http://simohayha.iteye.com/blog/578744
上一篇处理ack的blog中我们知道当我们接收到ack的时候,我们会判断sack段,如果包含sack段的话,我们就要进行处理。这篇blog就主要来介绍内核如何处理sack段。
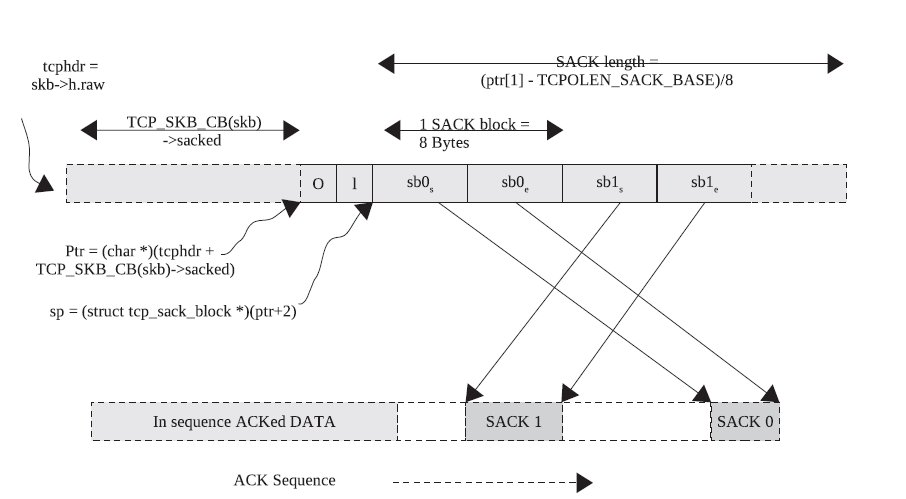
SACK是包含在tcp的option中的,由于tcp的头的长度的限制,因此SACK也就是最多包含4个段,也就是32个字节。我们先来看tcp中的SACK段的表示:
1
2
3
4
struct tcp_sack_block {
u32 start_seq; //起始序列号
u32 end_seq; //结束序列号
};
可以看到很简单,就是一个段的起始序列号和一个结束序列号。
前一篇blog我们知道tcp_skb_cb的sacked域也就是sack option的偏移值,而在tcp的option它的组成是由3部分组成的,第一部分为option类型,第二部分为当前option的长度,第三部分才是数据段,因此我们如果要取得SACK的段,就必须这样计算。
这里ack_skb也就是我们要处理的skbuffer。
1
2
3
4
5
//首先得到sack option的起始指针。
unsigned char *ptr = (skb_transport_header(ack_skb) +
TCP_SKB_CB(ack_skb)->sacked);
//加2的意思也就是加上类型和长度,这里刚好是2个字节。最终结果也就是sack option的数据段。
struct tcp_sack_block_wire *sp_wire = (struct tcp_sack_block_wire *)(ptr+2);
这里很奇怪,内核还有一个tcp_sack_block_wire类型的结构,它和tcp_sack_block是完全一样的。
而我们如果要得到当前的SACK段的个数我们要这样做:
1
2
#define TCPOLEN_SACK_BASE 2
int num_sacks = min(TCP_NUM_SACKS, (ptr[1] - TCPOLEN_SACK_BASE) >> 3);
这里ptr1也就是sack option的长度(字节数),而TCPOLEN_SACK_BASE为类型和长度字段的长度,因此这两个值的差也就是sack段的总长度,而这里每个段都是8个字节,因此我们右移3位就得到了它的个数,最后sack的段的长度不能大于4,因此我们要取一个最小值。
上面的结构下面这张图非常清晰的展示了,这几个域的关系:
然后我们来看SACK的处理,在内核中SACK的处理是通过tcp_sacktag_write_queue来实现的,这个函数比较长,因此这里我们分段来看。
先来看函数的原型
1
2
3
static int
tcp_sacktag_write_queue(struct sock *sk, struct sk_buff *ack_skb,
u32 prior_snd_una)
第一个参数是当前的sock,第二个参数是要处理的skb,第三个参数是接受ack的时候的snd_una.
