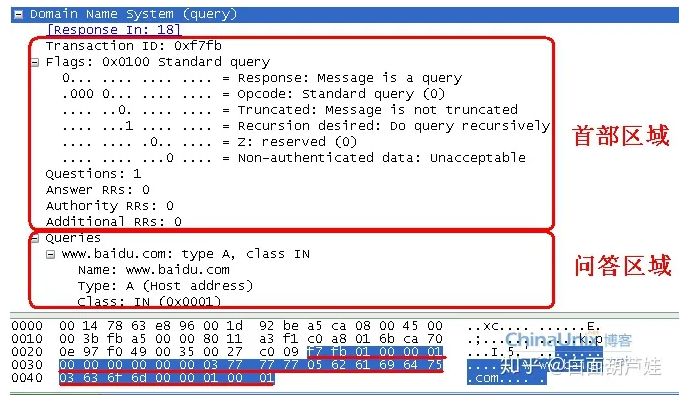
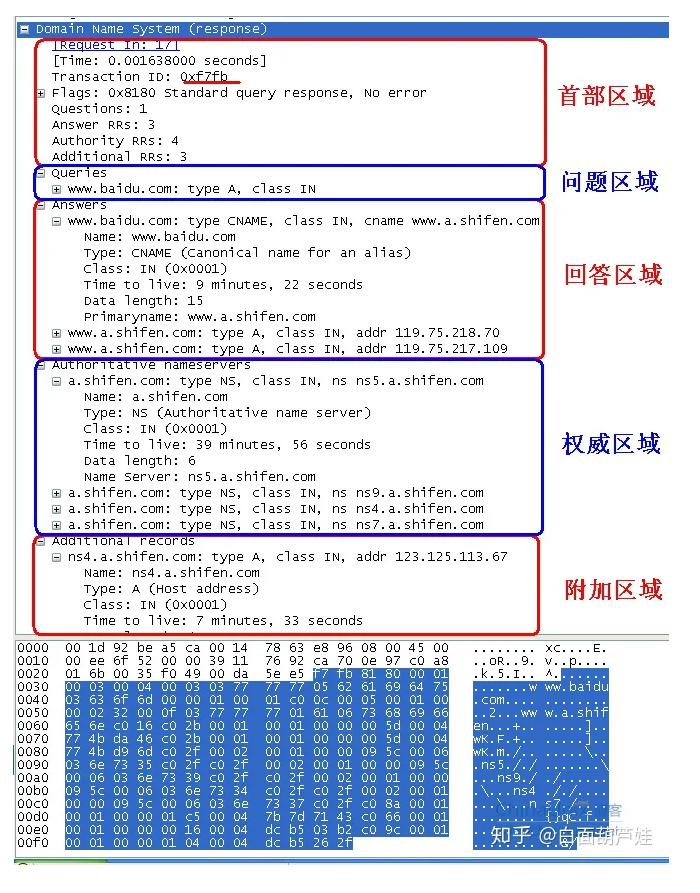
https://blog.51cto.com/u_14398214/5071045
http://events.jianshu.io/p/1cdefa50f58d
https://zhuanlan.zhihu.com/p/143360037
14.3 DNS的报文格式
DNS 定义了一个用于查询和响应的报文格式。图 14-3 显示这个报文的总体格式。
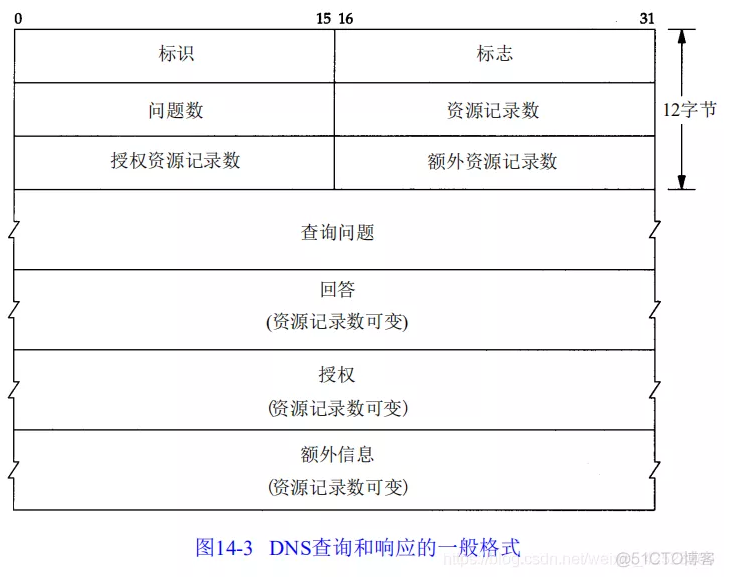
这个报文由 12 字节长的首部和 4个长度可变的字段组成。标识字段由客户程序设置并由服务器返回结果。客户程序通过它来确定响应与查询是否匹配。
16 bit的标志字段被划分为若干子字段,如图 14-4 所示。

我们从最左位开始依次介绍各子字段:
• QR 是 1 bit 字段:0表示查询报文,1表示响应报文。
• opcode 是一个 4 bit 字段:通常值为0(标准查询),其他值为1(反向查询)和2(服务器状态请求)。
• AA 是1 bit标志,表示“授权回答 (authoritative answer)”。该名字服务器是授权于该域的。
• TC 是1 bit字段,表示“可截断的 (truncated)”。使用U D P时,它表示当应答的总长度超过 512 字节时,只返回前 512 个字节。
• RD 是1 bit字段表示“期望递归( recursion desired)”。该比特能在一个查询中设置,并在响应中返回。这个标志告诉名字服务器必须处理这个查询,也称为一个递归查询。如果该位为0,且被请求的名字服务器没有一个授权回答,它就返回一个能解答该查询的其他名字服务器列表,这称为迭代查询。在后面的例子中,我们将看到这两种类型查询的例子。
• RA 是 1 bit 字段,表示“可用递归”。如果名字服务器支持递归查询,则在响应中将该比特设置为1。在后面的例子中可看到大多数名字服务器都提供递归查询,除了某些根服务器。
• 随后的 3 bit 字段必须为0。
