

http://zzjlzx.blog.chinaunix.net/uid-29060569-id-4076183.html
调度:
操作系统的调度程序的两项任务:
1: 调度:
实现调度策略,决定就绪的进程、线程竞争cpu的次序的裁决原则。说白了就是进程和线程何时应该放弃cpu和选择那个就绪进程、线程来执行。
2: 分派:
原来实现调度机制如何时分复用cpu,处理好上下文交换的细节、完成进程、线程和cpu的绑定和放弃的具工作。
linux 2.4 调度:
1:policy :
进程的调度策略:
1 2 3 | |
2:priority:进程的静态优先级。
3:nice:进程用来控制优先级的因子。在-20~19间的整数。增加nice的值会使优先级降低。默认值为0。
4:rt_priority:实时进程的优先级。
5:counter:一个计时器,进程目前的剩余时间片。用来动态计算进程的动态优先级。系统将休眠次数多的进程的剩余时间叠会加起来。
6:schedule()的流程:
1 2 3 4 5 6 7 | |
过程:2.4的调度算法,将所有的就绪进程组织成一条可运行队列,不管是单核环境还是smp环境,cpu都只从这条可运行队列中循环遍历直到挑选到下一个要运行的进程。如果所有的进程的时间片都用完,就重新计算所有进程的时间片。
2.4调度的数据结构:
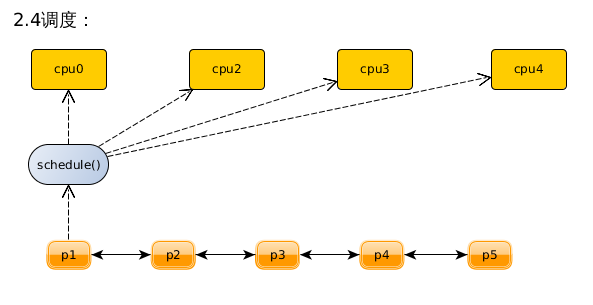
2.4调度的不足:
1)一个明显的缺点就是时间复杂度为O(n),每次都要遍历队列,效率低!。虽然说O(n)的复杂度看起来不是很糟糕,而且系统能容纳进程数量也不一定会很大,但复杂度为O(n)还是很难忍受的。
2)由于在smp环境下多个cpu还是使用同一条运行队列,所以进程在多个cpu间切换会使cpu的缓存效率降低,降低系统的性能。
3)多个cpu共享一条运行队列,使得每个cpu在对队列操作的时候需要对运行队列进行加锁,这时如果其他空闲cpu要访问运行队列,则只能等待了。由2、3两点可以看出2.4的调度算法对smp环境的伸缩性不高!不能很好地支持smp环境。
4)不支持内核抢占,内核不能及时响应实时任务,无法满足实时系统的要求(即使linux不是一个硬实时,但同样无法满足软实时性的要求)。
5)进程的剩余时间是除了nice值外对动态优先级影响最大的因素,并且系统将休眠次数多的进程的剩余时间叠加起来,从而得出更大的动态优先级。这体现了系统更倾向优先执行I/O型进程。内核就是通过这种方式来提高交互进程的优先级,使其优先执行。但休眠多的进程就代表是交互型的进程吗?并不是的,这只能说明它是I/O型进程。I/O型进程需要进行I/O交互,如读写磁盘时进程会经常处于休眠的状态。如果把这种进程当成是交互进程,反而会影响其他真正的交互进程。
6)简单的负载平衡。那个cpu空闲就把就绪的进程调度到这个cpu上去执行。或者某个cpu的进程的优先级比某个进程低,就调度到那个cpu上去执行。这样简单的负载平衡缺点不言而喻。进程迁移比较频繁,而且出现2、3的情况。这样的负载平衡弊大于利!