在看之前这里有几个重要的域要再要说明下。
1
2
3
4
5
struct tcp_sacktag_state {
int reord;
int fack_count;
int flag;
};
3 tcp socket的highest_sack域,这个域也就是被sack确认的最大序列号的skb。
先来看第一部分,这部分的代码主要功能是初始化一些用到的值,比如sack的指针,当前有多少sack段等等,以及一些合法性校验。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
//sack段的最大个数
#define TCP_NUM_SACKS 4
......
......
const struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
//下面两句代码,前面已经分析过了,也就是取得sack的指针以及sack 数据段的指针。
unsigned char *ptr = (skb_transport_header(ack_skb) +
TCP_SKB_CB(ack_skb)->sacked);
struct tcp_sack_block_wire *sp_wire = (struct tcp_sack_block_wire *)(ptr+2);
//这个数组最终会用来保存所有的SACK段。
struct tcp_sack_block sp[TCP_NUM_SACKS];
struct tcp_sack_block *cache;
struct tcp_sacktag_state state;
struct sk_buff *skb;
//这里得到当前的sack段的个数,这段代码前面也介绍过了。
int num_sacks = min(TCP_NUM_SACKS, (ptr[1] - TCPOLEN_SACK_BASE) >> 3);
int used_sacks;
//重复的sack的个数。
int found_dup_sack = 0;
int i, j;
int first_sack_index;
state.flag = 0;
state.reord = tp->packets_out;
//如果sack的个数为0,则我们要更新相关的域。
if (!tp->sacked_out) {
if (WARN_ON(tp->fackets_out))
tp->fackets_out = 0;
//这个函数主要更新highest_sack域。
tcp_highest_sack_reset(sk);
}
//开始检测是否有重复的sack。这个函数紧接着会详细分析。
found_dup_sack = tcp_check_dsack(sk, ack_skb, sp_wire,
num_sacks, prior_snd_una);
//如果有发现,则设置flag。
if (found_dup_sack)
state.flag |= FLAG_DSACKING_ACK;
//再次判断ack的序列号是否太老。
if (before(TCP_SKB_CB(ack_skb)->ack_seq, prior_snd_una - tp->max_window))
return 0;
//如果packets_out为0,则说明我们没有发送还没有确认的段,此时进入out,也就是错误处理。
if (!tp->packets_out)
goto out;
在看接下来的部分之前我们先来看tcp_highest_sack_reset和tcp_check_dsack函数,先是tcp_highest_sack_reset函数。
1
2
3
4
5
static inline void tcp_highest_sack_reset(struct sock *sk)
{
//设置highest_sack为写队列的头。
tcp_sk(sk)->highest_sack = tcp_write_queue_head(sk);
}
这里原因很简单,因为当sacked_out为0,则说明没有通过sack确认的段,此时highest_sack自然就指向写队列的头。
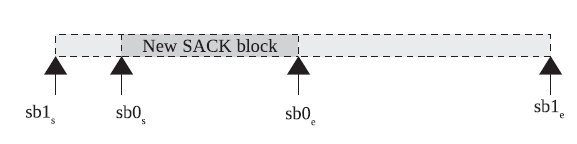
2 如果sack的第二个段完全包含了第二个段,则说明我们收到了重复的sack,下面这张图描述了这种关系。
最后要注意的是,这里收到D-SACK后,我们需要打开当前sock d-sack的option。并设置dsack的flag。
然后我们还需要判断dsack的数据是否已经被ack完全确认过了,如果确认过了,我们就需要更新undo_retrans域,这个域表示重传的数据段的个数。
来看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
static int tcp_check_dsack(struct sock *sk, struct sk_buff *ack_skb,
struct tcp_sack_block_wire *sp, int num_sacks,
u32 prior_snd_una)
{
struct tcp_sock *tp = tcp_sk(sk);
//首先取得sack的第一个段的起始和结束序列号
u32 start_seq_0 = get_unaligned_be32(&sp[0].start_seq);
u32 end_seq_0 = get_unaligned_be32(&sp[0].end_seq);
int dup_sack = 0;
//判断D-sack,首先判断第一个条件,也就是起始序列号小于ack的序列号
if (before(start_seq_0, TCP_SKB_CB(ack_skb)->ack_seq)) {
//设置dsack标记。
dup_sack = 1;
//这里更新tcp的option的sack_ok域。
tcp_dsack_seen(tp);
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPDSACKRECV);
} else if (num_sacks > 1) {
//然后执行第二个判断,取得第二个段的起始和结束序列号。