• rcode 是一个 4 bit 的返回码字段。通常的值为 0(没有差错)和3(名字差错)。名字差错只有从一个授权名字服务器上返回,它表示在查询中制定的域名不存在。
随后的 4 个 16 bit 字段说明最后 4个变长字段中包含的条目数。对于查询报文,问题(question)数通常是1,而其他3项则均为0。类似地,对于应答报文,回答数至少是 1,剩下的两项可以是0或非0。
14.3.1 DNS查询报文中的问题部分
问题部分中每个问题的格式如图 14-5 所示,通常只有一个问题。

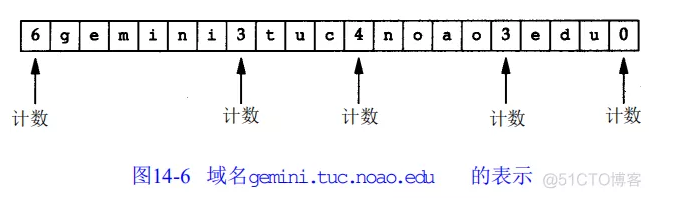
查询名是要查找的名字,它是一个或多个标识符的序列。每个标识符以首字节的计数值来说明随后标识符的字节长度,每个名字以最后字节为 0结束,长度为0的标识符是根标识符。计数字节的值必须是 0 ~ 63 的数,因为标识符的最大长度仅为 63(在本节的后面我们将看到计数字节的最高两比特为1,即值 192 ~ 255,将用于压缩格式)。不像我们已经看到的许多其他报文格式,该字段无需以整 32 bit 边界结束,即无需填充字节。
图 14-6 显示了如何存储域名 gemini.tuc.noao.edu。
每个问题有一个查询类型,而每个响应(也称一个资源记录,我们下面将谈到)也有一个类型。大约有 20 个不同的类型值,其中的一些目前已经过时。图 14-7 显示了其中的一些值。查询类型是类型的一个超集 (superset):图中显示的类型值中只有两个能用于查询类型。
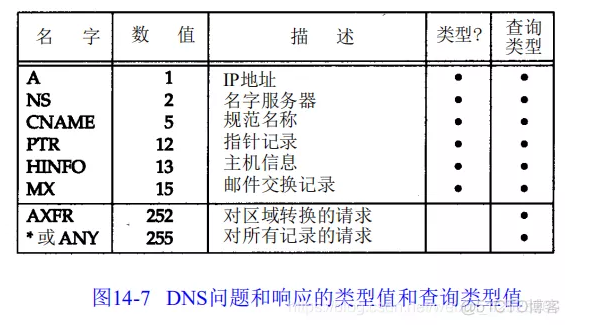
最常用的查询类型是 A类型,表示期望获得查询名的 IP 地址。一个 PTR 查询则请求获得一个 IP 地址对应的域名。这是一个指针查询,我们将在 14.5 节介绍。其他的查询类型将在 14.6 节介绍。
查询类通常是1,指互联网地址(某些站点也支持其他非 IP地址)
14.3.2 DNS响应报文中的资源记录部分
DNS报文中最后的三个字段,回答字段、授权字段和附加信息字段,均采用一种称为资源记录R R(Resource Record)的相同格式。图14-8显示了资源记录的格式。
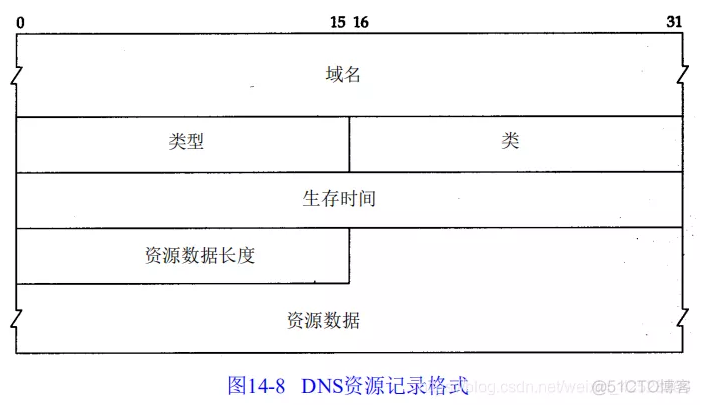
