

http://book.51cto.com/art/201206/345040.htm
一、SKB的缓存池
网络模块中,有两个用来分配SKB描述符的高速缓存,在SKB模块初始函数skb_init()中被创建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
2050-2054 创建skbuff_head_cache高速缓存,一般情况下,SKB都是从该高速缓存中分配的。
2055-2060 创建每次以两倍SKB描述符长度来分配空间的skbuff_fclone_cache高速缓存。如果在分配SKB时就知道可能被克隆,那么应该从这个高速缓存中分配空间,因为在这个高速缓存中分配SKB时,会同时分配一个后备的SKB,以便将来用于克隆,这样在克隆时就不用再次分配SKB了,直接使用后备的SKB即可,这样做的目的主要是提高效率。
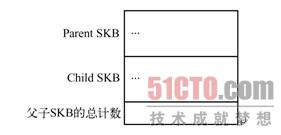
两个高速缓存的区别在于创建时指定的单位内存区域大小不同,skbuff_head_cache的单位内存区域长度是sizeof(struct sk_buff),而skbuff_fclone_cache的单位内存区域长度是2*sizeof(struct sk_buff)+sizeof(atomic_t),即一对SKB和一个引用计数,可以说这一对SKB是"父子"关系,指向同一个数据缓存区,引用计数值为0,1或2,用来表示这一对SKB中有几个已被使用,如图3-12所示。
二、分配SKB
1. alloc_skb()
alloc_skb()用来分配SKB。数据缓存区和SKB描述符是两个不同的实体,这就意味着,在分配一个SKB时,需要分配两块内存,一块是数据缓存区,一块是SKB描述符。__alloc_skb()调用kmem_cache_alloc_node()从高速缓存中获取一个sk_buff结构的空间,然后调用kmalloc_node_track_caller()分配数据缓存区。参数说明如下:
size,待分配SKB的线性存储区的长度。
gfp_mask,分配内存的方式,见表25-3。
fclone,预测是否会克隆,用于确定从哪个高速缓存中分配。
node,当支持NUMA(非均匀质存储结构)时,用于确定何种区域中分配SKB。NUMA参见相关资料。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | |
152 根据参数fclone确定从哪个高速缓存中分配SKB。
155 调用kmem_cache_alloc_node()从选定的高速缓存中分配一个SKB。在此从分配标志中去除GFP_DMA,是为了不从DMA内存区域中分配SKB描述符,因为DMA内存区域比较小且有特定用途,没有必要用来分配SKB描述符。而后面分配数据缓存区时,就不会去掉GFP_DMA标志,因为很有可能数据缓存区就需要在DMA内存区域中分配,这样硬件可以直接进行DMA操作,参见161~162行。
160 在分配数据缓存区之前,强制对给定的数据缓存区大小size作对齐操作。
161-165 调用kmalloc_node_track_caller()分配数据缓存区,其长度为size和sizeof(struct skb_shared_info)之和,因为在缓存区尾部紧跟着一个skb_shared_info结构。
168-181 初始化新分配SKB描述符和skb_shared_info结构。
183-191 如果是skbuff_fclone_cache高速缓存中分配SKB描述符,则还需置父SKB描述符的fclone为SKB_FCLONE_ORIG,表示可以被克隆;同时将子SKB描述符的fclone成员置为SKB_FCLONE_UNAVAILABLE,表示该SKB还没有被创建出来;最后将引用计数置为1。
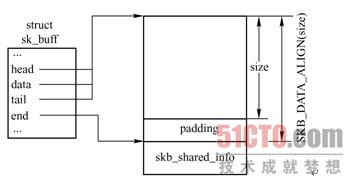
