git ssh url port
1 2 3 4 5 6 7 8 9 10 11 | |


git ssh url port
1 2 3 4 5 6 7 8 9 10 11 | |
wget https://repos.influxdata.com/rhel/8/x86_64/stable/kapacitor-1.6.4-1.x86_64.rpm
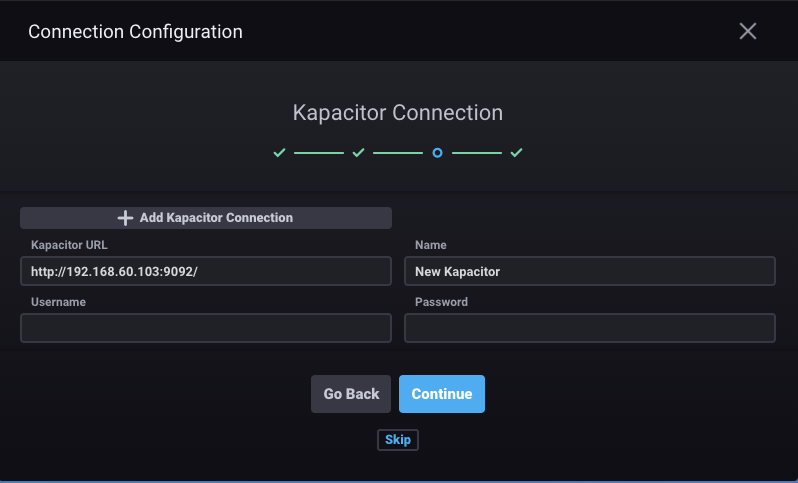
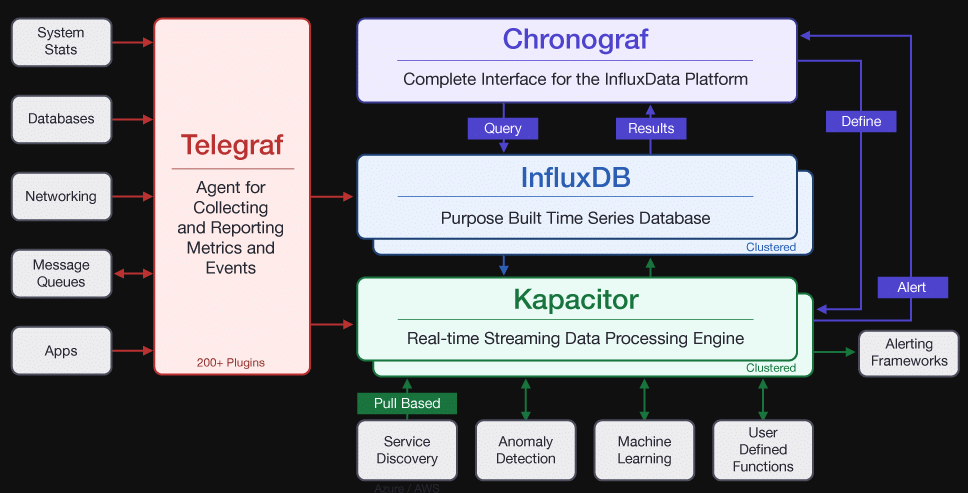
kapacitor属于TICK技术栈中的K,它定位为流式数据分析框架,包括数据源订阅,数据处理,预警检测与事件输出
1 2 3 4 5 6 7 8 | |
| 名词 | 说明 | 同比influxdb |
|---|---|---|
| task | 数据计算规则,由一系列节点node形成的数据处理的有向无环图DAG | 无 |
| task template | 同上,通过模版变量来定制task | 无 |
| topic | 预警检测程序-如果没有显示在alert中用topic指定,会用程序的alert node来代替 | 无 |
| event | 触发的报警事件 | 无 |
