https://blog.csdn.net/m0_67373568/article/details/125332615
一、HTTPS
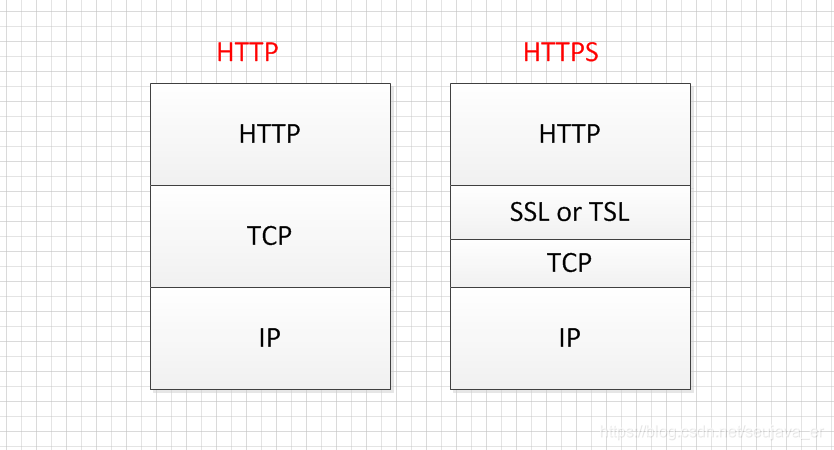
HTTP协议:超文本传输协议,明文传输,客户端与Web服务器间的应用层通信协议。
HTTPS协议:HTTP+SSL/TLS,即HTTP下加入SSL层,使用SSL加密,用于安全的HTTP传输,https默认使用端口443。
SSL:安全套接字层,位于可靠的面向连接的网络层协议。SSL通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。具有数据加密和身份验证的功能。
TLS:安全传输层协议、对SSL扩展和优化,提供数据安全的同时,确保数据的完整性。