u32 end_seq_1 = get_unaligned_be32(&sp[1].end_seq);
u32 start_seq_1 = get_unaligned_be32(&sp[1].start_seq);
//执行第二个判断,也就是第二个段完全包含第一个段。
if (!after(end_seq_0, end_seq_1) &&
!before(start_seq_0, start_seq_1)) {
dup_sack = 1;
tcp_dsack_seen(tp);
NET_INC_STATS_BH(sock_net(sk),
LINUX_MIB_TCPDSACKOFORECV);
}
}
//判断是否dsack的数据段完全被ack所确认。
if (dup_sack &&
!after(end_seq_0, prior_snd_una) &&
after(end_seq_0, tp->undo_marker))
//更新重传段的个数。
tp->undo_retrans--;
return dup_sack;
}
然后回到tcp_sacktag_write_queue,接下来这部分很简单,主要是提取sack的段到sp中,并校验每个段的合法性,然后统计一些信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
//开始遍历,这里num_sacks也就是我们前面计算的sack段的个数
for (i = 0; i < num_sacks; i++) {
int dup_sack = !i && found_dup_sack;
//赋值。
sp[used_sacks].start_seq = get_unaligned_be32(&sp_wire[i].start_seq);
sp[used_sacks].end_seq = get_unaligned_be32(&sp_wire[i].end_seq);
//检测段的合法性。
if (!tcp_is_sackblock_valid(tp, dup_sack,
sp[used_sacks].start_seq,
sp[used_sacks].end_seq)) {
int mib_idx;
if (dup_sack) {
if (!tp->undo_marker)
mib_idx = LINUX_MIB_TCPDSACKIGNOREDNOUNDO;
else
mib_idx = LINUX_MIB_TCPDSACKIGNOREDOLD;
} else {
/* Don't count olds caused by ACK reordering */
if ((TCP_SKB_CB(ack_skb)->ack_seq != tp->snd_una) &&
!after(sp[used_sacks].end_seq, tp->snd_una))
continue;
mib_idx = LINUX_MIB_TCPSACKDISCARD;
}
//更新统计信息。
NET_INC_STATS_BH(sock_net(sk), mib_idx);
if (i == 0)
first_sack_index = -1;
continue;
}
//忽略已经确认过的段。
if (!after(sp[used_sacks].end_seq, prior_snd_una))
continue;
//这个值表示我们要使用的sack的段的个数。
used_sacks++;
}
然后接下来的代码就是排序sack的段,也就是按照序列号的大小来排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
for (i = used_sacks - 1; i > 0; i--) {
for (j = 0; j < i; j++) {
//可以看到这里通过比较起始序列号来排序。
if (after(sp[j].start_seq, sp[j + 1].start_seq)) {
//交换对应的值。
swap(sp[j], sp[j + 1]);
/* Track where the first SACK block goes to */
if (j == first_sack_index)
first_sack_index = j + 1;
}
}
}
然后就是cache的初始化,这里的tcp socket的recv_sack_cache域要注意,这个域保存了上一次处理的sack的段的序列号。可以看到这个域类型也是tcp_sack_block,而且大小也是4,
1
2
3
4
5
6
7
8
9
10
11
12
13
//如果sack的数据段的个数为0,则说明我们要忽略调cache,此时可以看到cache指向recv_sack_cache的末尾。
if (!tp->sacked_out) {
/* It's already past, so skip checking against it */
cache = tp->recv_sack_cache + ARRAY_SIZE(tp->recv_sack_cache);
} else {
//否则取出cache,然后跳过空的块。
cache = tp->recv_sack_cache;
/* Skip empty blocks in at head of the cache */
while (tcp_sack_cache_ok(tp, cache) && !cache->start_seq &&
!cache->end_seq)
//跳过空的块。
cache++;
}
然后就是开始真正处理重传队列中的skb了。
我们要知道重传队列中的skb有三种类型,分别是SACKED(S), RETRANS® 和LOST(L),而每种类型所处理的数据包的个数分别保存在sacked_out, retrans_out 和lost_out中。
而处于重传队列的skb也就是会处于下面6中状态:
1
2
3
4
5
6
7
* Tag InFlight Description
* 0 1 - orig segment is in flight.
* S 0 - nothing flies, orig reached receiver.