| handler | 报警事件输出程序 | 无 |
| topic handler | 报警事件的输出有两种方式,一种是alert node的属性方法直接调用,一种是通过alert指定topic与yaml描述文件来定义 | 无 |
| record | 数据录制 | 无 |
| replay | 数据回放 | 无 |
| name | 度量名 | measurement |
| tags | 标签 | tag key tag field |
| columns | 字段 | field key |
| values | 字段值 | field value |
| series | 数据序列 | series |
| string template | 字符串模版,借鉴了go语言 | |
| lambda | 函数表达式 |
wget https://repos.influxdata.com/rhel/8/x86_64/stable/chronograf-1.9.1.x86_64.rpm
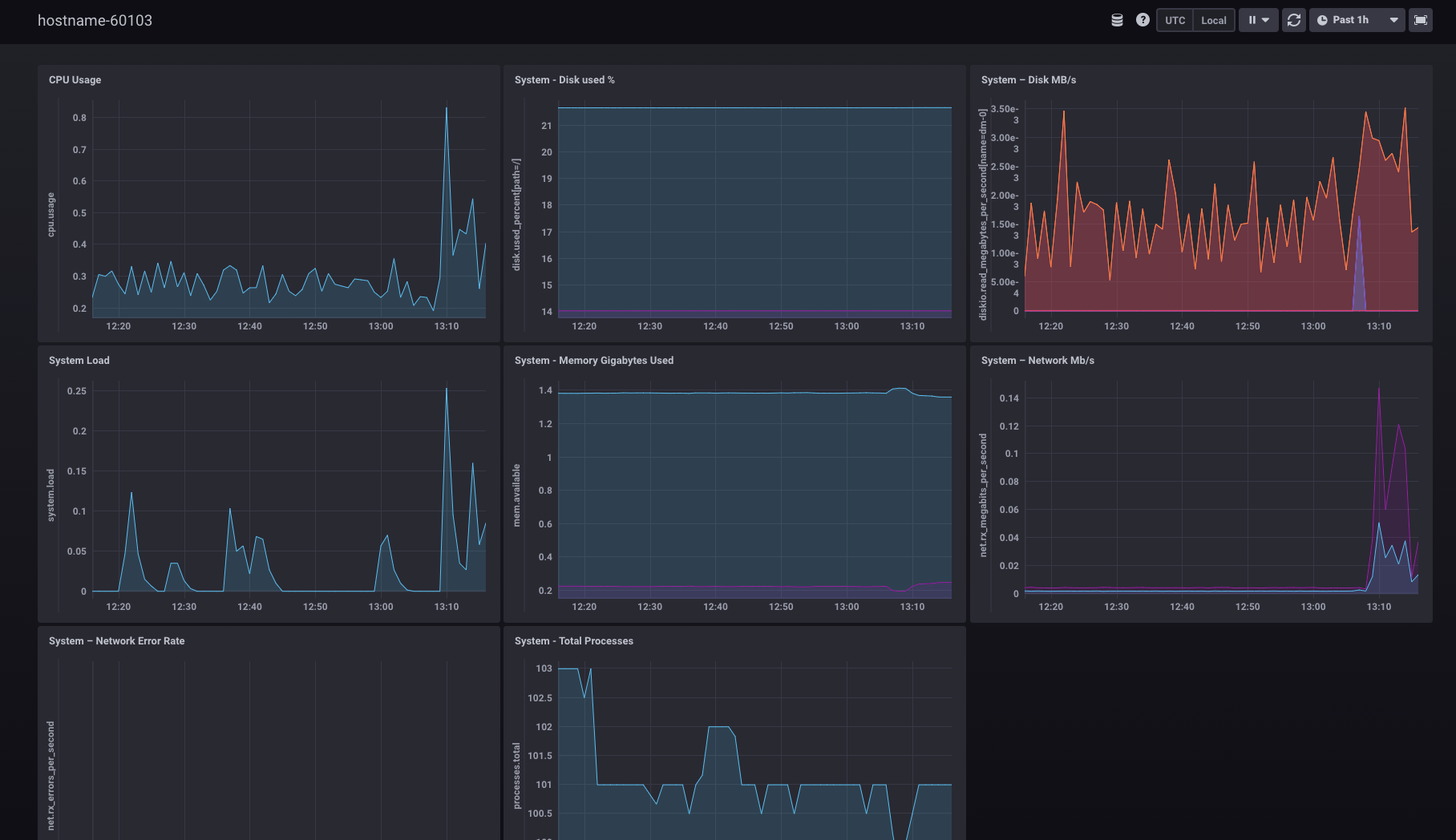
Chronograf是InfluxData的TICK堆栈的用户界面组件。它使您的基础架构的监控和警报易于设置和维护。