linux 2.6 O(1)调度:
1:policy:调度策略跟2.4的一样。
2:rt_priority:实时进程的优先级。在0~99之间。MAX_RT_PRIO为100。不参与优先级的计算。
3:static_prio:非实时进程的静态优先级,由nice值转换而来,-20 <= nice <= 19。static_prio = MAX_RT_PRIO + nice + 20。所以 100 <= static_prio <= 139。
4:sleep_avg:进程平均等待时间。进程等待时间与执行时间的差。反映进程的交互性,又表示了进程需要运行的紧急程度。这个值越大,进程的优先级就越高。
5:prio:进程的动态优先级。主要影响进程的prio的因素是sleep_avg。其计算时机为:
1 2 3 4 | |
6:time_slice:进程的时间片余额。进程的默认时间片与static_prio有关。
7:load_weight:平衡负载用的权重。
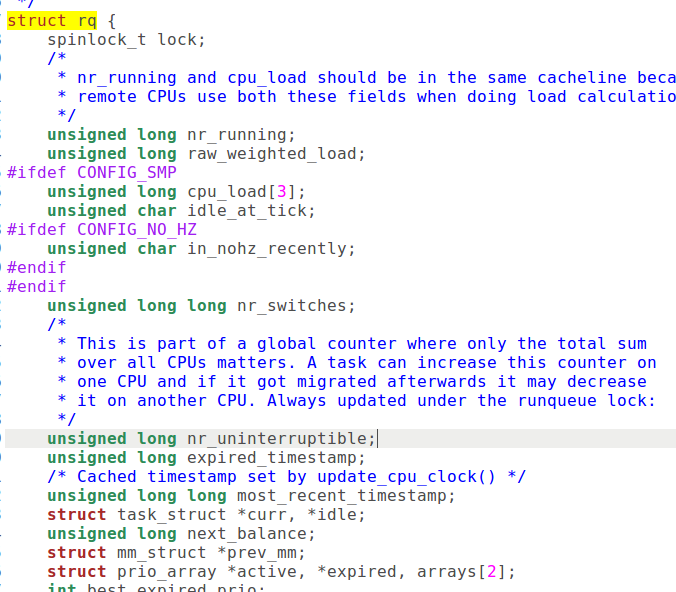
linux 2.6 O(1)调度的数据结构代码:
1:运行队列:部分代码如图:
2:优先级数组代码如图:

1 2 3 | |
linux 2.6 O(1)调度的数据结构(active or expired):
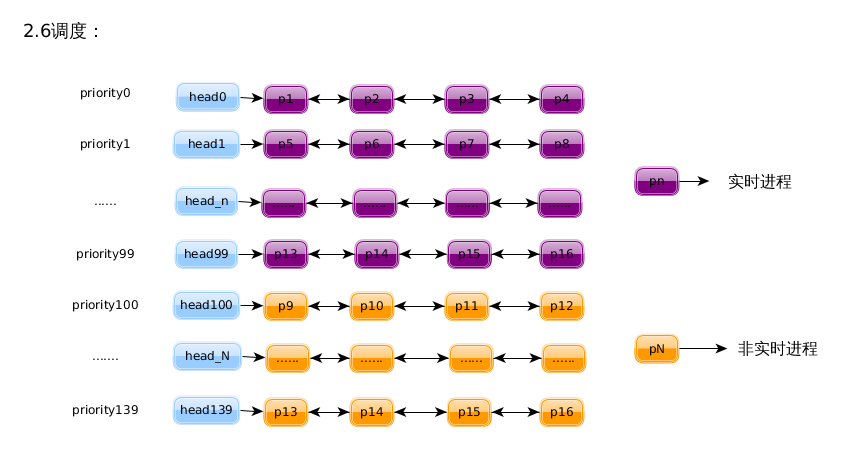
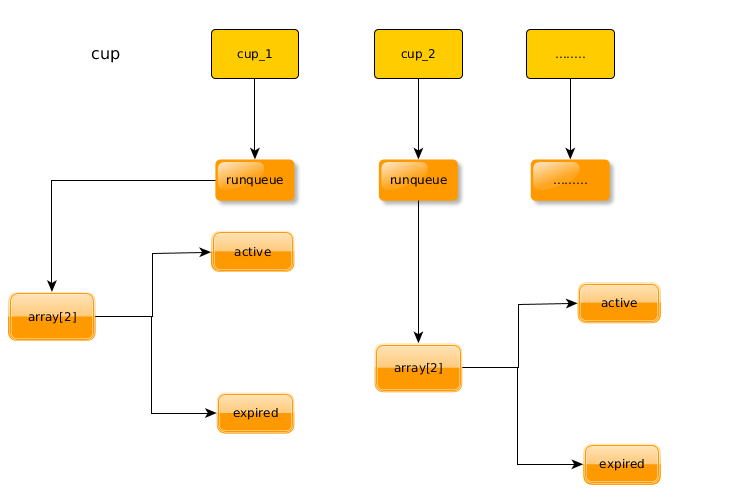
每个cpu维护一个自己的运行队列,每个运行队列有分别维护自己的active队列与expried队列。当进程的时间片用完后就会被放入expired队列中。当active队列中所有进程的时间片都用完,进程执行完毕后,交换active队列和expried。这样expried队列就成为了active队列。这样做只需要指针的交换而已。当调度程序要找出下一个要运行的进程时,只需要根据上面提过的位图宏来找出优先级最高的且有就绪进程的队列。这样的数据组织下,2.6的调度程序的时间复杂度由原来2.4的O(n)提高到O(1)。而其对smp环境具有较好的伸缩性。
数据结构的组织如下:
linux 2.6 O(1) 调度的进程优先级:
2.6调度有140个优先级级别,由0~139, 0~99 为实时优先级,而100~139为非实时优先级。上面的图有说。
