

https://www.modb.pro/db/407727
Nginx做了反向代理,每个域名都应该是做了白名单。
什么是HTTP Host头?
从HTTP/1.1开始,HTTP Host头就是强制性的请求标头。比如我们要访问这个URL时
http://www.website.net/websecurity
浏览器会编写个Host标头的请求,"GET"请求的是页面的相对路径,"Host"就是主机头,请求的是域名或服务器地址:
1 2 | |
HTTP Host头的用处?
HTTP Host头的目的是帮助识别客户端想要与哪个后端组件通讯。
其实在以前,并不会有通讯错误的问题,因为每个IP地址通常只对应一个域名。
但是随着云和虚拟主机的普及,单个Web服务器可以托管多个网站或应用程序。尽管这些网站都有各自不同的域名,但很有可能共享服务器同一个IP地址,这种情况下就需要通过Host头来进行区分了。
另外种情况就是后端网站可能是托管在不同的服务器上,但是客户端和服务器之间的所有流量都要通过中间系统,比如用了负载均衡或是反向代理。在这种场景下,所有的域名都会解析为中间组件的IP,所以中间组件需要通过Host头来判断每个请求是到后端哪个服务器上。
就好比给住在公寓楼里的人寄快递,整栋大楼都有相同的街道地址,但在这个街道地址后面有许多不同的公寓,每个公寓都需要以某种方式接收正确的快递。解决此问题的一种方法是简单地在地址中包含公寓号码或收件人姓名。对于 HTTP 消息,Host 头也是类似的作用。
如何利用Host头来进行攻击?
如果网站没有以安全的方式来处理Host值的话,就极易受到攻击。一般Web应用程序通常不知道它们部署在哪个域上,当它们需要知道当前域时,很有可能会求助于Host头。如果服务器完全信任Host头,没有验证或转义它的值,攻击者可以把有害的Payload放入其中,当应用程序调用的时候,有害的Payload可能就会传导进去造成“注入”。
而这种漏洞可以造成包括:Web缓存中毒、特定功能的业务逻辑缺陷、基于路由的SSRF、SQL注入等危害。
要检测一个站点是否有这个漏洞的话有个最简单的方法就是通过BurpSuite这类工具,在客户端发送包的时候对Host进行修改,随后看是否还可以请求到目的应用程序。如果还可以正常请求到,那就说明存在注入点。
像这里,把Host完全改了,网站还可以返回200,显示正常页面
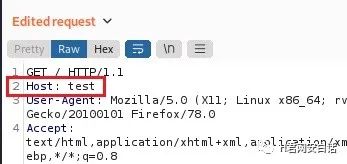
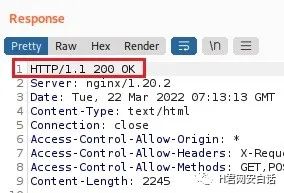
如何绕过有缺陷Host头检查?
通常来说,很少有站点会出现上面这种完全放开的现象,一般或多或少都有些过滤机制,但如果过滤做的不好,就会存在被绕过的可能性。
① 忽略端口的检验
某些过滤检查只验证域名,会忽略Host头中的端口。如果我们可以在Host头中写入非数字端口,就可以通过端口注入恶意Payload。
1 2 | |
② 允许任意子域
如果应用系统允许其域名下任意的子域通过,在这种情况下,可以通过子域来绕过验证。
1 2 | |
③ 注入重复的Host头
有的时候我们可以添加多个Host头,而且一般开发者并没有预料到这种情况而没有设置任何处理措施,这就可能导致某个Host头会覆盖掉另一个Host头的值
1 2 3 | |
如果服务器端将第二个Host头优先于第一个Host头,就会覆盖掉它的值,然后中转组件会因为第一个Host头指定了正确的目标而照常转发这个请求包,这样就能绕过中间组件将Payload传递给服务器。
④ 提供绝对URL
正常情况下,"GET"的请求航采用的是相对地址,但是也允许使用绝对地址,就是将原本Host的值拼接到相对地址前面构成绝对地址,这样就可以利用Host头进行注入。
1 2 | |
⑤ 添加换行
有时候还可以通过使用空格字符缩进HTTP头来进行混淆,因为有些服务器会将缩进的标头理解为换行,而将其视为前面头值的一部分,有些服务器会完全忽略缩进的HTTP头,因此不同系统处理HTTP头可能会存在不一致的现象。
1 2 3 | |
如果前端忽略缩进的头部,这个请求会被作为普通请求来处理。假设后端忽略前导空格优先考虑第一个Host头,这种不一致性会导致Payload的注入。
⑥ 利用可覆盖Host的请求头
有一些请求头的值是可以覆盖Host的值的,比如X-Forwarded-Host,当我们发出这样的请求时就会触发覆盖
1 2 3 | |
可以达到相同目的的还有这些头
1 2 3 4 | |
如何防止HTTP Host头攻击?
要防止HTTP Host头攻击,最简单的方法就是避免在服务器端代码中完全使用Host头,不进行任何引入。如果确实要使用Host值的话,还有些其他的方法:
① 保护绝对URL
当必须要使用绝对URL时,应该在配置文件中手动指定当前域进行引用,而不是直接引用Host值。
② 验证Host头
如果必须使用Host头,确保进行正确的验证。应该根据允许域的白名单进行检查,并拒绝任何无法识别的主机请求。
③ 不支持Host覆盖头
检查下是否不支持可用于构建这些攻击的其他头也很重要,特别是X-Forwarded-Host,默认情况下可能支持这些功能。
④ 白名单允许的域
为了防止对内部服务器基于路由的攻击,在配置负载均衡或反向代理后,通过白名单允许域对请求进行转发。
⑤ 小心使用仅限内部访问的虚拟主机
使用虚拟主机时,应避免在同一服务器上托管仅供内部使用的网站和应用程序作为面向公众的内容。攻击者有可能能够通过Host头操作访问内部域。