

sql中exists和except用法介绍,代替in
https://www.jb51.net/article/230899.htm
一、exists
相对于 inner join,exists 性能要好一些,当它找到第一个符合条件的记录时,就会立即停止搜索返回 TRUE。
EXISTS = IN,意思相同不过语法上有点点区别,好像使用 IN 效率要差点,应该是不会执行索引的原因。
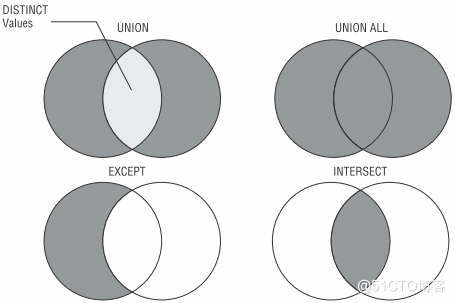
1.1 说明
EXISTS(包括 NOT EXISTS)子句的返回值是一个 BOOL 值。EXISTS 内部有一个子查询语句(SELECT … FROM…),我将其称为 EXIST 的内查询语句。其内查询语句返回一个结果集。
EXISTS 子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
exists:强调的是是否返回结果集,不要求知道返回什么,
比如:
1
| |
只要 exists 引导的子句有结果集返回,那么 exists 这个条件就算成立了,大家注意返回的字段始终为 1,如果改成
1
| |
那么返回的字段就是 2,这个数字没有意义。
所以 exists 子句不在乎返回什么,而是在乎是不是有结果集返回。
1.2 示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
1.3 intersect/2017-07-21
intersect 的作用与 exists 类似。
1 2 3 4 5 6 7 | |
二、except
2.1 说明
查询结果上 EXCEPT = NOT EXISTS,INTERSECT = EXISTS,但是 EXCEPT/INTERSECT 的「查询开销」会比 NOT EXISTS/EXISTS 大很多。
except 自动去重复,not in/not exists不会。
2.2 示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
三、测试数据
其中验证 except 去重复功能时在 family_member 中新增一个 rabbit。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | |
php字符串压缩, MySQL中的BLOB类型
压缩后的字符串是bin类型, mysql不能用char、varchar、text存储
https://blog.51cto.com/u_15470226/5185727
在PHP中偶尔遇到字符串的压缩,比如一个长字符串,数据库开始设计的字段存不下,但是又不想改数据库字段存储长度,就可以用压缩的方式降低数据字段字符串的长度数量级,把几百个字符的字符串压缩到几十个字符。总结下来有以下几个:
压缩函数:gzcompress gzdeflate gzencode
与之对应的解压函数如下:
解压函数:gzuncompress gzinflate gzdecode
特别注意:gzdecode是PHP 5.4.0之后才加入的,使用的时候要注意兼容性问题。
gzcompress gzdeflate gzencode函数的区别在于它们压缩的数据格式不同:
gzcompress使用的是ZLIB格式;
gzdeflate使用的是纯粹的DEFLATE格式;
gzencode使用的是GZIP格式;
1 2 3 4 5 6 7 8 9 10 11 | |
https://blog.csdn.net/weixin_42408447/article/details/117412778
一.BLOB介绍
BLOB (binary large object),二进制大对象,是一个可以存储二进制文件的容器。在计算机中,BLOB常常是数据库中用来存储二进制文件的字段类型。BLOB是一个大文件,典型的BLOB是一张图片或一个声音文件,由于它们的尺寸,必须使用特殊的方式来处理(例如:上传、下载或者存放到一个数据库)。根据Eric Raymond的说法,处理BLOB的主要思想就是让文件处理器(如数据库管理器)不去理会文件是什么,而是关心如何去处理它。但也有专家强调,这种处理大数据对象的方法是把双刃剑,它有可能引发一些问题,如存储的二进制文件过大,会使数据库的性能下降。在数据库中存放体积较大的多媒体对象就是应用程序处理BLOB的典型例子。
二.mysql BLOB类型
MySQL中,BLOB是个类型系列,包括:TinyBlob、Blob、MediumBlob、LongBlob,这几个类型之间的唯一区别是在存储文件的最大大小上不同。
三.MySQL的四种BLOB类型
1 2 3 4 5 | |
四.配置修改
在BLOB中存储大型文件,MYSQL提供了很强的灵活性!允许的最大文件大小,可以在配置文件中设置。
通过etc/my.cnf
1 2 | |