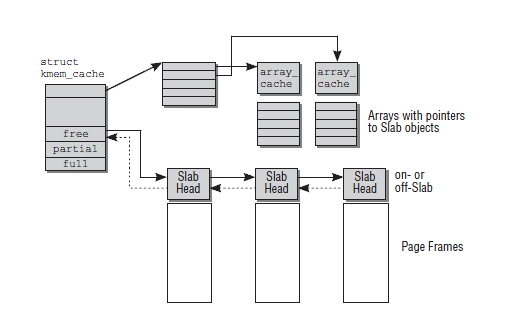
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
/*per-CPU数据,记录了本地高速缓存的信息,也用于跟踪最近释放的对象,每次分配和释放都要直接访问它*/
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount; /*本地高速缓存转入或转出的大批对象数量*/
unsigned int limit; /*本地高速缓存中空闲对象的最大数目*/
unsigned int shared;
unsigned int buffer_size;/*管理对象的大小*/
u32 reciprocal_buffer_size;/*buffer_size的倒数值*/
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* 高速缓存的永久标识*/
unsigned int num; /* 一个slab所包含的对象数目 */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder; /*一个slab包含的连续页框数的对数*/
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags; /*与伙伴系统交互时所提供的分配标识*/
size_t colour; /* 颜色的个数*/
unsigned int colour_off; /* 着色的偏移量 */
/*如果将slab描述符存储在外部,该指针指向存储slab描述符的cache,
否则为NULL*/
struct kmem_cache *slabp_cache;
unsigned int slab_size; /*slab管理区的大小*/
unsigned int dflags; /*动态标识*/
/* constructor func */
void (*ctor)(void *obj); /*创建高速缓存时的构造函数指针*/
/* 5) cache creation/removal */
const char *name; /*高速缓存名*/
struct list_head next; /*用于将高速缓存链入cache chain*/
/* 6) statistics */
#ifdef CONFIG_DEBUG_SLAB /*一些用于调试用的变量*/
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
/*struct kmem_list3用于组织该高速缓存中的slab*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};
12345678910111213
struct kmem_list3 {
struct list_head slabs_partial;/*slab链表,包含空闲对象和已分配对象的slab描述符*/
struct list_head slabs_full; /*slab链表,只包含非空闲的slab描述符*/
struct list_head slabs_free; /*slab链表,只包含空闲的slab描述符*/
unsigned long free_objects; /*高速缓存中空闲对象的个数*/
unsigned int free_limit; /*空闲对象的上限*/
unsigned int colour_next; /*下一个slab使用的颜色*/
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};
描述和管理单个slab的结构是struct slab
12345678
struct slab {
struct list_head list; /*用于将slab链入kmem_list3的链表*/
unsigned long colouroff;/*该slab的着色偏移*/
void *s_mem; /*指向slab中的第一个对象*/
unsigned int inuse; /*已分配出去的对象*/
kmem_bufctl_t free; /*下一个空闲对象的下标*/
unsigned short nodeid; /*节点标识号*/
};
struct array_cache {
unsigned int avail;/*本地高速缓存中可用的空闲对象数*/
unsigned int limit;/*空闲对象的上限*/
unsigned int batchcount;/*一次转入和转出的对象数量*/
unsigned int touched; /*标识本地CPU最近是否被使用*/
spinlock_t lock;
void *entry[]; /*这是一个伪数组,便于对后面用于跟踪空闲对象的指针数组的访问
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
/*
* These are the default caches for kmalloc. Custom caches can have other sizes.
*/
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>
CACHE(ULONG_MAX)
#undef CACHE
};
void __init kmem_cache_init(void)
{
size_t left_over;
struct cache_sizes *sizes;
struct cache_names *names;
int i;
int order;
int node;
if (num_possible_nodes() == 1)
use_alien_caches = 0;
/*初始化静态L3变量initkmem_list3*/
for (i = 0; i < NUM_INIT_LISTS; i++) {
kmem_list3_init(&initkmem_list3[i]);
if (i < MAX_NUMNODES)
cache_cache.nodelists[i] = NULL;
}
/*将cache_cache和initkmem_list3相关联*/
set_up_list3s(&cache_cache, CACHE_CACHE);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory.
*/
if (totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_break_gfp_order = BREAK_GFP_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the cache_cache cache: it contains the struct
* kmem_cache structures of all caches, except cache_cache itself:
* cache_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_list3 structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for cache_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_list3 for cache_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
node = numa_node_id();
/*初始化cache_cache的其余部分*/
/* 1) create the cache_cache */
INIT_LIST_HEAD(&cache_chain);
list_add(&cache_cache.next, &cache_chain);
cache_cache.colour_off = cache_line_size();
cache_cache.array[smp_processor_id()] = &initarray_cache.cache;
cache_cache.nodelists[node] = &initkmem_list3[CACHE_CACHE + node];
/*
* struct kmem_cache size depends on nr_node_ids, which
* can be less than MAX_NUMNODES.