* L 0 - nothing flies, orig lost by net.
* R 2 - both orig and retransmit are in flight.
* L|R 1 - orig is lost, retransmit is in flight.
* S|R 1 - orig reached receiver, retrans is still in flight.
这里Tag也就是上面所说的三种类型,而InFlight也就是表示还在网络中的段的个数。
然后重传队列中的skb的状态变迁是通过下面这几种事件来触发的:
1
2
3
4
5
6
7
8
9
10
11
1. New ACK (+SACK) arrives. (tcp_sacktag_write_queue())
* 2. Retransmission. (tcp_retransmit_skb(), tcp_xmit_retransmit_queue())
* 3. Loss detection event of one of three flavors:
* A. Scoreboard estimator decided the packet is lost.
* A'. Reno "three dupacks" marks head of queue lost.
* A''. Its FACK modfication, head until snd.fack is lost.
* B. SACK arrives sacking data transmitted after never retransmitted
* hole was sent out.
* C. SACK arrives sacking SND.NXT at the moment, when the
* segment was retransmitted.
* 4. D-SACK added new rule: D-SACK changes any tag to S.
在进入这段代码分析之前,我们先来看几个重要的域。
tcp socket的high_seq域,这个域是我们进入拥塞控制的时候最大的发送序列号,也就是snd_nxt.
然后这里还有FACK的概念,FACK算法也就是收到的不同的SACK块之间的hole,他就认为是这些段丢失掉了。因此这里tcp socket有一个fackets_out域,这个域表示了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
//首先取得写队列的头,以便与下面的遍历。
skb = tcp_write_queue_head(sk);
state.fack_count = 0;
i = 0;
//这里used_sacks表示我们需要处理的sack段的个数。
while (i < used_sacks) {
u32 start_seq = sp[i].start_seq;
u32 end_seq = sp[i].end_seq;
//得到是否是重复的sack
int dup_sack = (found_dup_sack && (i == first_sack_index));
struct tcp_sack_block *next_dup = NULL;
if (found_dup_sack && ((i + 1) == first_sack_index))
next_dup = &sp[i + 1];
//如果sack段的结束序列号大于将要发送的最大序列号,这个情况说明我们可能有数据丢失。因此设置丢失标记。这里可以看到也就是上面所说的事件B到达。
if (after(end_seq, tp->high_seq))
state.flag |= FLAG_DATA_LOST;
//跳过一些太老的cache
while (tcp_sack_cache_ok(tp, cache) &&
!before(start_seq, cache->end_seq))
cache++;
//如果有cache,就先处理cache的sack块。
if (tcp_sack_cache_ok(tp, cache) && !dup_sack &&
after(end_seq, cache->start_seq)) {
//如果当前的段的起始序列号小于cache的起始序列号(这个说明他们之间有交叉),则我们处理他们之间的段。
if (before(start_seq, cache->start_seq)) {
skb = tcp_sacktag_skip(skb, sk, &state,
start_seq);
skb = tcp_sacktag_walk(skb, sk, next_dup,
&state,
start_seq,
cache->start_seq,
dup_sack);
}
//处理剩下的块,也就是cache->end_seq和ned_seq之间的段。
if (!after(end_seq, cache->end_seq))
goto advance_sp;
//是否有需要跳过处理的skb
skb = tcp_maybe_skipping_dsack(skb, sk, next_dup,
&state,
cache->end_seq);
/* ...tail remains todo... */
//如果刚好等于sack处理的最大序列号,则我们需要处理这个段。
if (tcp_highest_sack_seq(tp) == cache->end_seq) {
/* ...but better entrypoint exists! */
skb = tcp_highest_sack(sk);
if (skb == NULL)
break;
state.fack_count = tp->fackets_out;
cache++;
goto walk;
}
//再次检测是否有需要skip的段。
skb = tcp_sacktag_skip(skb, sk, &state, cache->end_seq);
//紧接着处理下一个cache。
cache++;
continue;
}
//然后处理这次新的sack段。
if (!before(start_seq, tcp_highest_sack_seq(tp))) {
skb = tcp_highest_sack(sk);
