

http://blog.chinaunix.net/uid-20543672-id-2996319.html
- 内核具有非常小的栈,它可能只和一个4096或8192字节大小的页那样小
什么是进程的“内核栈”?
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先用户空间中的栈,而是一个内核空间的栈,这个称作进程的“内核栈”。
比如,有一个简单的字符驱动实现了open方法。在这个驱动挂载后,应用程序对那个驱动所对应的设备节点执行open操作,这个应用程序的open其实 就通过glib库调用了Linux的open系统调用,执行系统调用陷入内核后,处理器转换为了特权模式(具体的转换机制因构架而异,对于ARM来说普通 模式和用户模式的的栈针(SP)是不同的寄存器),此时使用的栈指针就是内核栈指针,他指向内核为每个进程分配的内核栈空间。
内核栈的作用
我个人的理解是:在陷入内核后,系统调用中也是存在函数调用和自动变量,这些都需要栈支持。用户空间的栈显然不安全,需要内核栈的支持。此外,内核栈同时用于保存一些系统调用前的应用层信息(如用户空间栈指针、系统调用参数)。
内核栈与进程结构体的关联
每个进程在创建的时候都会得到一个内核栈空间,内核栈和进程的对应关系是通过2个结构体中的指针成员来完成的:
(1)struct task_struct
在学习Linux进程管理肯定要学的结构体,在内核中代表了一个进程,其中记录的进程的所有状态信息,定义在Sched.h (include\linux)。
其中有一个成员:void *stack;就是指向下面的内核栈结构体的“栈底”。
在系统运行的时候,宏current获得的就是当前进程的struct task_struct结构体。
(2)内核栈结构体union thread_union
1 2 3 4 | |
其中struct thread_info是记录部分进程信息的结构体,其中包括了进程上下文信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
关键是其中的task成员,指向的是所创建的进程的struct task_struct结构体
而其中的stack成员就是内核栈。从这里可以看出内核栈空间和 thread_info是共用一块空间的。如果内核栈溢出, thread_info就会被摧毁,系统崩溃了~~~
内核栈—struct thread_info—-struct task_struct三者的关系入下图:
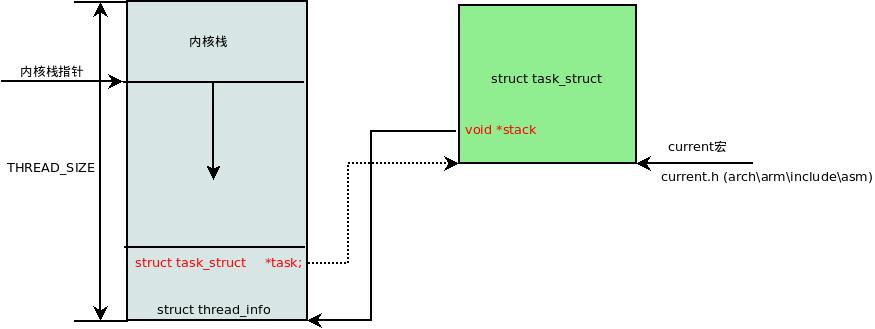
内核栈的产生
在进程被创建的时候,fork族的系统调用中会分别为内核栈和struct task_struct分配空间,调用过程是: fork族的系统调用—>do_fork—>copy_process—>dup_task_struct 在dup_task_struct函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
其中alloc_task_struct使用内核的slab分配器去为所要创建的进程分配struct task_struct的空间
而alloc_thread_info使用内核的伙伴系统去为所要创建的进程分配内核栈(union thread_union )空间
注意:
后面的tsk->stack = ti;语句,这就是关联了struct task_struct和内核栈 而在setup_thread_stack(tsk, orig);中,关联了内核栈和struct task_struct:
1 2 3 4 5 | |
内核栈的大小
由于是每一个进程都分配一个内核栈空间,所以不可能分配很大。这个大小是构架相关的,一般以页为单位。其实也就是上面我们看到的THREAD_SIZE, 这个值一般为4K或者8K。对于ARM构架,这个定义在Thread_info.h (arch\arm\include\asm),
1 2 3 | |
所以ARM的内核栈是8KB 在(内核)驱动编程时需要注意的问题: 由于栈空间的限制,在编写的驱动(特别是被系统调用使用的底层函数)中要注意避免对栈空间消耗较大的代码,比如递归算法、局部自动变量定义的大小等等