*/
cache_cache.buffer_size = offsetof(struct kmem_cache, nodelists) +
nr_node_ids * sizeof(struct kmem_list3 *);
#if DEBUG
cache_cache.obj_size = cache_cache.buffer_size;
#endif
cache_cache.buffer_size = ALIGN(cache_cache.buffer_size,
cache_line_size());
cache_cache.reciprocal_buffer_size =
reciprocal_value(cache_cache.buffer_size);
/*计算cache_cache的剩余空间以及slab中对象的数目,order决定了slab的大小(PAGE_SIZE<<order)*/
for (order = 0; order < MAX_ORDER; order++) {
cache_estimate(order, cache_cache.buffer_size,
cache_line_size(), 0, &left_over, &cache_cache.num);
/*当该order计算出来的num,即slab中对象的数目不为0时,则跳出循环*/
if (cache_cache.num)
break;
}
BUG_ON(!cache_cache.num);
cache_cache.gfporder = order;/*确定分配给每个slab的页数的对数*/
cache_cache.colour = left_over / cache_cache.colour_off;/*确定可用颜色的数目*/
/*确定slab管理区的大小,即slab描述符以及kmem_bufctl_t数组*/
cache_cache.slab_size = ALIGN(cache_cache.num * sizeof(kmem_bufctl_t) +
sizeof(struct slab), cache_line_size());
/* 2+3) create the kmalloc caches */
sizes = malloc_sizes;
names = cache_names;
/*
* Initialize the caches that provide memory for the array cache and the
* kmem_list3 structures first. Without this, further allocations will
* bug.
*/
/*为了后面能够调用kmalloc()创建per-CPU高速缓存和kmem_list3高速缓存,
这里必须先创建大小相应的general cache*/
sizes[INDEX_AC].cs_cachep = kmem_cache_create(names[INDEX_AC].name,
sizes[INDEX_AC].cs_size,
ARCH_KMALLOC_MINALIGN,
ARCH_KMALLOC_FLAGS|SLAB_PANIC,
NULL);
/*如果AC和L3在malloc_sizes中的偏移不一样,也就是说它们的大小不属于同一级别,
则创建AC的gerneral cache,否则两者共用一个gerneral cache*/
if (INDEX_AC != INDEX_L3) {
sizes[INDEX_L3].cs_cachep =
kmem_cache_create(names[INDEX_L3].name,
sizes[INDEX_L3].cs_size,
ARCH_KMALLOC_MINALIGN,
ARCH_KMALLOC_FLAGS|SLAB_PANIC,
NULL);
}
slab_early_init = 0;
/*创建各级的gerneral cache*/
while (sizes->cs_size != ULONG_MAX) {
/*
* For performance, all the general caches are L1 aligned.
* This should be particularly beneficial on SMP boxes, as it
* eliminates "false sharing".
* Note for systems short on memory removing the alignment will
* allow tighter packing of the smaller caches.
*/
if (!sizes->cs_cachep) {
sizes->cs_cachep = kmem_cache_create(names->name,
sizes->cs_size,
ARCH_KMALLOC_MINALIGN,
ARCH_KMALLOC_FLAGS|SLAB_PANIC,
NULL);
}
#ifdef CONFIG_ZONE_DMA
sizes->cs_dmacachep = kmem_cache_create(
names->name_dma,
sizes->cs_size,
ARCH_KMALLOC_MINALIGN,
ARCH_KMALLOC_FLAGS|SLAB_CACHE_DMA|
SLAB_PANIC,
NULL);
#endif
sizes++;
names++;
}
/* 4) Replace the bootstrap head arrays */
{
struct array_cache *ptr;
/*这里调用kmalloc()为cache_cache创建per-CPU高速缓存*/
ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);
BUG_ON(cpu_cache_get(&cache_cache) != &initarray_cache.cache);
/*将静态定义的initarray_cache中的array_cache拷贝到malloc申请到的空间中*/
memcpy(ptr, cpu_cache_get(&cache_cache),
sizeof(struct arraycache_init));
/*
* Do not assume that spinlocks can be initialized via memcpy:
*/
spin_lock_init(&ptr->lock);
/*将cache_cache与保存per-CPU高速缓存的空间关联*/
cache_cache.array[smp_processor_id()] = ptr;
/*为之前创建的AC gerneral cache创建per-CPU高速缓存,替换静态定义的initarray_generic.cache*/
ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);
BUG_ON(cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep)
!= &initarray_generic.cache);
memcpy(ptr, cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep),
sizeof(struct arraycache_init));
/*
* Do not assume that spinlocks can be initialized via memcpy:
*/
spin_lock_init(&ptr->lock);
malloc_sizes[INDEX_AC].cs_cachep->array[smp_processor_id()] =
ptr;
}
/* 5) Replace the bootstrap kmem_list3's */
{
int nid;
for_each_online_node(nid) {
/*为cache_cache的kmem_list3申请高速缓存空间,并替换静态定义的initkmem_list3*/
init_list(&cache_cache, &initkmem_list3[CACHE_CACHE + nid], nid);
/*为AC的kmem_list3申请高速缓存空间,并替换静态定义的initkmem_list3*/
init_list(malloc_sizes[INDEX_AC].cs_cachep,
&initkmem_list3[SIZE_AC + nid], nid);
if (INDEX_AC != INDEX_L3) {
/*为L3的kmem_list3申请高速缓存空间,并替换静态定义的initkmem_list3*/
init_list(malloc_sizes[INDEX_L3].cs_cachep,
&initkmem_list3[SIZE_L3 + nid], nid);
}
}
}
g_cpucache_up = EARLY;
}
void __init kmem_cache_init_late(void)
{
struct kmem_cache *cachep;
/* 6) resize the head arrays to their final sizes */
mutex_lock(&cache_chain_mutex);
list_for_each_entry(cachep, &cache_chain, next)
if (enable_cpucache(cachep, GFP_NOWAIT))
BUG();
mutex_unlock(&cache_chain_mutex);
/* Done! */
g_cpucache_up = FULL; /*slab初始化完成*/
/* Annotate slab for lockdep -- annotate the malloc caches */
init_lock_keys();
/*
* Register a cpu startup notifier callback that initializes
* cpu_cache_get for all new cpus
*/
register_cpu_notifier(&cpucache_notifier);
/*
* The reap timers are started later, with a module init call: That part
* of the kernel is not yet operational.