特点:
1)动态优先级是在静态优先级的基础上结合进程的运行状态和进程的交互性来计算。所以真正参与调度的是进程的动态优先级。而进程的交互性是通过进程的睡眠时间来判断的(这点从根本上来说还是和2.4思想的一样)。所以动态优先级是通过静态优先级和进程睡眠时间来计算的。这里要注意的是,动态优先级是非实时进程插入优先级队列的依据。但实时进程是根据rt_prioirty来插入队列的,实时进程的实时优先级由进程被创建到进程结束都是不会改变的。但其执行的时间片是根据静态优先级来计算的。
2)进程优先级越高,它每次执行的时间片就越长。
3)使用TASK_INTERACTIVE()宏来判断进程是否为交互进程,该宏是基于nice来判断的,nice值越高,优先级越低,这样交互性越低。
4)如果一个进程的交互性比较强,那么其执行完自身的时间片后不会移到expired队列中,而是插到原来队列的尾部。这样交互性进程可以快速地响应用户,交互性会提高。如果被移到expired队列,那么在交换队列指针前,交互性进程可能就会发生严重的饥饿,从而使交互性严重下降
5)在创建新的进程时,子进程会与父进程平分进程的剩余时间片。即在 fork()——>do_fork() 后父子进程的时间片之和等于原来父进程的时间片大小。这样做的原因是为了防止父进程利用创建子进程来窃取时间片。如果子进程在退出时,从来没有被重新分配时间片,且还有时间片剩余,则其剩余的时间片会返还给父进程。这样父进程就不会因为创建子进程而受到时间片上的惩罚。
2.6 O(1)调度动态优先级的计算代码:
1)effective_prio(p):
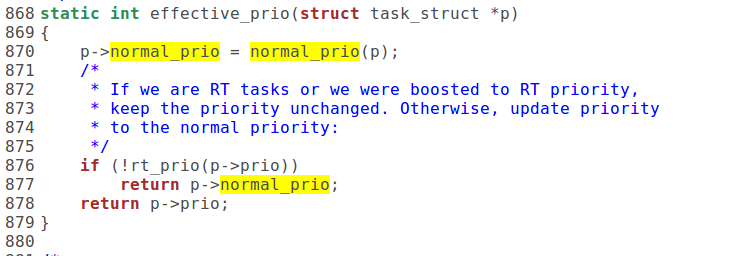
2)normal_prio:

3)__normal_prio:
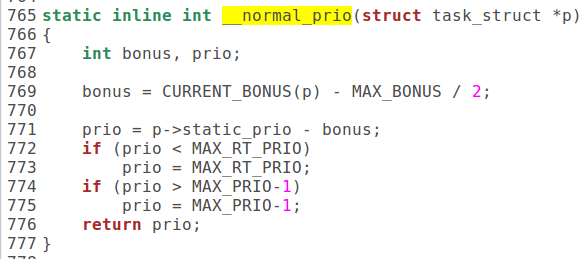
linux 2.6 O(1)调度的调度与抢占时机:
1:直接调度:当前进程因为阻塞而直接调用schedule()主动放弃cpu。
1 2 3 4 | |
2:被动调度:当前进程因为时间片用完,或者被更高优先级的进程抢占,而被逼放弃cpu。这时当前进程不会立刻被调度出去,而是通过设置TIF_NEED_RESCHED位为1来告知kernel需要调度了。在适当的时机kernel会重新调度。
1)问题:为什么不能立刻调度?
