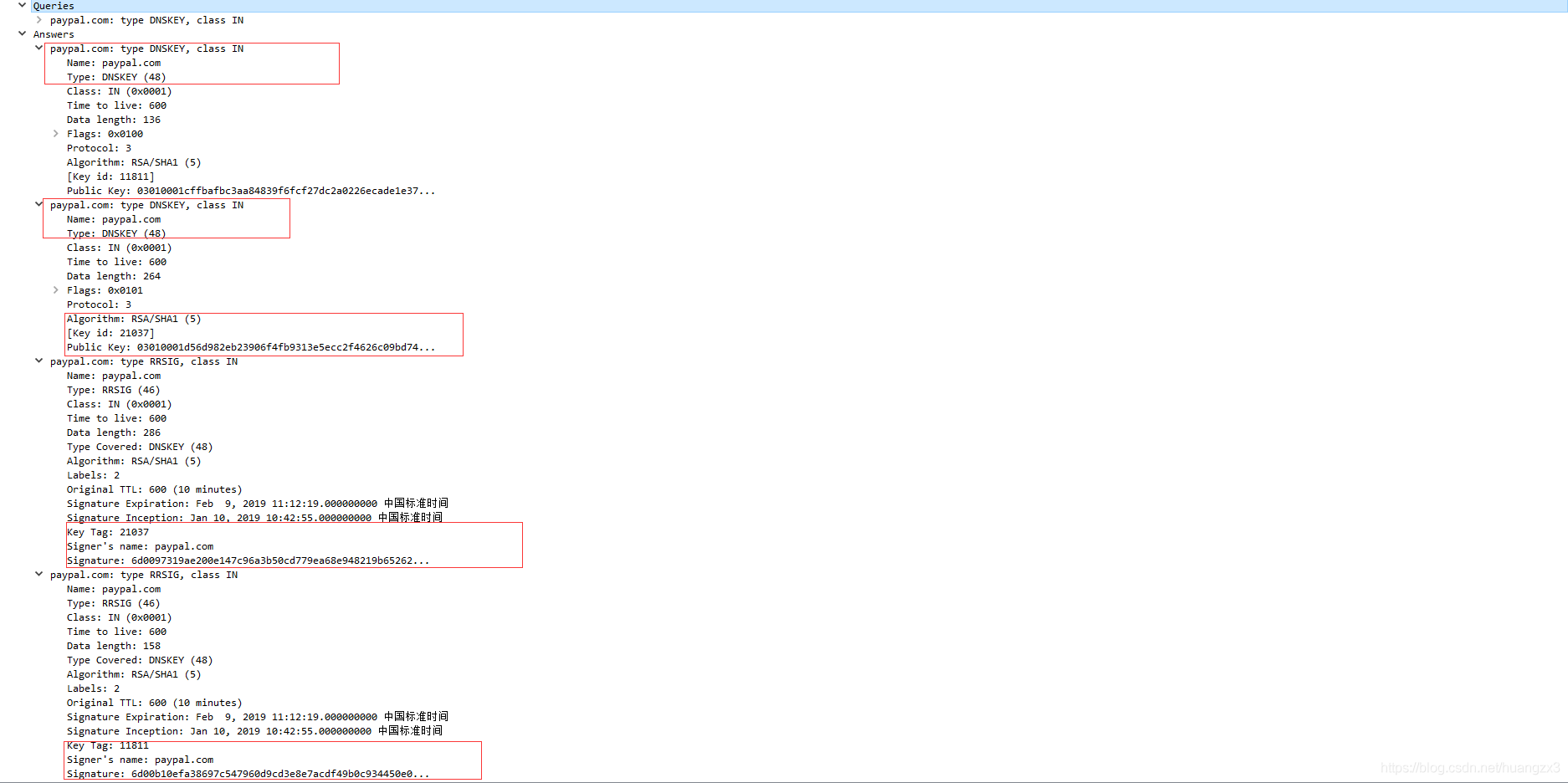
3.2 DNSKEY记录
DNSKEY资源记录存储的是公开密钥,下面是一个DNSKEY的资源记录的例子:
在实践中,权威域的管理员通常用两个密钥配合完成对区数据的签名。一个是Zone-Signing Key(ZSK),另一个是Key-Signing Key(KSK)。ZSK用于签名区数据,而KSK用于对ZSK进行签名。这样做的好处有二:
(1)用KSK密钥签名的数据量很少,被破解(即找出对应的私钥)概率很小,因此可以设置很长的生存期。这个密钥的散列值作为DS记录存储在上一级域名服务器中而且需要上级的数字签名,较长的生命周期可以减少密钥更新的工作量。
(2)ZSK签名的数据量比较大,因而破解的概率较大,生存期应该小一些。因为有了KSK的存在,ZSK可以不必放到上一级的域名服务中,更新ZSK不会带来太大的管理开销(不涉及和上级域名服务器打交道)。
如下:
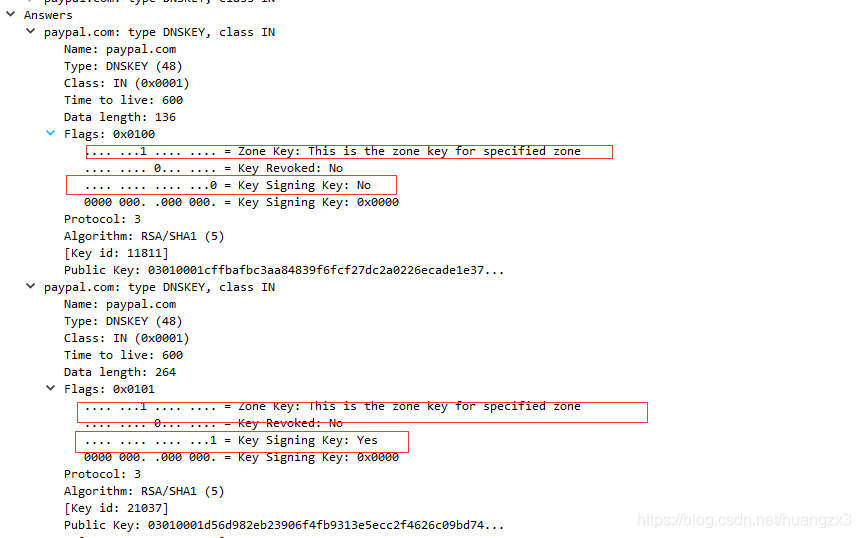
3.3 DS记录
DS(Delegation Signer)记录存储DNSKEY的散列值,用于验证DNSKEY的真实性,从而建立一个信任链。DNSKEY存储在资源记录所有者所在的权威域的区文件中,但是DS记录存储在上级权威域名服务器中,比如paypal.com的DS RR存储在.com的区中。如下:
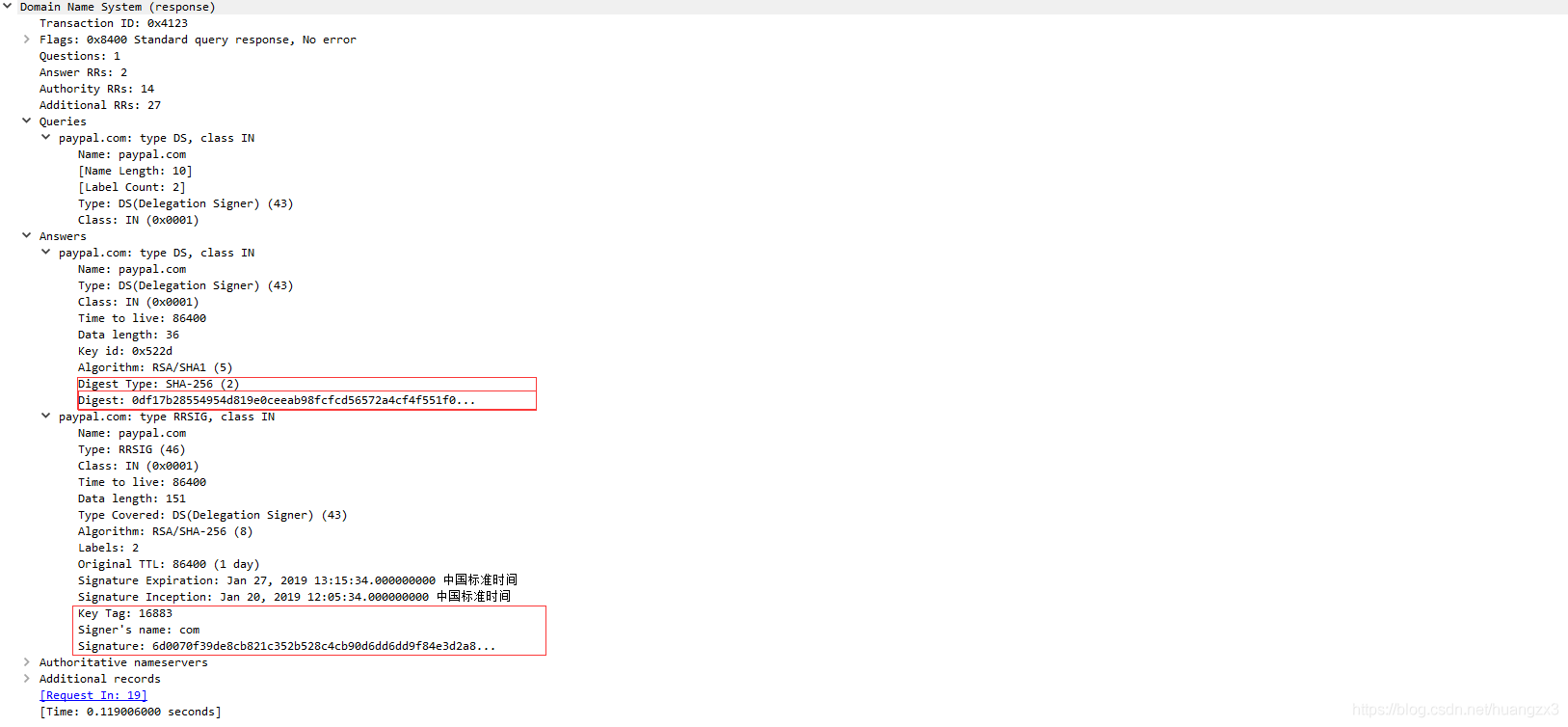
3.4 NSEC记录
NSEC记录是为了响应那些不存在的资源记录而设计的。为了保证私有密钥的安全性和服务器的性能,所有的签名记录都是事先生成的。服务器显然不能为所有不存在的记录事先生成一个公共的“不存在”的签名记录,因为这一记录可以被重放(Replay);更不可能为每一个不存在的记录生成独立的签名,因为它不知道用户将会请求怎样的记录。
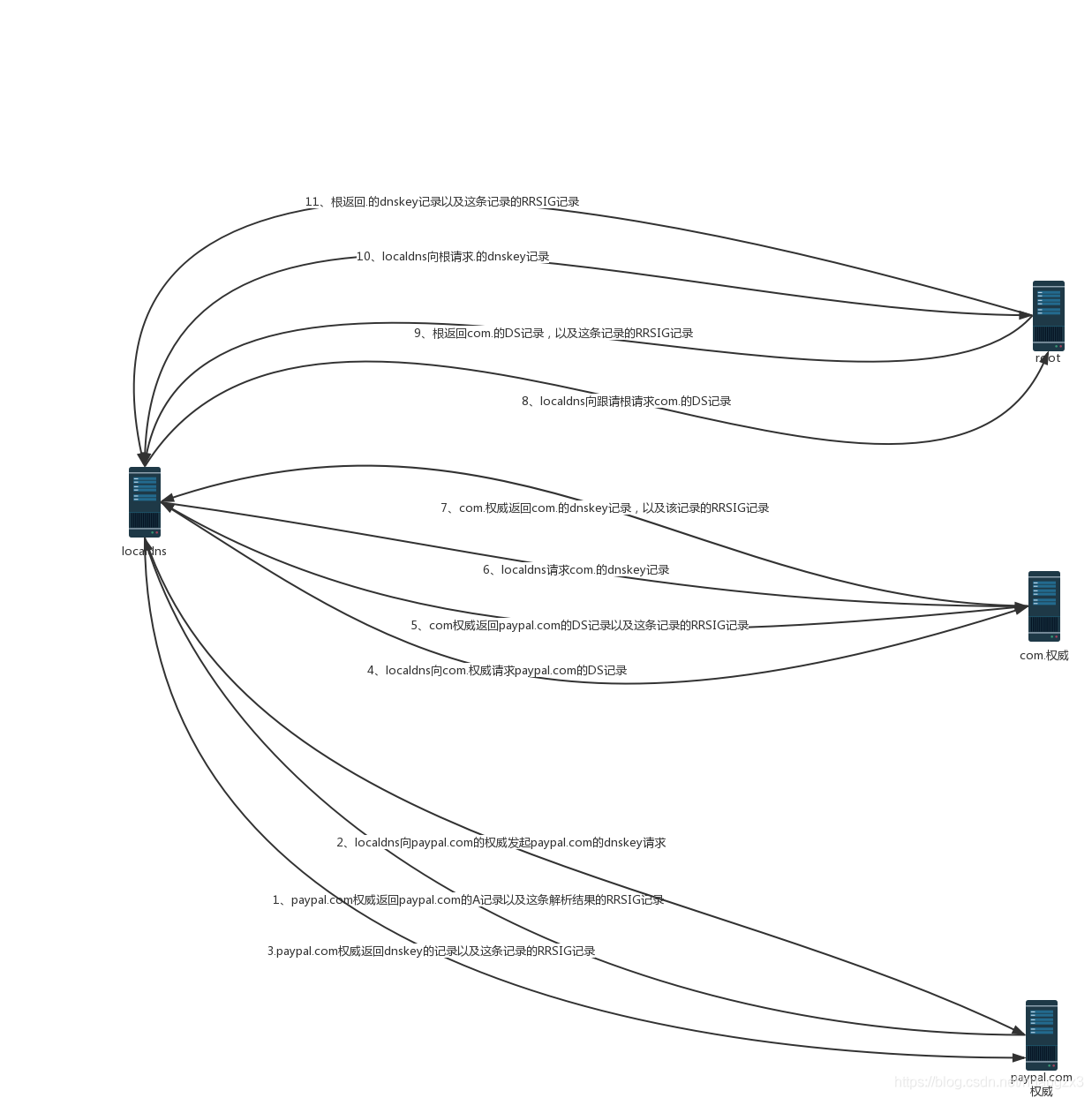
4、DNSSEC请求过程
下面是针对paypal.com.的一个解析过程,抓包过程有丢包,但是不影响对于dnssec解析过程的大致理解
解析过程中关于DNSSEC的请求过程大致如下:
过程图如下所示:
5、DNSSEC中的DLV
DLV–DNSSECLookasideValidation
1、localdns在其上层zone权威服务器查找被验证ZONE的DS记录
2、如果不存在,向DLV注册机构发出一个对DLV记录的请求
3、如果成功,DLV资源记录被当做这个ZONE的DS记录
4、localdns进行真实性可完整性验证
DLV是一个DNS服务器,提供DNSSEC签名认证的信任链一个解决方案,递归服务器配置的信任锚点是DLV,就可以认证域,进而认证权威域授权的信任的权威域。
递归服务器的配置:当设置了dnssec-lookaside,它为验证器提供另外一个能在网络区域的顶层验证DNSKEY的方法
1 2 3 4 | |
6、DNSSEC的一些设想
6.1 DNSSEC与防域名劫持
dnssec并没有办法在域名劫持上起到很好的作用,如果发生域名劫持则无法得到真正的解析结果,因为数字签名校验是没有校验通过的。实际上较多localdns在各个yys手上,各个yys可以对localdns进行相应的改造,则域名劫持会依然存在。
6.2 DNSSEC可能导致解析失败
响应中也有RRSIG记录,会直接导致UDP包的大小超过512字节,那么可能造成部分localdns解析失败,因为根据之前对于线上的观察,部分localdns并不支持超过512字节大小的UDP包,从而可能直接导致响应失败。