域名是记录中资源数据对应的名字。它的格式和前面介绍的查询名字段格式(图 14-6)相同。
类型说明 RR的类型码。它的值和前面介绍的查询类型值是一样的。类通常为 1,指Internet数据。
生存时间字段是客户程序保留该资源记录的秒数。资源记录通常的生存时间值为 2天。资源数据长度说明资源数据的数量。该数据的格式依赖于类型字段的值。对于类型 1(A记录)资源数据是4字节的IP地址。
应答部分(Answer、Authority、Additional)
| 报文 |
中文 |
长度 |
说明 |
| NAME |
|
0x00结束 |
|
| TYPE |
查询类型 |
2 |
|
| CLASS |
查询类 |
2 |
|
| TimeToLive |
生存时间 |
4 |
|
| DaTaLength |
资源数据长度 |
2 |
|
| DaTa |
资源数据 |
DaTaLength |
|
1.2.1、QTYPE说明
| 类型 |
助记符 |
说明 |
| 1 |
A |
由域名获得IPv4地址 |
| 2 |
NS |
查询域名服务器 |
| 3 |
MD |
过期类型 |
| 4 |
MF |
过期类型 |
| 5 |
CNAME |
查询规范名称 |
| 6 |
SOA |
开始授权 |
| 7 |
MB |
指定邮箱域名 |
| 8 |
MG |
指定邮件组成员 |
| 9 |
MR |
指定邮件重命名域名 |
| A |
NULL |
指定空的资源记录 |
| B |
WKS |
熟知服务 |
| C |
PTR |
把IP地址转换成域名 |
| D |
HINFO |
主机信息 |
| E |
MINFO |
指定邮箱或列表信息 |
| F |
MX |
邮件交换 |
| 10 |
TXT |
文本信息 |
| 28 |
AAAA |
由域名获得IPv6地址 |
| 252 |
AXFR |
传送整个区的请求 |
| 255 |
ANY |
对所有记录的请求 |
1.2.2、QCLASS说明
| 数值 |
类型 |
说明 |
| 01 |
IN |
Internet类别 |
| 02 |
CSNET |
过期类型 |
| 03 |
Chaos |
|
| 04 |
MIT Athena Hesiod |
|
DNS查询报文实例