进程在内核里运行时,可能要申请共享资源,如自旋锁,如果这个时候去抢占当前进程,使其立刻让出cpu,如果新进程也需要相同的共享资源的话,那么会导致死锁!所以这里进程只设置了标志位通知内核需要调度。
2)问题:什么时候才是合适的时机?
内核在即将返回用户空间时会检查TIF_NEED_RESCHED,如果设置了就调用schedule(),这样就会发生用户抢占。
a:从中断处理程序返回用户空间时。
b:从系统调用返回用户空间时。
linux 2.6 O(1)调度的负载平衡:
复杂!
linux 2.6 O(1)调度的过渡:
1:SD调度器:
O(1)调度的复杂性主要来至于动态优先级的计算。调度器根据一些难以理解的经验公式和平均休眠时间来决定、修改进程的优先级。这是O(1)调度一个比较大的缺点(甚至可以说是致命的。)。SD调度的特点:
1)数据结构跟O(1)调度差不多,不过少了expired队列。
2)进程在用完其时间片后不会放到expired队列,而是放到下一个优先级队列中(这就是为什么没有expired队列的原因)。当下降到最低一级时,时间片用完,就回到初始优先级队列去,重新降级的过程!每一次降级就像我们下楼梯的过程,所以这被称为楼梯算法。
3)两种时间片:粗粒度、细粒度。粗粒度由多个细粒度组成,当一个粗粒度时间片被用完,进程就开始降级,一个细粒度用完就进行轮回。这样cpu消耗型的进程在每个优先级上停留的时间都是一样的。而I/O消耗型的进程会在优先级最高的队列上停留比较长的时间,而且不一定会滑落到很低的优先级队列上去。
4)不会饥饿,代码比O(1)调度简单,最重要的意义在于证明了完全公平的思想的可行性。
5)相对与O(1)调度的算法框架还是没有多大的变化,每一次调整优先级的过程都是一次进程的切换过程,细粒度的时间片通常比O(1)调度的时间片短很多。这样不可避免地带来了较大的额外开销,使吞吐量下降的问题。这是SD算法不被采用的主要原因!
2:RSDL调度器:
对SD算法的改进,其核心思想是“完全公平”,并且没有复杂的动态优先级的调整策略。引进“组时间配额” → tg 每个优先级队列上所有进程可以使用的总时间 ,”优先级时间配额“ → tp, tp不等于进程的时间片,而是小于进程时间片。当进程的tp用完后就降级。与SD算法相类似。当每个队列的tg用完后不管队列中是否有tp没有用完,该队列的所有进程都会被强制降级。
linux 2.6 O(1)调度的不足:
1:复杂的难以理解的经验公式。
2:公平吗?
3:实时性?
linux 杰出的调度算法 → cfs:
按照cfs的作者的说法:”cfs的 80% 的工作可以用一句话来概括:cfs在真实的硬件上模拟了完全理想的多任务处理器。“ 在完全理想的多任务处理器下,每个进程都能够同时获得cpu的执行时间,当系统中有两个进程时,cpu时间被分成两份,每个进程占50%。
1:虚拟运行时间。进程的 vt 与其实际的运行时间成正比,与其权重成反比。权重是由进程优先级来决定的,而优先级又参照nice值的大小。进程优先级权重越高,在实际运行时间相同时,进程的vt就越小。所有的非实时的可运行的进程用红黑树来组织起来,调度时选择的vt最小的那个进程。因为这里的红黑树左子树的键值比右边的小,所以每次调度时都选择树的最左下角的那个进程(实体)就可以了。
2:完全公平的思想。cfs不再跟踪进程的休眠时间、也不再区分交互式进程,其将所有的进程统一对待,在既定的时间内每个进程都获得了公平的cpu占用时间,这就是cfs里的公平所在!