https流程:
https作为一种安全的应用层协议,使用了以下三种加密手段:
数据正文数据量较大,适用于对称加密,因为对称加密速度快,适用于大量数据加密,但是安全级别低,密钥在网络中传输的过程中容易被窃取,所以对这个密钥进行非对称加密。
最后由于非对称加密的公钥在网络中传输,保证接收方接收到正确的公钥,使用证书验证:
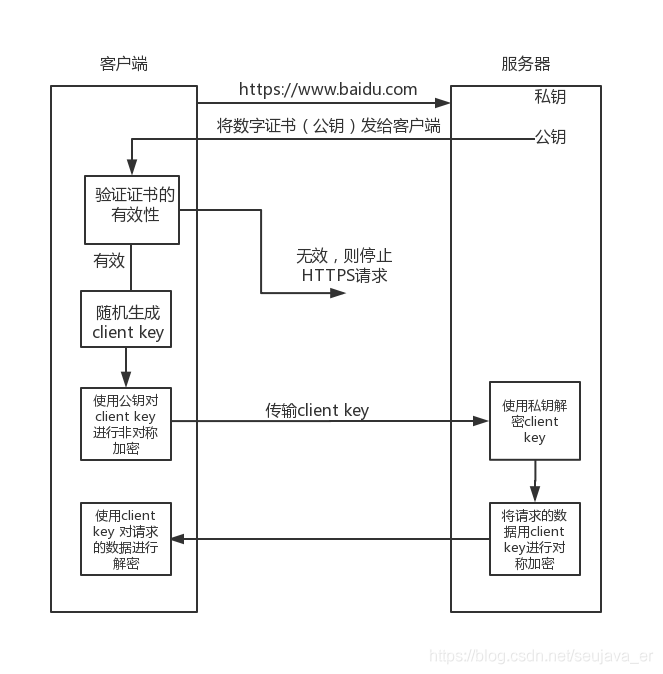
1、客户端发送HTTPS请求。
2、服务器收到请求后,返回数字证书(数字签名+公钥)。
3、客户端验证证书是否合法(用服务端的公钥验签),不合法则提示警告。
4、验证合法后,本地生成密钥(对称加密密钥)并用服务端的提供的公钥加密后发送给服务端。