*/
}
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))
{
size_t left_over, slab_size, ralign;
struct kmem_cache *cachep = NULL, *pc;
gfp_t gfp;
/*
* Sanity checks... these are all serious usage bugs.
*/
/*做一些必要的检查,以下情况都是不合法的:
1.缓存名为空
2.处于中断环境中
3.缓存中的对象大小小于处理器的字长
4.缓存中的对象大小大于普通缓存的最大长度*/
if (!name || in_interrupt() || (size < BYTES_PER_WORD) ||
size > KMALLOC_MAX_SIZE) {
printk(KERN_ERR "%s: Early error in slab %s\n", __func__,
name);
BUG();
}
/*
* We use cache_chain_mutex to ensure a consistent view of
* cpu_online_mask as well. Please see cpuup_callback
*/
if (slab_is_available()) {
get_online_cpus();
mutex_lock(&cache_chain_mutex);
}
list_for_each_entry(pc, &cache_chain, next) {
char tmp;
int res;
/*
* This happens when the module gets unloaded and doesn't
* destroy its slab cache and no-one else reuses the vmalloc
* area of the module. Print a warning.
*/
res = probe_kernel_address(pc->name, tmp);
if (res) {
printk(KERN_ERR
"SLAB: cache with size %d has lost its name\n",
pc->buffer_size);
continue;
}
if (!strcmp(pc->name, name)) {
printk(KERN_ERR
"kmem_cache_create: duplicate cache %s\n", name);
dump_stack();
goto oops;
}
}
#if DEBUG
WARN_ON(strchr(name, ' ')); /* It confuses parsers */
#if FORCED_DEBUG
/*
* Enable redzoning and last user accounting, except for caches with
* large objects, if the increased size would increase the object size
* above the next power of two: caches with object sizes just above a
* power of two have a significant amount of internal fragmentation.
*/
if (size < 4096 || fls(size - 1) == fls(size-1 + REDZONE_ALIGN +
2 * sizeof(unsigned long long)))
flags |= SLAB_RED_ZONE | SLAB_STORE_USER;
if (!(flags & SLAB_DESTROY_BY_RCU))
flags |= SLAB_POISON;
#endif
if (flags & SLAB_DESTROY_BY_RCU)
BUG_ON(flags & SLAB_POISON);
#endif
/*
* Always checks flags, a caller might be expecting debug support which
* isn't available.
*/
BUG_ON(flags & ~CREATE_MASK);
/*
* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
/*如果缓存对象大小没有对齐到处理器字长,则对齐之*/
if (size & (BYTES_PER_WORD - 1)) {
size += (BYTES_PER_WORD - 1);
size &= ~(BYTES_PER_WORD - 1);
}
/* calculate the final buffer alignment: */
/* 1) arch recommendation: can be overridden for debug */
/*要求按照体系结构对齐*/
if (flags & SLAB_HWCACHE_ALIGN) {
/*
* Default alignment: as specified by the arch code. Except if
* an object is really small, then squeeze multiple objects into
* one cacheline.
*/
ralign = cache_line_size();/*对齐值取L1缓存行的大小*/
/*如果对象大小足够小,则不断压缩对齐值以保证能将足够多的对象装入一个缓存行*/
while (size <= ralign / 2)
ralign /= 2;
} else {
ralign = BYTES_PER_WORD; /*对齐值取处理器字长*/
}
/*
* Redzoning and user store require word alignment or possibly larger.
* Note this will be overridden by architecture or caller mandated
* alignment if either is greater than BYTES_PER_WORD.
*/
/*如果开启了DEBUG,则按需要进行相应的对齐*/
if (flags & SLAB_STORE_USER)
ralign = BYTES_PER_WORD;
if (flags & SLAB_RED_ZONE) {
ralign = REDZONE_ALIGN;
/* If redzoning, ensure that the second redzone is suitably
* aligned, by adjusting the object size accordingly. */
size += REDZONE_ALIGN - 1;
size &= ~(REDZONE_ALIGN - 1);
}
/* 2) arch mandated alignment */
if (ralign < ARCH_SLAB_MINALIGN) {
ralign = ARCH_SLAB_MINALIGN;
}
/* 3) caller mandated alignment */
if (ralign < align) {
ralign = align;
}
/* disable debug if necessary */
if (ralign > __alignof__(unsigned long long))
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
/*
* 4) Store it.