3:cfs 引入了模块化、完全公平调度、组调度等一系列特性。虽说是完全公平调度,但进程之间本来就不公平的(有些内核线程用于处理紧急情况),所以这种完全公平是不能够实现的。cfs使用weight 权重来区分进程间不平等的地位,这也是cfs实现公平的依据。权重由优先级来决定,优先级越高,权重越大。但优先级与权重之间的关系并不是简单的线性关系。内核使用一些经验数值来进行转化。
如果有a、b、c 三个进程,权重分别是1、2、3,那么所有的进程的权重和为6, 按照cfs的公平原则来分配,那么a的重要性为1/6, b、c 为2/6, 3/6。这样如果a、b、c 运行一次的总时间为6个时间单位,a占1个,b占2个,c占3个。
cfs调度器:
各个部分的数据结构关系图如下:
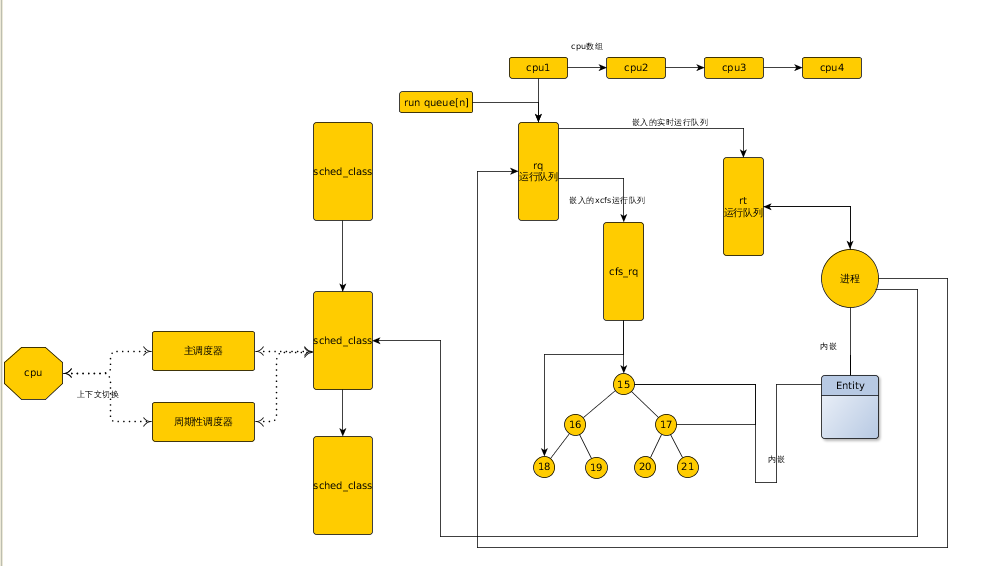
虚拟运行时间
在完全理想的多任务处理器下,每个进程都能同时获得cpu的时间。但实际上当一个进程占用cpu时,其他的进程必须等待,这样就产生了不公平。所以linux 的cfs调度引入了虚拟运行时间。虚拟运行时间主要由两个因素决定,一个是实际的运行时间,一个是其权重,它随自己的实际运行时间增加而增加,但又不等于实际运行时间。