5、服务端用自己的私钥对数据解密,得到客户端密钥(对称加密密钥),再用客户端密钥对要发送的数据进行加密后发给客户端。
总结:
发送https请求后,先验证CA证书是否和好,再生成本地密钥(对称密钥),使用服务端公钥加密对称密钥再发送服务端。服务端用自己的私钥解密后,取得对称密钥,此时就可以数据传输了,服务端用对称密钥对请求数据加密,发送给客户端,客户端收到后用对称密钥解密拿到明文。
用基于数字证书的非对称加密 加密 对称加密的密钥后 加密传输数据。
一、加密方式
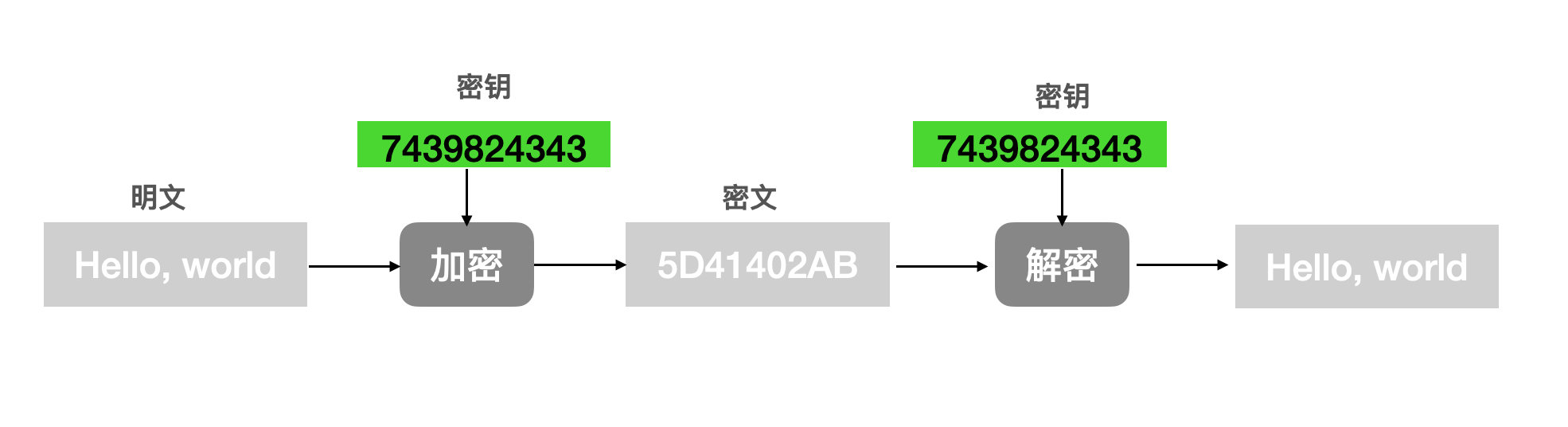
1、对称加密:
私钥加密,信息的发送方和接收方使用同一个密钥加密和解密数据。
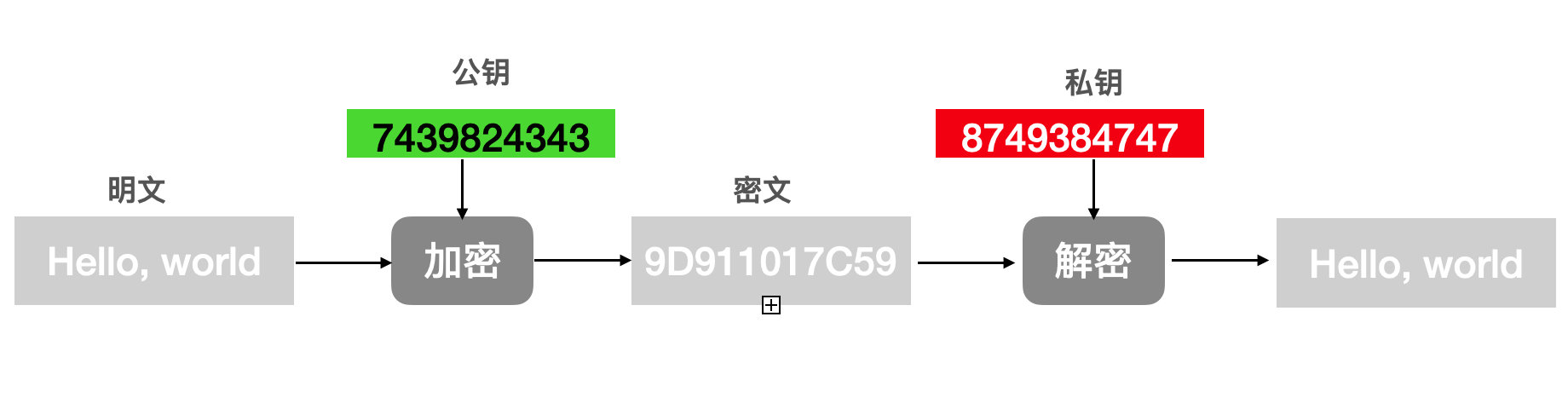
2、非对称加密:
生成两把密钥公钥和私钥。私钥自己保存,公钥用于公开。可以用公钥和私钥中任何一个进行加密,另一个解密。
具体有两种情形:
(1)对方用你的公钥加密信息,你收到后用私钥解开。
只有你有私钥,所以只有你能解开,换句话说,有私钥才能看到信息,很安全。
(2)你拿私钥加密信息,对方收到后用你的公钥解开。
公钥是公开的,所以其他人也可以看到你的信息,不保密。
私钥加密,只有对应公钥能解开。既然用你的公钥能解开,说明加密一定是你的私钥。私钥只有你有,所以一定是你发送的,你不可抵赖。
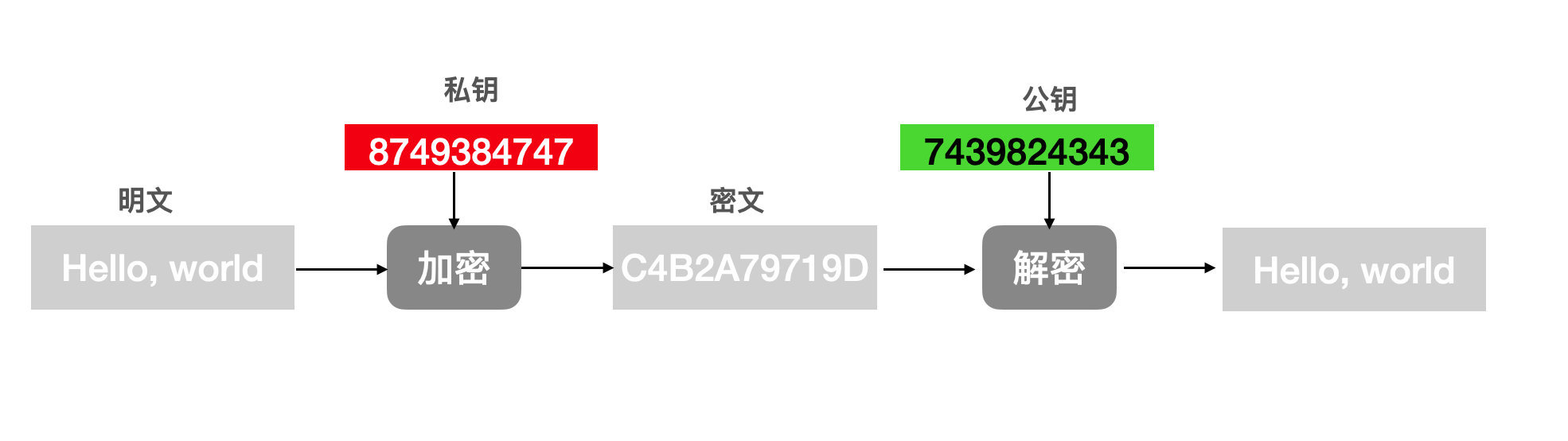
这里的私钥加密指的是私钥签名,公钥验签
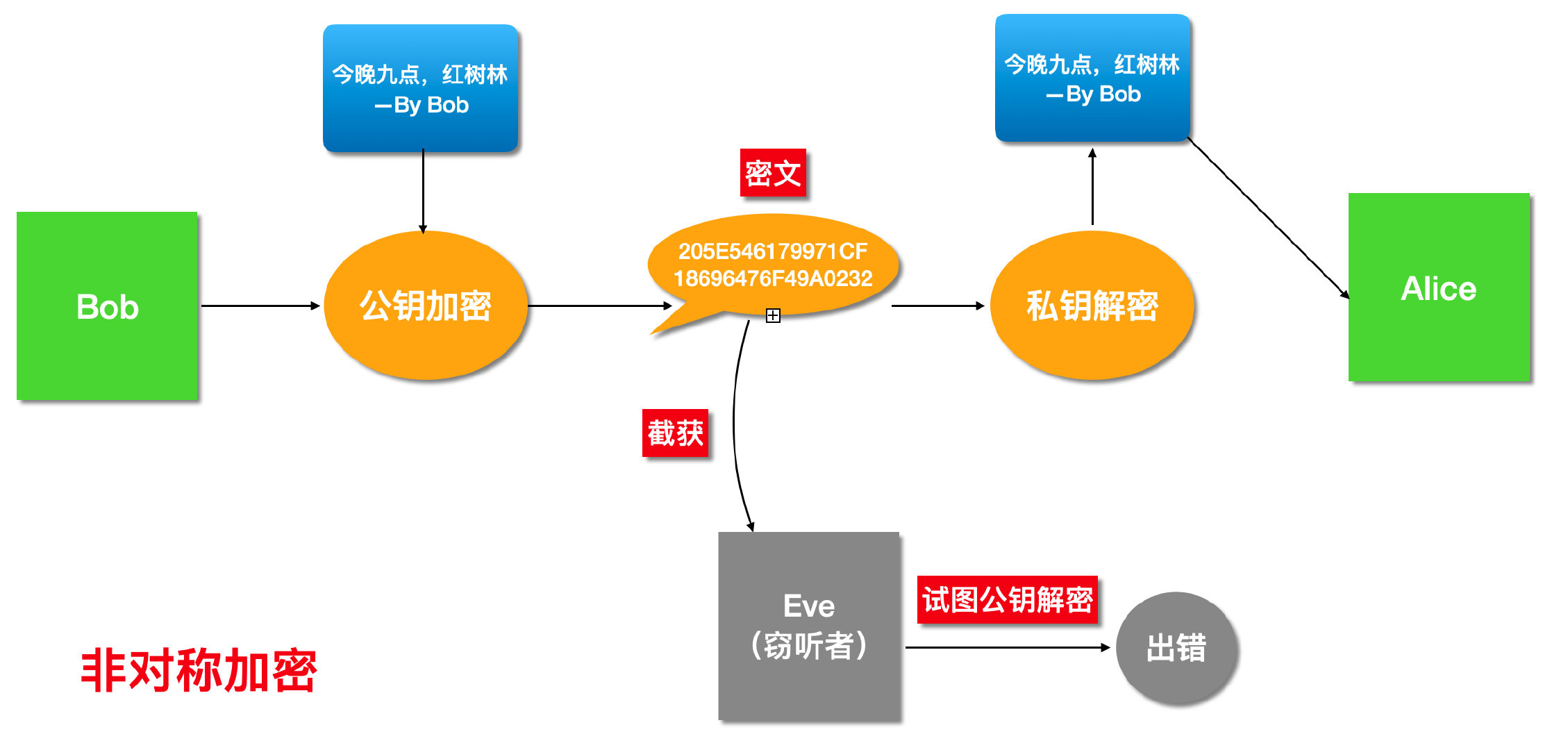