*/
align = ralign;
if (slab_is_available())
gfp = GFP_KERNEL;
else
gfp = GFP_NOWAIT;
/* Get cache's description obj. */
/*从cache_cache中分配一个高速缓存描述符*/
cachep = kmem_cache_zalloc(&cache_cache, gfp);
if (!cachep)
goto oops;
#if DEBUG
cachep->obj_size = size;
/*
* Both debugging options require word-alignment which is calculated
* into align above.
*/
if (flags & SLAB_RED_ZONE) {
/* add space for red zone words */
cachep->obj_offset += sizeof(unsigned long long);
size += 2 * sizeof(unsigned long long);
}
if (flags & SLAB_STORE_USER) {
/* user store requires one word storage behind the end of
* the real object. But if the second red zone needs to be
* aligned to 64 bits, we must allow that much space.
*/
if (flags & SLAB_RED_ZONE)
size += REDZONE_ALIGN;
else
size += BYTES_PER_WORD;
}
#if FORCED_DEBUG && defined(CONFIG_DEBUG_PAGEALLOC)
if (size >= malloc_sizes[INDEX_L3 + 1].cs_size
&& cachep->obj_size > cache_line_size() && ALIGN(size, align) < PAGE_SIZE) {
cachep->obj_offset += PAGE_SIZE - ALIGN(size, align);
size = PAGE_SIZE;
}
#endif
#endif
/*
* Determine if the slab management is 'on' or 'off' slab.
* (bootstrapping cannot cope with offslab caches so don't do
* it too early on.)
*/
/*如果缓存对象的大小不小于页面大小的1/8并且不处于slab初始化阶段,
则选择将slab描述符放在slab外部以腾出更多的空间给对象*/
if ((size >= (PAGE_SIZE >> 3)) && !slab_early_init)
/*
* Size is large, assume best to place the slab management obj
* off-slab (should allow better packing of objs).
*/
flags |= CFLGS_OFF_SLAB;
/*将对象大小按之前确定的align对齐*/
size = ALIGN(size, align);
/*计算slab的对象数,分配给slab的页框阶数并返回slab的剩余空间,即碎片大小*/
left_over = calculate_slab_order(cachep, size, align, flags);
if (!cachep->num) {
printk(KERN_ERR
"kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto oops;
}
/*将slab管理区的大小按align进行对齐*/
slab_size = ALIGN(cachep->num * sizeof(kmem_bufctl_t)
+ sizeof(struct slab), align);
/*
* If the slab has been placed off-slab, and we have enough space then
* move it on-slab. This is at the expense of any extra colouring.
*/
/*如果之前确定将slab管理区放在slab外部,但是碎片空间大于slab管理区大小,
这时改变策略将slab管理区放在slab内部,这样可以节省外部空间,但是会牺牲
着色的颜色个数*/
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
/*如果的确要将slab管理区放在外部,则不需按照该slab的对齐方式进行对齐了,
重新计算slab_size*/
if (flags & CFLGS_OFF_SLAB) {
/* really off slab. No need for manual alignment */
slab_size =
cachep->num * sizeof(kmem_bufctl_t) + sizeof(struct slab);
#ifdef CONFIG_PAGE_POISONING
/* If we're going to use the generic kernel_map_pages()
* poisoning, then it's going to smash the contents of
* the redzone and userword anyhow, so switch them off.
*/
if (size % PAGE_SIZE == 0 && flags & SLAB_POISON)
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
#endif
}
/*着色偏移区L1缓存行的大小*/
cachep->colour_off = cache_line_size();
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < align)/*着色偏移小于align的话则要取对齐值*/
cachep->colour_off = align;
/*计算着色的颜色数目*/
cachep->colour = left_over / cachep->colour_off;
cachep->slab_size = slab_size;
cachep->flags = flags;
cachep->gfpflags = 0;
if (CONFIG_ZONE_DMA_FLAG && (flags & SLAB_CACHE_DMA))
cachep->gfpflags |= GFP_DMA;
cachep->buffer_size = size;
cachep->reciprocal_buffer_size = reciprocal_value(size);
if (flags & CFLGS_OFF_SLAB) {
cachep->slabp_cache = kmem_find_general_cachep(slab_size, 0u);
/*
* This is a possibility for one of the malloc_sizes caches.
* But since we go off slab only for object size greater than
* PAGE_SIZE/8, and malloc_sizes gets created in ascending order,
* this should not happen at all.
* But leave a BUG_ON for some lucky dude.
*/
BUG_ON(ZERO_OR_NULL_PTR(cachep->slabp_cache));
}
cachep->ctor = ctor;
cachep->name = name;
if (setup_cpu_cache(cachep, gfp)) {
__kmem_cache_destroy(cachep);
cachep = NULL;
goto oops;
}
/* cache setup completed, link it into the list */
/*将该高速缓存描述符添加进cache_chain*/
list_add(&cachep->next, &cache_chain);
oops:
if (!cachep && (flags & SLAB_PANIC))
panic("kmem_cache_create(): failed to create slab `%s'\n",
name);
if (slab_is_available()) {
mutex_unlock(&cache_chain_mutex);
put_online_cpus();
}
return cachep;
}
static size_t calculate_slab_order(struct kmem_cache *cachep,
size_t size, size_t align, unsigned long flags)
{
unsigned long offslab_limit;
size_t left_over = 0;
int gfporder;
for (gfporder = 0; gfporder <= KMALLOC_MAX_ORDER; gfporder++) {
unsigned int num;
size_t remainder;
/*根据gfporder计算对象数和剩余空间*/
cache_estimate(gfporder, size, align, flags, &remainder, &num);
if (!num)/*如果计算出来的对象数为0则要增大分配给slab的页框阶数再进行计算*/
continue;
if (flags & CFLGS_OFF_SLAB) {
/*
* Max number of objs-per-slab for caches which
* use off-slab slabs. Needed to avoid a possible
* looping condition in cache_grow().
