https://www.cnblogs.com/chenglee/p/10383885.html
用途:系统无法进入,如grub损坏或某个配置文件改错
进入系统安装盘界面,先选Troubleshooting,再选Rescue installed system
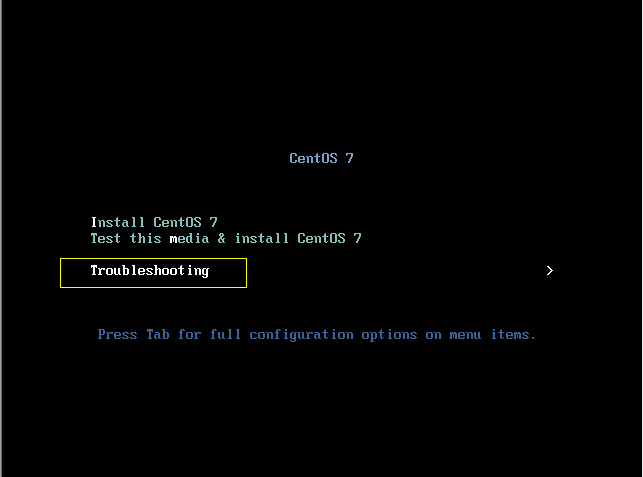

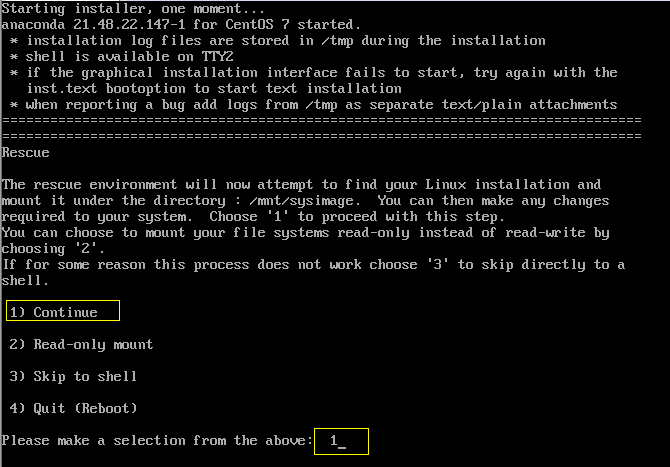
进入后等待最终进入提示模式,输入 1 或 3 回车
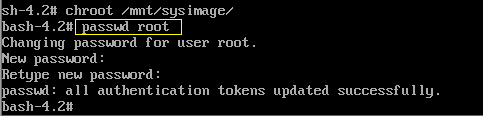
然后输入chroot /mnt/sysimage 切换到原linux系统,切换后前缀会变为bash ,然后就可以修改root密码或配置文件了


https://www.cnblogs.com/chenglee/p/10383885.html
用途:系统无法进入,如grub损坏或某个配置文件改错
进入系统安装盘界面,先选Troubleshooting,再选Rescue installed system
进入后等待最终进入提示模式,输入 1 或 3 回车
然后输入chroot /mnt/sysimage 切换到原linux系统,切换后前缀会变为bash ,然后就可以修改root密码或配置文件了
https://www.zhihu.com/question/21936554
美日欧几大电信运营商创立的OMTP(开放移动终端平台)发布的标准,即我们常说的OMTP标准;
CTIA(美国无线通信和互联网协会)发布的标准,即CTIA标准,或者俗称AHJ(美国头戴耳机插孔)标准。
这两种标准不约而同地采用了对3.5mm耳机进行扩展的方案。两者在电气性能上没有根本差别,唯一的差异就在于最内侧两环的接线是相反的:
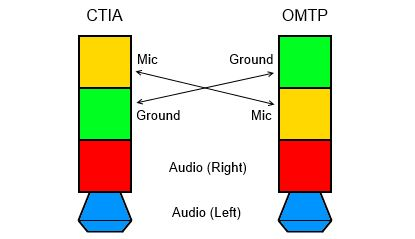
CTIA由外向内分别是耳机左声道、耳机右声道、地线、麦克风;
OMTP由外向内分别是耳机左声道、耳机右声道、麦克风、地线。
这就导致了两者的不兼容。如果把OMTP耳机插在只支持CTIA的设备上,要么没有声音,要么只有一边耳机有声音,麦克风完全无效。
HTML特殊字符不包括TAB. TAB应该也可以用	表示. 但只有在<PRE>...</PRE>这样的标记内部才起作用. 其他地方只相当于一个空格. 这和 不一样