https://www.jianshu.com/p/caba04b57258
使用phpword生成文档有两种方式
直接使用代码编写word文档,用代码生成word,但是设置样式,格式,图片非常麻烦,不建议使用。如果客户或产品提供一份word的样式,我们也难以完全复原,调样式很头疼的。
读取原有word模板,替换相关变量。个人感觉这种方式能满足绝大部分需求,实现起来也比较简单,所有的样式,格式直接在word模板里设置好,替换变量就可以了,还可以很方便的切换模板。本文主要介绍这种方式,毕竟我们是为了快速实现客户的需求,让客户提供一份word模板,我们稍微一改就可以了。
通过composer安装phpword包
1
2
composer require phpoffice/phpword
# composer remove phpoffice/phpword # 卸载
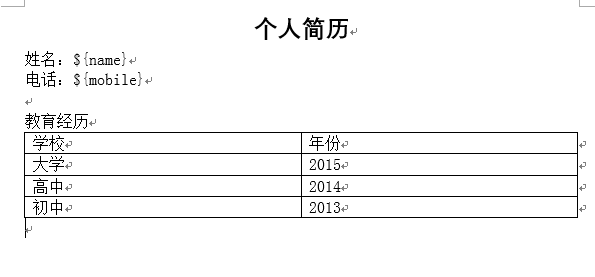
准备一个docx格式的word模板
首先替换姓名,电话的值为 ${name}, ${mobile}
开始替换变量
1
2
3
4
5
6
include_once "vendor/autoload.php";
$tmp = new \PhpOffice\PhpWord\TemplateProcessor('tmp.docx'); //打开模板
$tmp->setValue('name', '李四'); //替换变量name
$tmp->setValue('mobile', '18888888888'); //替换变量mobile
$tmp->saveAs('简历.docx'); //另存为
行数不确定替换
这需要用的克隆行,模板修改如下
这里要记住的是表格左上角的变量school,这个变量用来控制你要复制的是哪一行,复制以后会生成类似于school#1,year#1,school#2,year#2,school#3,year#3 这样的变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$arr=[
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
['school'=>'大学','year'=>'2014'],
];
$rows = count($arr); //总行数
$tmp->cloneRow('school', $rows); //复制行
for ($i = 0; $i < $rows; $i++) {
$tmp->setValue("school#".($i+1), $arr[$i]['school']); //替换变量
$tmp->setValue("year#".($i+1), $arr[$i]['year']);
}
如果有显示这一块,如果没有整个不显示
要加一个块标签了,与html标签格式类似,成对出现,如下
1
2
3
4
${WIN_BLOCK}
获奖情况
${winning_record}
${/WIN_BLOCK}
当winning有值是显示win_block模块,并渲染winning_record,没有值是不显示win_block模块
1
2
3
4
5
6
7
8
$winning_record = "";
if ($winning_record != '') {
$tmp->cloneBlock('WIN_BLOCK', 1);
$tmp->setValue('winning_record', $winning_record);
} else {
#$tmp->deleteBlock('WIN_BLOCK'); //这个方法会出错,原因不知,用cloneBlock来代替
$tmp->cloneBlock('WIN_BLOCK', 0);
}
替换图片
1
2
3
4
5
$tmp->setImageValue('header',['path'=>'1.jpeg']);
设置图片宽高
$tmp->setImageValue('header', ['path' => '1.jpg','width'=>500,'height'=>500]);
设置多次替换
$tmp->setImageValue('header', ['path' => '1.jpg','width'=>500,'height'=>500],3);
一些常用的word符号
换行符 <w:br/><w:br w:type="page"/><w:tab/>&,可以使用htmlspecialchars()
使用方式
比如我们数据库存的换行符一般是 \n\r 这个在word中是无效的,要替换为 <w:br/> 才行
1
2
$content = str_replace("\r\n", '<w:br />', $content);
$tem->setValue('content', $content); //内容