*/
/*offslab_limit记录了在外部存储slab描述符时所允许的slab最大对象数*/
offslab_limit = size - sizeof(struct slab);
offslab_limit /= sizeof(kmem_bufctl_t);
/*如果前面计算出的对象数num要大于允许的最大对象数,则不合法*/
if (num > offslab_limit)
break;
}
/* Found something acceptable - save it away */
cachep->num = num;
cachep->gfporder = gfporder;
left_over = remainder;
/*
* A VFS-reclaimable slab tends to have most allocations
* as GFP_NOFS and we really don't want to have to be allocating
* higher-order pages when we are unable to shrink dcache.
*/
if (flags & SLAB_RECLAIM_ACCOUNT)
break;
/*
* Large number of objects is good, but very large slabs are
* currently bad for the gfp()s.
*/
if (gfporder >= slab_break_gfp_order)
break;
/*
* Acceptable internal fragmentation?
*/
if (left_over * 8 <= (PAGE_SIZE << gfporder))
break;
}
return left_over;
}
static void cache_estimate(unsigned long gfporder, size_t buffer_size,
size_t align, int flags, size_t *left_over,
unsigned int *num)
{
int nr_objs;
size_t mgmt_size;
size_t slab_size = PAGE_SIZE << gfporder;
/*
* The slab management structure can be either off the slab or
* on it. For the latter case, the memory allocated for a
* slab is used for:
*
* - The struct slab
* - One kmem_bufctl_t for each object
* - Padding to respect alignment of @align
* - @buffer_size bytes for each object
*
* If the slab management structure is off the slab, then the
* alignment will already be calculated into the size. Because
* the slabs are all pages aligned, the objects will be at the
* correct alignment when allocated.
*/
/*如果slab描述符存储在slab外部,则slab的对象数即为slab_size/buffer_size*/
if (flags & CFLGS_OFF_SLAB) {
mgmt_size = 0;
nr_objs = slab_size / buffer_size;
if (nr_objs > SLAB_LIMIT)
nr_objs = SLAB_LIMIT;
} else {/*否则先减去slab管理区的大小再进行计算*/
/*
* Ignore padding for the initial guess. The padding
* is at most @align-1 bytes, and @buffer_size is at
* least @align. In the worst case, this result will
* be one greater than the number of objects that fit
* into the memory allocation when taking the padding
* into account.
*/
nr_objs = (slab_size - sizeof(struct slab)) /
(buffer_size + sizeof(kmem_bufctl_t));
/*
* This calculated number will be either the right
* amount, or one greater than what we want.
*/
if (slab_mgmt_size(nr_objs, align) + nr_objs*buffer_size
> slab_size)
nr_objs--;
if (nr_objs > SLAB_LIMIT)
nr_objs = SLAB_LIMIT;
/*计算slab管理区的大小*/
mgmt_size = slab_mgmt_size(nr_objs, align);
}
/*保存slab对象数*/
*num = nr_objs;
/*计算并保存slab的剩余空间*/
*left_over = slab_size - nr_objs*buffer_size - mgmt_size;
}
static int enable_cpucache(struct kmem_cache *cachep, gfp_t gfp)
{
int err;
int limit, shared;
/*
* The head array serves three purposes:
* - create a LIFO ordering, i.e. return objects that are cache-warm
* - reduce the number of spinlock operations.
* - reduce the number of linked list operations on the slab and
* bufctl chains: array operations are cheaper.
* The numbers are guessed, we should auto-tune as described by
* Bonwick.
*/
/*根据对象的大小来确定本地高速缓存中的空闲对象上限*/
if (cachep->buffer_size > 131072)
limit = 1;
else if (cachep->buffer_size > PAGE_SIZE)
limit = 8;
else if (cachep->buffer_size > 1024)
limit = 24;
else if (cachep->buffer_size > 256)
limit = 54;
else
limit = 120;
/*
* CPU bound tasks (e.g. network routing) can exhibit cpu bound
* allocation behaviour: Most allocs on one cpu, most free operations
* on another cpu. For these cases, an efficient object passing between
* cpus is necessary. This is provided by a shared array. The array
* replaces Bonwick's magazine layer.
* On uniprocessor, it's functionally equivalent (but less efficient)
* to a larger limit. Thus disabled by default.