但是这样存在一个问题,窃听者也可以冒充客户端Bob给服务器Alice送信,因为Alice的公钥是公开的,这样就无法分辨哪个是真Bob的送信。
3、数字签名:
为了表明信息没有伪造,确实是信息拥有者发出。可以使用数字签名。
客户端Bob生成一对私钥、公钥。用自己的私钥对消息加密作为签名,再与消息一起发送,接收者用Bob的公钥验签。
窃听者窃取冒充Bob的签名篡改内容也没用,因为内容发生改变时,对应的签名也要重新计算,签名的生成必须使用私钥,只要私钥不泄露,签名就不会被冒充。
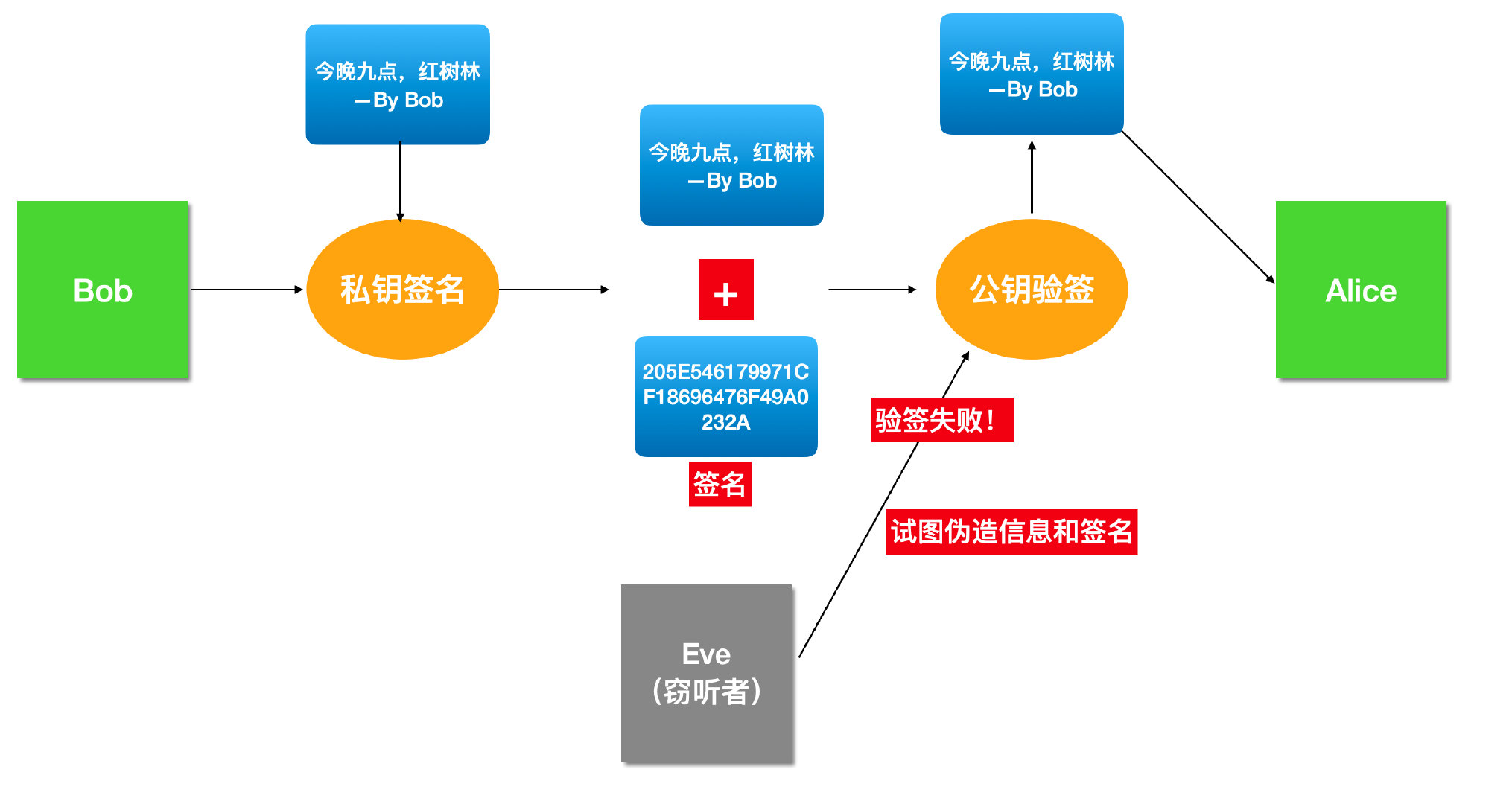
但是数字签名只是能验证发送方身份,未对报文进行加密。窃听者截取到密文并指定发送者的身份时,可通过查阅手册即可获得发送者的公钥PKA,就可以窃听报文的内容。