if (skb == NULL)
break;
state.fack_count = tp->fackets_out;
}
skb = tcp_sacktag_skip(skb, sk, &state, start_seq);
walk:
//处理sack的段,主要是tag赋值。
skb = tcp_sacktag_walk(skb, sk, next_dup, &state,
start_seq, end_seq, dup_sack);
advance_sp:
/* SACK enhanced FRTO (RFC4138, Appendix B): Clearing correct
* due to in-order walk
*/
if (after(end_seq, tp->frto_highmark))
state.flag &= ~FLAG_ONLY_ORIG_SACKED;
i++;
}
上面的代码并不复杂,这里主要有两个函数,我们需要详细的来分析,一个是tcp_sacktag_skip,一个是tcp_sacktag_walk。
先来看tcp_sacktag_skip,我们给重传队列的skb的tag赋值时,我们需要遍历整个队列,可是由于我们有序列号,因此我们可以先确认起始的skb,然后从这个skb开始遍历,这里这个函数就是用来确认起始skb的,这里确认的步骤主要是通过start_seq来确认的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static struct sk_buff *tcp_sacktag_skip(struct sk_buff *skb, struct sock *sk,
struct tcp_sacktag_state *state,
u32 skip_to_seq)
{
//开始遍历重传队列。
tcp_for_write_queue_from(skb, sk) {
//如果当前的skb刚好等于发送队列的头,则说明我们这个是第一个数据包,则我们直接跳出循环。
if (skb == tcp_send_head(sk))
break;
//如果skb的结束序列号大于我们传递进来的序列号,则说明这个skb包含了我们sack确认的段,因此我们退出循环。
if (after(TCP_SKB_CB(skb)->end_seq, skip_to_seq))
break;
//更新fack的计数。
state->fack_count += tcp_skb_pcount(skb);
}
//返回skb
return skb;
}
然后是最关键的一个函数tcp_sacktag_walk,这个函数主要是遍历重传队列,找到对应需要设置的段,然后设置tcp_cb的sacked域为TCPCB_SACKED_ACKED,这里要注意,还有一种情况就是sack确认了多个skb,这个时候我们就需要合并这些skb,然后再处理。
然后来看代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
static struct sk_buff *tcp_sacktag_walk(struct sk_buff *skb, struct sock *sk,
struct tcp_sack_block *next_dup,
struct tcp_sacktag_state *state,
u32 start_seq, u32 end_seq,
int dup_sack_in)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *tmp;
//开始遍历skb队列。
tcp_for_write_queue_from(skb, sk) {
//in_sack不为0的话表示当前的skb就是我们要设置标记的skb。
int in_sack = 0;
int dup_sack = dup_sack_in;
if (skb == tcp_send_head(sk))
break;
//由于skb是有序的,因此如果某个skb的序列号大于sack段的结束序列号,我们就退出循环。
if (!before(TCP_SKB_CB(skb)->seq, end_seq))
break;
//如果存在next_dup,则判断是否需要进入处理。这里就是skb的序列号小于dup的结束序列号
if ((next_dup != NULL) &&
before(TCP_SKB_CB(skb)->seq, next_dup->end_seq)) {
//返回值付给in_sack,也就是这个函数会返回当前skb是否能够被sack的段确认。
in_sack = tcp_match_skb_to_sack(sk, skb,
next_dup->start_seq,
next_dup->end_seq);
if (in_sack > 0)
dup_sack = 1;
}
//如果小于等于0,则尝试着合并多个skb段(主要是由于可能一个sack段确认了多个skb,这样我们尝试着合并他们)
if (in_sack <= 0) {
tmp = tcp_shift_skb_data(sk, skb, state,
start_seq, end_seq, dup_sack);
//这里tmp就为我们合并成功的skb。
if (tmp != NULL) {
//如果不等,则我们从合并成功的skb重新开始处理。
if (tmp != skb) {
skb = tmp;
continue;
}
in_sack = 0;
} else {
//否则我们单独处理这个skb
in_sack = tcp_match_skb_to_sack(sk, skb,
start_seq,
end_seq);
}
}
if (unlikely(in_sack < 0))
break;
//如果in_sack大于0,则说明我们需要处理这个skb了。
if (in_sack) {
//开始处理skb,紧接着我们会分析这个函数。
TCP_SKB_CB(skb)->sacked = tcp_sacktag_one(skb, sk,
state,
dup_sack,
tcp_skb_pcount(skb));
//是否需要更新sack处理的那个最大的skb。
if (!before(TCP_SKB_CB(skb)->seq,