*/
shared = 0;
if (cachep->buffer_size <= PAGE_SIZE && num_possible_cpus() > 1)
shared = 8;
#if DEBUG
/*
* With debugging enabled, large batchcount lead to excessively long
* periods with disabled local interrupts. Limit the batchcount
*/
if (limit > 32)
limit = 32;
#endif
err = do_tune_cpucache(cachep, limit, (limit + 1) / 2, shared, gfp);
if (err)
printk(KERN_ERR "enable_cpucache failed for %s, error %d.\n",
cachep->name, -err);
return err;
}
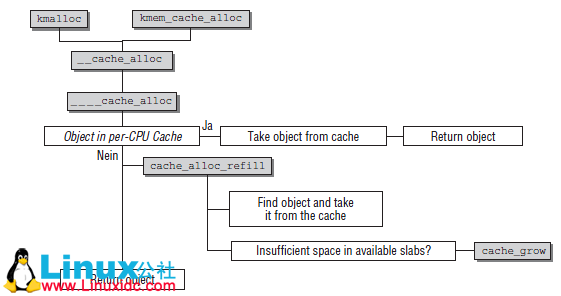
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
/*获取缓存的本地高速缓存的描述符array_cache*/
ac = cpu_cache_get(cachep);
/*如果本地高速缓存中还有空闲对象可以分配则从本地高速缓存中分配*/
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
/*先将avail的值减1,这样avail对应的空闲对象是最热的,即最近释放出来的,
更有可能驻留在CPU高速缓存中*/
objp = ac->entry[--ac->avail];
} else {/*否则需要填充本地高速缓存*/
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
}
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_list3 *l3;
struct array_cache *ac;
int node;
retry:
check_irq_off();
node = numa_node_id();
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount; /*获取批量转移的数目*/
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
/*获取kmem_list3*/
l3 = cachep->nodelists[node];
BUG_ON(ac->avail > 0 || !l3);
spin_lock(&l3->list_lock);
/* See if we can refill from the shared array */
/*如果有共享本地高速缓存,则从共享本地高速缓存填充*/
if (l3->shared && transfer_objects(ac, l3->shared, batchcount))
goto alloc_done;
while (batchcount > 0) {
struct list_head *entry;
struct slab *slabp;
/* Get slab alloc is to come from. */
/*扫描slab链表,先从partial链表开始,如果整个partial链表都无法找到batchcount个空闲对象,
再扫描free链表*/
entry = l3->slabs_partial.next;
/*entry回到表头说明partial链表已经扫描完毕,开始扫描free链表*/
if (entry == &l3->slabs_partial) {
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free)
goto must_grow;
}
/*由链表项得到slab描述符*/
slabp = list_entry(entry, struct slab, list);
check_slabp(cachep, slabp);
check_spinlock_acquired(cachep);
/*
* The slab was either on partial or free list so
* there must be at least one object available for
* allocation.
*/
BUG_ON(slabp->inuse >= cachep->num);
/*如果slabp中还存在空闲对象并且还需要继续填充对象到本地高速缓存*/
while (slabp->inuse < cachep->num && batchcount--) {
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
/*填充的本质就是用ac后面的void*数组元素指向一个空闲对象*/
ac->entry[ac->avail++] = slab_get_obj(cachep, slabp,
node);
}
check_slabp(cachep, slabp);
/* move slabp to correct slabp list: */
/*由于从slab中分配出去了对象,因此有可能需要将slab移到其他链表中去*/
list_del(&slabp->list);
/*free等于BUFCTL_END表示空闲对象已耗尽,将slab插入full链表*/
if (slabp->free == BUFCTL_END)
list_add(&slabp->list, &l3->slabs_full);
else/*否则肯定是插入partial链表*/
list_add(&slabp->list, &l3->slabs_partial);
}
must_grow:
l3->free_objects -= ac->avail;/*刷新kmem_list3中的空闲对象*/
alloc_done:
spin_unlock(&l3->list_lock);
/*avail为0表示kmem_list3中的slab全部处于full状态或者没有slab,则要为缓存分配slab*/
if (unlikely(!ac->avail)) {
int x;
x = cache_grow(cachep, flags | GFP_THISNODE, node, NULL);
/* cache_grow can reenable interrupts, then ac could change. */
ac = cpu_cache_get(cachep);
if (!x && ac->avail == 0) /* no objects in sight? abort */
return NULL;
if (!ac->avail) /* objects refilled by interrupt? */
goto retry;
}
ac->touched = 1;
/*返回最后一个末端的对象*/
return ac->entry[--ac->avail];
}
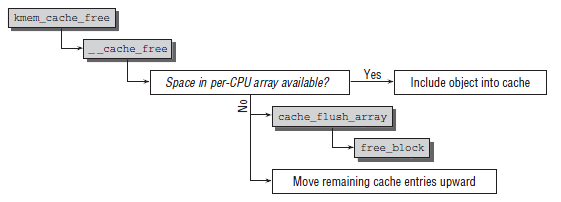
static inline void __cache_free(struct kmem_cache *cachep, void *objp)
{
struct array_cache *ac = cpu_cache_get(cachep);
check_irq_off();
kmemleak_free_recursive(objp, cachep->flags);
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
kmemcheck_slab_free(cachep, objp, obj_size(cachep));
/*
* Skip calling cache_free_alien() when the platform is not numa.
* This will avoid cache misses that happen while accessing slabp (which
* is per page memory reference) to get nodeid. Instead use a global
* variable to skip the call, which is mostly likely to be present in
* the cache.
*/
if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))
return;
/*如果本地高速缓存中的空闲对象小于空闲对象上限,则直接用entry中的元素记录对象的地址*/
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac->entry[ac->avail++] = objp;
return;
} else {/*否则将本地高速缓存中的空闲对象批量转移到slab中*/
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac->entry[ac->avail++] = objp;
}
}
static void cache_flusharray(struct kmem_cache *cachep, struct array_cache *ac)
{
int batchcount;
struct kmem_list3 *l3;
int node = numa_node_id();
batchcount = ac->batchcount;
#if DEBUG
BUG_ON(!batchcount || batchcount > ac->avail);
#endif
check_irq_off();
l3 = cachep->nodelists[node];
spin_lock(&l3->list_lock);
if (l3->shared) {/*如果开启了共享本地高速缓存*/
/*获取共享的array_cache*/
struct array_cache *shared_array = l3->shared;
/*计算共享本地高速缓存还可容纳的空闲对象数*/
int max = shared_array->limit - shared_array->avail;
if (max) {
if (batchcount > max)
batchcount = max;
/*将batchcount个对象移到共享本地高速缓存中*/
memcpy(&(shared_array->entry[shared_array->avail]),
ac->entry, sizeof(void *) * batchcount);
shared_array->avail += batchcount;
goto free_done;
}
}
/*将本地高速缓存的前batchcount个对象放回slab*/
free_block(cachep, ac->entry, batchcount, node);
free_done:
#if STATS
{
int i = 0;
struct list_head *p;
p = l3->slabs_free.next;
while (p != &(l3->slabs_free)) {
struct slab *slabp;
slabp = list_entry(p, struct slab, list);
BUG_ON(slabp->inuse);
i++;
p = p->next;
}
STATS_SET_FREEABLE(cachep, i);
}
#endif
spin_unlock(&l3->list_lock);
ac->avail -= batchcount;/*刷新本地高速缓存的avail值*/
/*将从batchcount开始的元素搬到前面去*/
memmove(ac->entry, &(ac->entry[batchcount]), sizeof(void *)*ac->avail);
}
/*
* Release an obj back to its cache. If the obj has a constructed state, it must
* be in this state _before_ it is released. Called with disabled ints.
*/
static inline void __cache_free(struct kmem_cache *cachep, void *objp)
{
struct array_cache *ac = cpu_cache_get(cachep);
check_irq_off();
kmemleak_free_recursive(objp, cachep->flags);
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
kmemcheck_slab_free(cachep, objp, obj_size(cachep));
/*
* Skip calling cache_free_alien() when the platform is not numa.
* This will avoid cache misses that happen while accessing slabp (which
* is per page memory reference) to get nodeid. Instead use a global
* variable to skip the call, which is mostly likely to be present in
* the cache.
*/
if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))
return;
/*如果本地高速缓存中的空闲对象小于空闲对象上限,则直接用entry中的元素记录对象的地址*/
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac->entry[ac->avail++] = objp;
return;
} else {/*否则将本地高速缓存中的空闲对象批量转移到slab中*/
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac->entry[ac->avail++] = objp;
}
}
static void free_block(struct kmem_cache *cachep, void **objpp, int nr_objects,
int node)
{
int i;
struct kmem_list3 *l3;
for (i = 0; i < nr_objects; i++) {
void *objp = objpp[i];
struct slab *slabp;
/*通过对象的虚拟地址得到slab描述符*/
slabp = virt_to_slab(objp);
/*获取kmem_list3*/
l3 = cachep->nodelists[node];
/*先将slab从所在链表中删除*/
list_del(&slabp->list);
check_spinlock_acquired_node(cachep, node);
check_slabp(cachep, slabp);
/*将一个对象放回slab上*/
slab_put_obj(cachep, slabp, objp, node);
STATS_DEC_ACTIVE(cachep);
/*kmem_list3中的空闲对象数加1*/
l3->free_objects++;
check_slabp(cachep, slabp);
/* fixup slab chains */
/*slab的对象全部空闲*/
if (slabp->inuse == 0) {
/*如果空闲对象数大于了空闲对象上限*/
if (l3->free_objects > l3->free_limit) {
/*总空闲对象数减去一个slab的对象数*/
l3->free_objects -= cachep->num;
/* No need to drop any previously held
* lock here, even if we have a off-slab slab
* descriptor it is guaranteed to come from
* a different cache, refer to comments before
* alloc_slabmgmt.
*/
/*销毁该slab*/
slab_destroy(cachep, slabp);
} else {
/*将该slab添加到free链表*/
list_add(&slabp->list, &l3->slabs_free);
}
} else {/*否则添加到partial链表*/
/* Unconditionally move a slab to the end of the
* partial list on free - maximum time for the
* other objects to be freed, too.