4、数字证书(公钥的数字签名):
发送方可以去证书中心CA为公钥做认证,证书中心用自己的私钥,对需要加密的公钥和一些相关信息一起加密,生成"数字证书"。
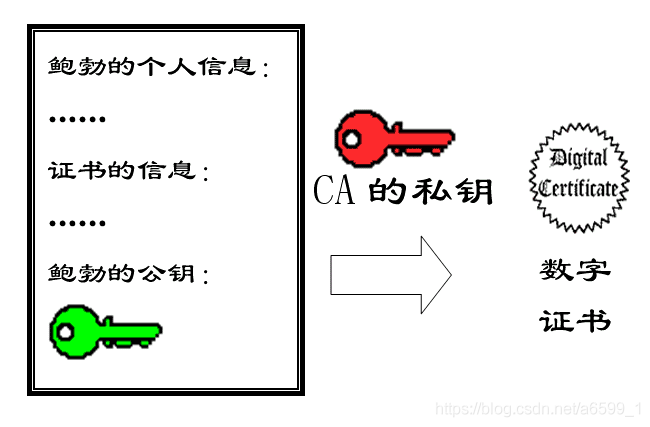
这样接收方就可以防止收到假的公钥,接收方收到带有数字证书的消息后,用CA的公钥先解开数字证书,就可以拿到发送方真实的公钥了。
5、非对称算法的数字签名:
即实现数字签名又加密传输,就可以使用A私钥签名B公钥加密的方法。
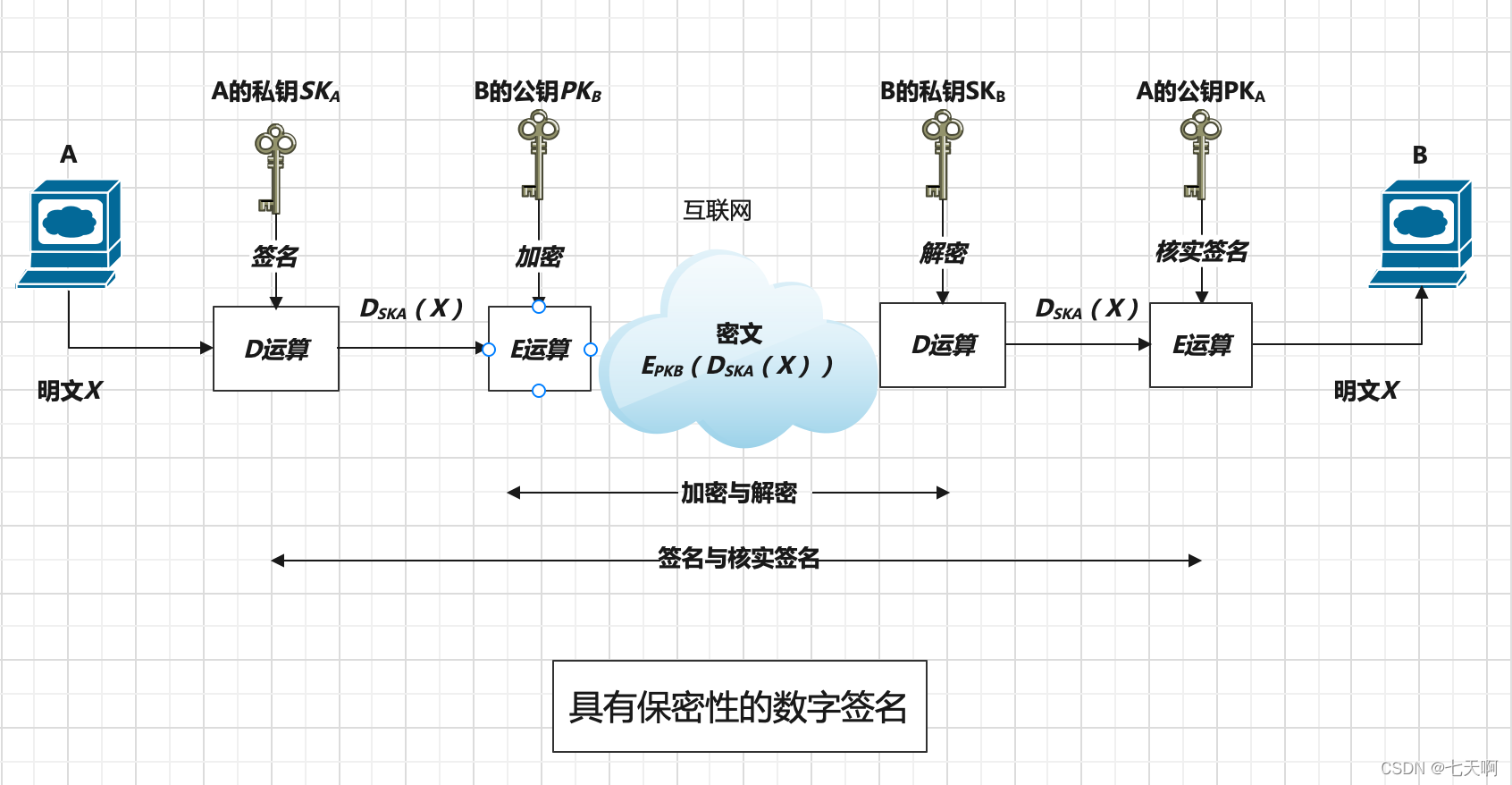
发送者使用自己的私钥对消息加密作为签名,再使用接收方的公钥对消息进行加密,接收方使用自己的私钥进行解密后,再对签名进行验签。
6、hash算法的数字签名(摘要+数字签名):
一般而言,不会直接对数据本身计算数字签名,因为数字签名属于非对称加密,非对称加密依赖于复杂的数学运算,耗时久。所以使用摘要,并且摘要最好是不可逆转的,一般使用开头MD5作为Hash函数,MD5输出的结果固定位128位。
并且要对数据的「摘要」进行签名,这样,窃听者就算解开签名,拿到的也是「摘要」,如果摘要是不可逆转的,也就是无法从摘要反推出原文,也就达到了保密的作用。
首先将原数据进行Hash计算,得到摘要,再对摘要私钥加密生成数字签名。再与原文件一起发送。接收方收到后先用A的公钥对数字签名解密得到摘要1,证明确实是A发送,再对原文进行相同的hash计算得到摘要2,再进行比较,一致则证明消息未被篡改过。
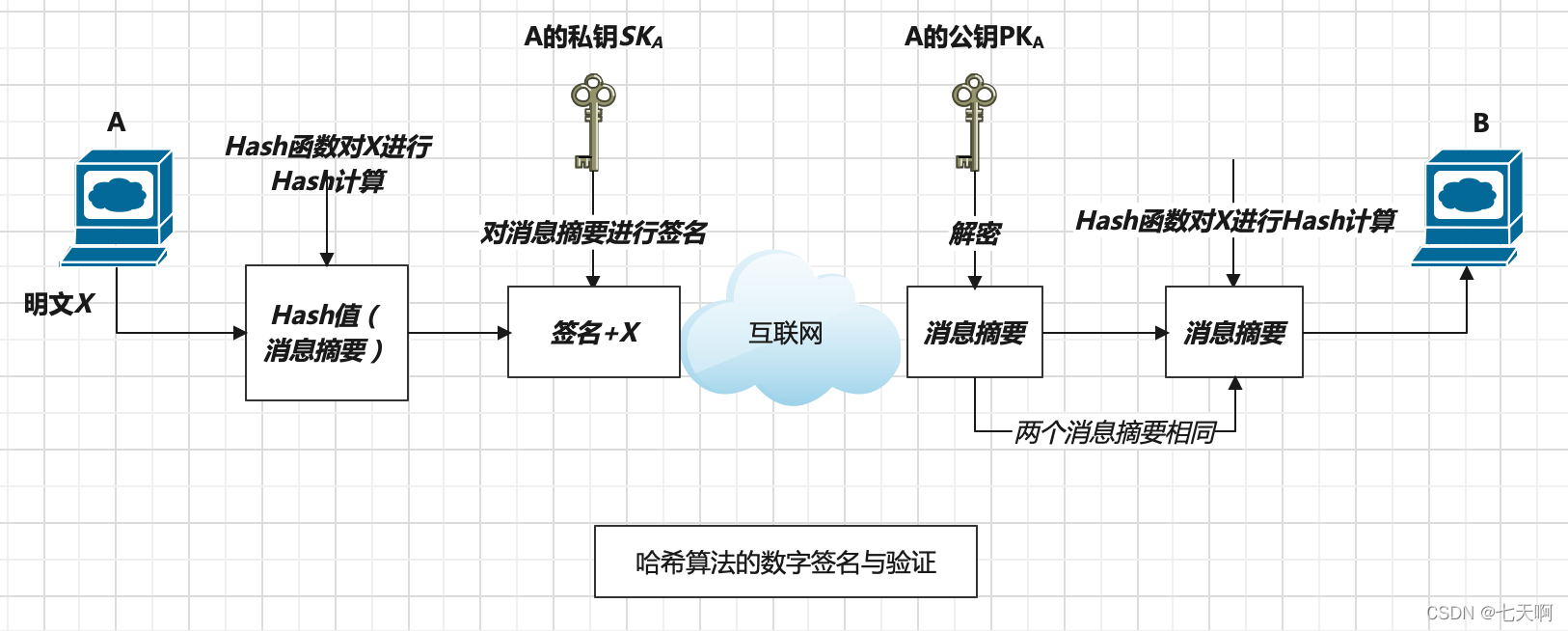
但是若是窃听者将自己的公钥换走了发送方的公钥,再冒充发送方给B发送消息,用自己的私钥做成假的签名,此时接收方无法判断哪个是真正的消息。
总结:
对称加密:同一个密码加密解密。
非对称加密:私钥加密,公钥解密或者私钥加密,公钥解密。
摘要:对消息hash计算生成摘要。
数字签名:私钥加密消息作为签名,再与源文件一起发送。
数字证书:证书中心对验签的公钥进行加密,生成数字证书。用CA的公钥解密得到加密的公钥。
hash算法的数字签名:对消息hash计算后再私钥加密生成数字签名。数字签名+原文件一起发送。接收方再进行比较。
非对称加密的数字签名:发送用私钥加密得到数字签名,再使用接收方的公钥加密原文,一起发送,接收方使用发送方的公钥验签,证明是本人发送,再使用私钥解密原文,进行比较。一致则未被篡改。