tcp_highest_sack_seq(tp)))
tcp_advance_highest_sack(sk, skb);
}
state->fack_count += tcp_skb_pcount(skb);
}
return skb;
}
然后我们来看tcp_sacktag_one函数,这个函数用来设置对应的tag,这里所要设置的也就是tcp_cb的sacked域。我们再来回顾一下它的值:
1
2
3
4
5
6
#define TCPCB_SACKED_ACKED 0x01 /* SKB ACK'd by a SACK block */
#define TCPCB_SACKED_RETRANS 0x02 /* SKB retransmitted */
#define TCPCB_LOST 0x04 /* SKB is lost */
#define TCPCB_TAGBITS 0x07 /* All tag bits */
#define TCPCB_EVER_RETRANS 0x80 /* Ever retransmitted frame */
#define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS)
如果一切都正常的话,我们最终就会设置skb的这个域为TCPCB_SACKED_ACKED,也就是已经被sack过了。
这个函数处理比较简单,主要就是通过序列号以及sacked本身的值最终来确认sacked要被设置的值。
这里我们还记得,一开始sacked是被初始化为sack option的偏移(如果是正确的sack)的.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
static u8 tcp_sacktag_one(struct sk_buff *skb, struct sock *sk,
struct tcp_sacktag_state *state,
int dup_sack, int pcount)
{
struct tcp_sock *tp = tcp_sk(sk);
u8 sacked = TCP_SKB_CB(skb)->sacked;
int fack_count = state->fack_count;
......
//如果skb的结束序列号小于发送未确认的,则说明这个帧应当被丢弃。
if (!after(TCP_SKB_CB(skb)->end_seq, tp->snd_una))
return sacked;
//如果当前的skb还未被sack确认过,则我们才会进入处理。
if (!(sacked & TCPCB_SACKED_ACKED)) {
//如果是重传被sack确认的。
if (sacked & TCPCB_SACKED_RETRANS) {
//如果设置了lost,则我们需要修改它的tag。
if (sacked & TCPCB_LOST) {
sacked &= ~(TCPCB_LOST|TCPCB_SACKED_RETRANS);
//更新lost的数据包
tp->lost_out -= pcount;
tp->retrans_out -= pcount;
}
} else {
.......
}
//开始修改sacked,设置flag。
sacked |= TCPCB_SACKED_ACKED;
state->flag |= FLAG_DATA_SACKED;
//增加sack确认的包的个数/
tp->sacked_out += pcount;
fack_count += pcount;
//处理fack
if (!tcp_is_fack(tp) && (tp->lost_skb_hint != NULL) &&
before(TCP_SKB_CB(skb)->seq,
TCP_SKB_CB(tp->lost_skb_hint)->seq))
tp->lost_cnt_hint += pcount;
if (fack_count > tp->fackets_out)
tp->fackets_out = fack_count;
}
/* D-SACK. We can detect redundant retransmission in S|R and plain R
* frames and clear it. undo_retrans is decreased above, L|R frames
* are accounted above as well.
*/
if (dup_sack && (sacked & TCPCB_SACKED_RETRANS)) {
sacked &= ~TCPCB_SACKED_RETRANS;
tp->retrans_out -= pcount;
}
return sacked;
}
最后我们来看tcp_sacktag_write_queue的最后一部分,也就是更新cache的部分。
它也就是将处理过的sack清0,没处理过的保存到cache中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//开始遍历,可以看到这里将将我们未处理的sack段的序列号清0.
for (i = 0; i < ARRAY_SIZE(tp->recv_sack_cache) - used_sacks; i++) {
tp->recv_sack_cache[i].start_seq = 0;
tp->recv_sack_cache[i].end_seq = 0;
}
//然后保存这次处理了的段。
for (j = 0; j < used_sacks; j++)
tp->recv_sack_cache[i++] = sp[j];
//标记丢失的段。
tcp_mark_lost_retrans(sk);
tcp_verify_left_out(tp);
if ((state.reord < tp->fackets_out) &&
((icsk->icsk_ca_state != TCP_CA_Loss) || tp->undo_marker) &&
(!tp->frto_highmark || after(tp->snd_una, tp->frto_highmark)))
tcp_update_reordering(sk, tp->fackets_out - state.reord, 0);