*/
list_add_tail(&slabp->list, &l3->slabs_partial);
}
}
}
static void slab_put_obj(struct kmem_cache *cachep, struct slab *slabp,
void *objp, int nodeid)
{
/*得到对象的偏移*/
unsigned int objnr = obj_to_index(cachep, slabp, objp);
#if DEBUG
/* Verify that the slab belongs to the intended node */
WARN_ON(slabp->nodeid != nodeid);
if (slab_bufctl(slabp)[objnr] + 1 <= SLAB_LIMIT + 1) {
printk(KERN_ERR "slab: double free detected in cache "
"'%s', objp %p\n", cachep->name, objp);
BUG();
}
#endif
/*bufctl数组的相应元素更新为free*/
slab_bufctl(slabp)[objnr] = slabp->free;
/*free更新为objnr*/
slabp->free = objnr;
/*非空闲数减1*/
slabp->inuse--;
}
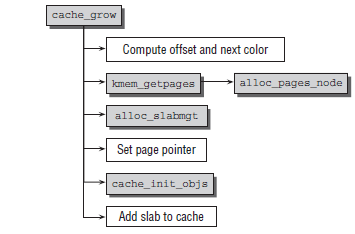
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
struct slab *slabp;
size_t offset;
gfp_t local_flags;
struct kmem_list3 *l3;
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
BUG_ON(flags & GFP_SLAB_BUG_MASK);
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
/* Take the l3 list lock to change the colour_next on this node */
check_irq_off();
l3 = cachep->nodelists[nodeid];
spin_lock(&l3->list_lock);
/* Get colour for the slab, and cal the next value. */
/*确定待创建的slab的颜色编号*/
offset = l3->colour_next;
/*更新下一个slab的颜色编号*/
l3->colour_next++;
/*颜色编号必须小于颜色数*/
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
spin_unlock(&l3->list_lock);
/*确定待创建的slab的颜色*/
offset *= cachep->colour_off;
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
if (!objp)
/*从伙伴系统分配页框,这是slab分配器与伙伴系统的接口*/
objp = kmem_getpages(cachep, local_flags, nodeid);
if (!objp)
goto failed;
/* Get slab management. */
/*分配slab管理区*/
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
if (!slabp)
goto opps1;
/*建立页面到slab和cache的映射,以便于根据obj迅速定位slab描述符和cache描述符*/
slab_map_pages(cachep, slabp, objp);
/*初始化对象*/
cache_init_objs(cachep, slabp);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&l3->list_lock);
/* Make slab active. */
/*将新创建的slab添加到free链表*/
list_add_tail(&slabp->list, &(l3->slabs_free));
STATS_INC_GROWN(cachep);
l3->free_objects += cachep->num;
spin_unlock(&l3->list_lock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags,
int nodeid)
{
struct slab *slabp;
/*如果slab管理区位于slab外,则在指定的slabp_cache中分配空间*/
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
slabp = kmem_cache_alloc_node(cachep->slabp_cache,
local_flags, nodeid);
/*
* If the first object in the slab is leaked (it's allocated
* but no one has a reference to it), we want to make sure
* kmemleak does not treat the ->s_mem pointer as a reference
* to the object. Otherwise we will not report the leak.
*/
kmemleak_scan_area(slabp, offsetof(struct slab, list),
sizeof(struct list_head), local_flags);
if (!slabp)
return NULL;
} else {/*slab管理区处于slab中*/
/*slab管理区从slab首部偏移颜色值的地方开始*/
slabp = objp + colour_off;
colour_off += cachep->slab_size;
}
slabp->inuse = 0;/*对象全为空闲*/
slabp->colouroff = colour_off; /*刷新第一个对象的偏移*/
slabp->s_mem = objp + colour_off;/*确定第一个对象的位置*/
slabp->nodeid = nodeid;/*标识节点*/
slabp->free = 0; /*下一个空闲对象位于s_mem起始处*/
return slabp;
}
static void cache_init_objs(struct kmem_cache *cachep,
struct slab *slabp)
{
int i;
for (i = 0; i < cachep->num; i++) {
/*得到第i个对象*/
void *objp = index_to_obj(cachep, slabp, i);
#if DEBUG /*Debug相关操作*/
/* need to poison the objs? */
if (cachep->flags & SLAB_POISON)
poison_obj(cachep, objp, POISON_FREE);
if (cachep->flags & SLAB_STORE_USER)
*dbg_userword(cachep, objp) = NULL;
if (cachep->flags & SLAB_RED_ZONE) {
*dbg_redzone1(cachep, objp) = RED_INACTIVE;
*dbg_redzone2(cachep, objp) = RED_INACTIVE;
}
/*
* Constructors are not allowed to allocate memory from the same
* cache which they are a constructor for. Otherwise, deadlock.
* They must also be threaded.
*/
if (cachep->ctor && !(cachep->flags & SLAB_POISON))
cachep->ctor(objp + obj_offset(cachep));
if (cachep->flags & SLAB_RED_ZONE) {
if (*dbg_redzone2(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "constructor overwrote the"
" end of an object");
if (*dbg_redzone1(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "constructor overwrote the"
" start of an object");
}
if ((cachep->buffer_size % PAGE_SIZE) == 0 &&
OFF_SLAB(cachep) && cachep->flags & SLAB_POISON)
kernel_map_pages(virt_to_page(objp),
cachep->buffer_size / PAGE_SIZE, 0);
#else
if (cachep->ctor)/*根据构造函数初始化对象*/
cachep->ctor(objp);
#endif
slab_bufctl(slabp)[i] = i + 1;/*确定下一个空闲对象为后面相邻的对象*/
}
slab_bufctl(slabp)[i - 1] = BUFCTL_END;
}