上面提过内核采用红黑树来对虚拟运行时间来排序,这样红黑树最左边的进程(调度实体)就是受到了最不公平待遇的进程,需要作为下一个被调度的进程。 进程的虚拟运行时间由calc_delta_fair()来计算。在每次时钟中断后都会进行更新。公式为:
1 2 3 4 | |
delta是进程增加的实际的运行时间。 NICE_0_LOAD为nice 0进程的权重。虚拟运行时间与权重成反比,进程的权重越大虚拟运行时间就增加得越慢,位置就越左,越有可能被调度。
对cfs的理解最好就是看源代码了,下面贴出代码(网上有人整理得很好了):
各个函数的调用关系图:
(1)
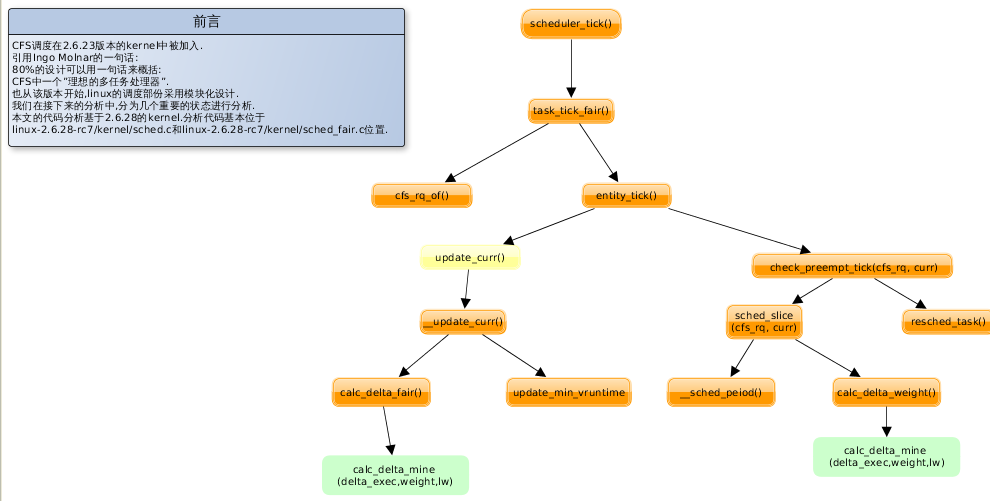
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | |
(2)
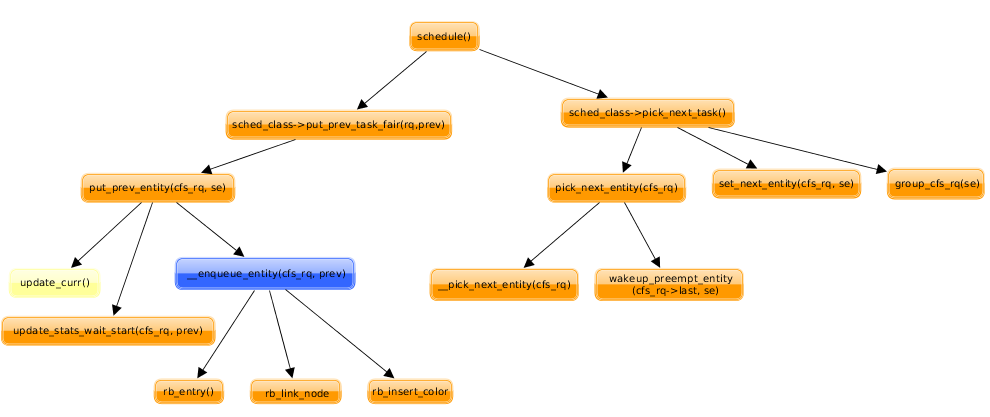
1 2 3 4 5 6 7 | |
(3)
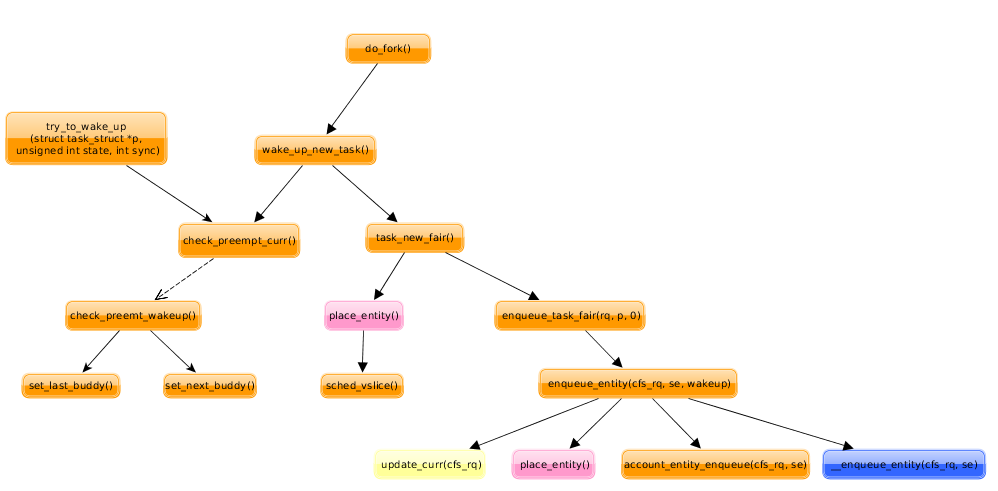
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |