https://zhuanlan.zhihu.com/p/420005356
SASL 认证
默认情况下使用postfix发送电子邮件是不需要认证的,这个内部系统调用还好,如果是当作用户邮箱使用就不合适了!
postfix的认证方式和sendmail一样,也是利用SASL实现的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| vim /etc/postfix/main.cf
smtpd_sasl_path = smtpd
smtpd_sasl_auth_enable = yes
# 客户端支持
broken_sasl_auth_clients = yes
# 禁止匿名
smtpd_sasl_security_options = noanonymous
smtpd_recipient_restrictions = permit_mynetworks, permit_sasl_authenticated, reject
# TODO 满足 mynetworks 就发送了, 如何写才能满足 sasl 也认证???
# 默认情况下是可以通过匿名方式发送邮件的, 这段的意思是,通过sasl认证的可以,其他拒绝。
# 如果去掉这行,认证和不认证的用户都能发邮件
|
1
2
| systemctl restart saslauthd
systemctl restart postfix
|
查看可用的认证方式 saslauthd -v
用linux用户即可认证
配置邮件路径与存储路径
vim /etc/dovecot/conf.d/10-mail.conf
mail_location = maildir:~/Maildir //取消该行注释即可。
因为我们修改了postfix的主配置文件 home_mailbox = Maildir/,
即用户的新邮件会放到/home/user/Maildir目录下,所以dovecot也得修改mail_location目录
设置发件人、服务器
vim /etc/mail.rc
1
| set from=secure@41.cc smtp=192.168.100.41
|
1
2
3
| mail -s "tttt" 1@qq.com</tmp/jkl
tail -f /var/log/maillog
|
mail 发送邮件
1
2
3
4
5
6
7
8
9
10
11
| 1) 无邮件正文
mail -s "主题" 收件地址
2) 有邮件正文
mail -s "主题" 收件地址< 文件(邮件正文.txt)
echo "邮件正文" | mail -s 邮件主题 收件地址
cat 邮件正文.txt | mail -s 邮件主题 收件地址
3) 带附件
mail -s "主题" 收件地址 -a 附件 < 文件(邮件正文.txt)
mail -s "邮件主题" 1968089885@foxmail.com -a /data/findyou.tar.gz < /data/findyou.txt
|
认证?
1
2
| set from=secure@41.cc smtp=192.168.100.41
set smtp-auth-user=secure@41.cc smtp-auth-password=123456 smtp-auth=login
|
https://blog.csdn.net/qq_51235445/article/details/125429006
https://blog.csdn.net/dingguanyi/article/details/82432294
http://t.zoukankan.com/rusking-p-7597617.html
https://blog.csdn.net/shiyuan0/article/details/44101169
实验环境:
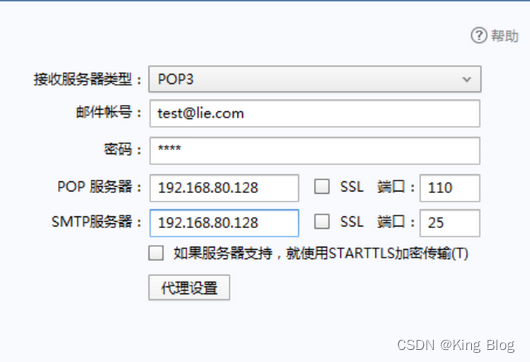
CentOS 7(邮件服务器) ip 192.168.80.128,同网段的一台Windows7(客户端测试)
1、配置服务器主机名称,服务器主机名称与发信域名要一致
1
2
3
4
| [root@lie ~]# vim /etc/hostname
mail.lie.com
[root@lie ~]# hostname
mail.lie.com
|
2、配置Postfix服务程序
yum安装一下, 直接修改配置文件(6处修改位置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| [root@lie ~]# vim /etc/postfix/main.cf
# 设置主机名 在76行左右
myhostname = mail.lie.com
# 设置域名 在86行左右
mydomain = lie.com
# 定义发出邮件的域 在99行左右
myorigin = $mydomain
# 定义网卡监听地址(all代表所有) 在116行左右
inet_interfaces = all
# 定义可接收邮件的主机名或域名列表 在164行左右
mydestination = $myhostname , $mydomain
# 信任的客户端 在268行左右
# 必须设置,防止被人当做转发机器
mynetworks = 192.168.0.0/16, 127.0.0.0/8, 100.64.0.0/10
## 如果需要将每份邮件独立存储则, dovecot 也要相应配置 mail_location = maildir:~/Maildir . mkdir /home/user/Maildir
home_mailbox = Maildir/
至此postfix设置完成重启服务并配置开机自启
[root@lie~]# systemctl restart postfix
[root@lie~]# systemctl enable postfix
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| diff /tmp/main.cf.orig /etc/postfix/main.cf
76a77
> myhostname = npcable.cn
83a85
> mydomain = npcable.cn
99a102
> myorigin = $mydomain
113c116
< #inet_interfaces = all
---
> inet_interfaces = all
116c119
< inet_interfaces = localhost
---
> #inet_interfaces = localhost
263a267
> mynetworks = 192.168.0.0/16, 127.0.0.0/8
|
access
http://www.jquerycn.cn/a_7975
https://www.ibadboy.net/archives/676.html
error: 发邮件,结果提示 Relaying denied. IP name lookup failed
vim /etc/mail/access
加入
1
| Connect:0.0.0.0/0 RELAY
|
service sendmail restart
3、配置Dovecot服务程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # 安装dovecot (默认安装就可以)
[root@lie~]# yum install dovecot
# 安装完成修改配置文件
[root@lie~]# vim /etc/dovecot/dovecot.conf
# 去到24行左右注释
protocols = imap pop3 lmtp
# 设置允许登录的网段地址 在50行左右
login_trusted_networks = 0.0.0.0/0 # 必须设置
# 配置邮件格式与存储路径(去掉24行注释)
[root@lie~]# vim /etc/dovecot/conf.d/10-mail.conf
mail_location = mbox:~/mail:INBOX=/var/mail/%u
## 如果需要将每份邮件独立存储则, postfix 也要相应配置 home_mailbox = Maildir/ . mkdir /home/user/Maildir
mail_location = maildir:~/Maildir
# 重启dovecot服务并开机启动
[root@lie~]# systemctl restart dovecot
[root@lie~]# systemctl enable dovecot
|
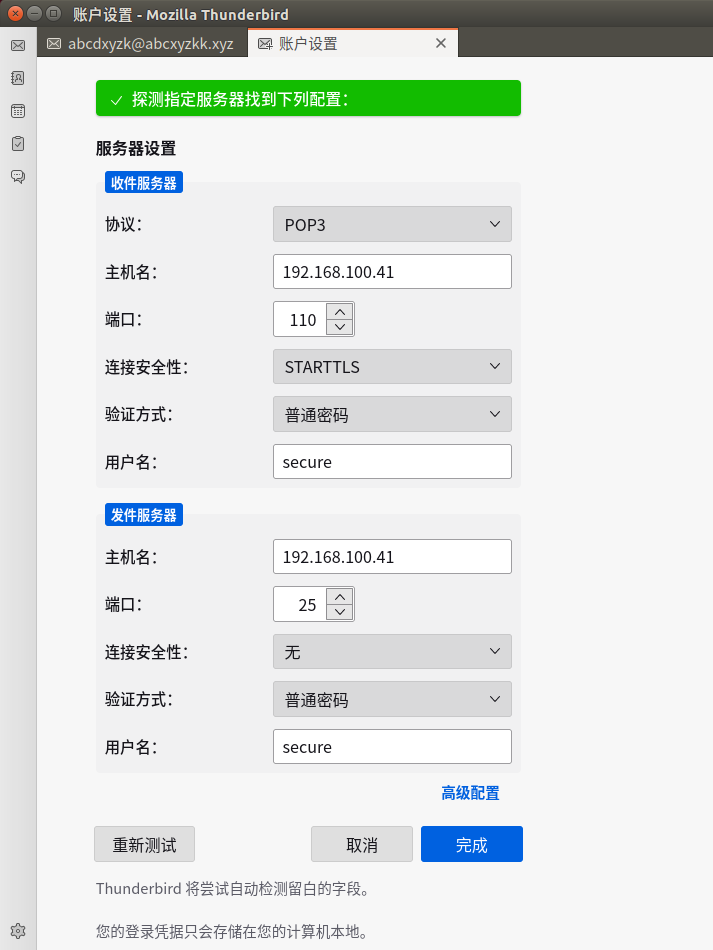
若未设置login_trusted_networks参数值,使用telnet登录110端口,将会出现如下错误,
1
2
3
4
5
| telnet 192.168.50.24 110
Plain text authentication disallowed on non-secure (SSL/TLS) connections.
# tail -f /var/log/maillog
Dec 21 16:51:00 rhel6 dovecot: pop3-login: Aborted login (tried to use disabled plaintext auth): rip=192.168.50.211, lip=192.168.50.24, mpid=0
|
1
2
3
4
5
6
7
| diff /tmp/dovecot.conf.orig /etc/dovecot/dovecot.conf
24c24
< #protocols = imap pop3 lmtp
---
> protocols = imap pop3 lmtp
48a49
> login_trusted_networks = 0.0.0.0/0
|
1
2
3
4
5
| diff /tmp/10-mail.conf.orig /etc/dovecot/conf.d/10-mail.conf
25c25
< # mail_location = mbox:~/mail:INBOX=/var/mail/%u
---
> mail_location = mbox:~/mail:INBOX=/var/mail/%u
|
4、创建电子邮件系统的登录账户
本地系统的账户和密码,因此在本地系统创建常规账户即可
1
2
3
4
| [root@lie~]# useradd test
[root@lie~]# passwd test
#创建立用于保存邮件的目录(开始没创建此目录windows客户端配置账户死活是配置不上)
[root@lie~]# mkdir -p mail/.imap/INBOX
|
至此搭建完成!!!
可以用 thunderbird 或 Foxmail 连接
thunderbird 配置时要特别注意用户名,默认带出来的是邮箱,不对,只要@之前的名称即可
Windows 7客户端安装Foxmail配置test邮箱账户正常收发邮件