最后SKB结构如图3-13所示,在图右边所示的内存块中部,可以看到对齐操作所带来的填充区域。需要说明的是,__alloc_skb()一般不被直接调用,而是被封装函数调用,如__netdev_alloc_skb()、alloc_skb()、alloc_skb_fclone()等函数。
2. dev_alloc_skb()
dev_alloc_skb()也是一个缓存区分配函数,通常被设备驱动用在中断上下文中。这是一个alloc_skb()的封装函数,因为是在中断处理函数中被调用的,因此要求原子操作(GFP_ATOMIC)。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1108 调用skb_reserve()在skb->head与skb->data之间预留NET_SKB_PAD个字节。NET_SKB_PAD的定义在skbuff.h中,其值为 16。这部分空间将被填入硬件帧头,如14B的以太网帧头。
1126 以GFP_ATOMIC为内存分配优先级,表示分配过程为原子操作,不能被中断。
三、释放SKB
dev_kfree_skb()和kfree_skb()用来释放SKB,把它返回给高速缓存。kfree_skb()可以直接调用,也可以通过封装函数dev_kfree_skb()来调用。而dev_kfree_skb()只是一个简单调用kfree_skb()的宏,一般为设备驱动使用,与之功能相反的函数是dev_alloc_skb()。这些函数只在skb->users为1的情况下才释放内存,否则只简单地递减skb->users,因此假设SKB有三个引用者,那么只有第三次调用dev_kfree_skb()或kfree_skb()时才释放内存。kfree_skb()的流程如图3-14所示。
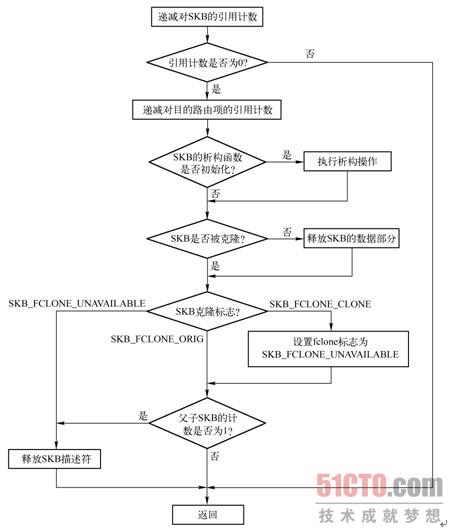
图3-14所示的流程显示了释放一个SKB的步骤:
1)kfree_skb()检测sk_buff结构的引用计数users,如果不为1,则说明此次释放后该SKB还将被用户占用,因此递减引用计数users后即返回;否则说明不再有其他用户占用该sk_buff结构,调用__kfree_skb()释放之。
2)SKB描述符中包含一个dst_entry结构的引用,在释放SKB后,会调用dst_release()来递减dst_entry结构的引用计数。
3)如果初始化了SKB的析构函数,则调用相应的函数。
4)一个SKB描述符是与一个存有真正数据的内存块,即数据区相关的。如果存在聚合分散I/O数据,该数据区底部的skb_shared_info结构还会包含指向聚合分散I/O数据的指针,同样需要释放这些分片所占用的内存。最后需把SKB描述符所占内存返回给skbuff_head_cache缓存。释放内存由kfree_skbmem()处理,过程如下:
如果SKB没有被克隆,或者payload没有被单独引用,则释放SKB的数据缓存区,包括存储聚合分散I/O数据的缓存区和SKB描述符。
如果是释放从skbuff_fclone_cache中分配的父SKB描述符,且克隆计数为1,则释放父SKB描述符。
如果是释放从skbuff_fclone_cache中分配的子SKB描述符,设置父SKLB的fclone字段为SKB_FCLONE_UNAVAILABLE,在克隆计数为1的情况下,释放子SKB描述符。
四、数据预留和对齐
数据预留和对齐主要由skb_reserve()、skb_put()、skb_push()以及skb_pull()这几个函数来完成。
1. skb_reserve()
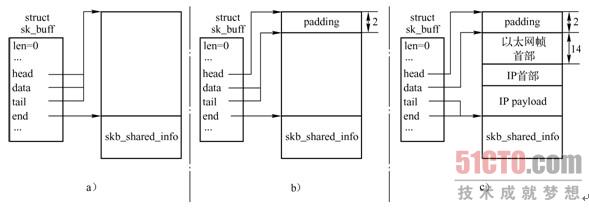
skb_reserve()在数据缓存区头部预留一定的空间,通常被用来在数据缓存区中插入协议首部或者在某个边界上对齐。它并没有把数据移出或移入数据缓存区,而只是简单地更新了数据缓存区的两个指针-分别指向负载起始和结尾的data和tail指针,图3-15 展示了调用skb_reserve()前后这两个指针的变化。
请注意:skb_reserve()只能用于空的SKB,通常会在分配SKB之后就调用该函数,此时data和tail指针还一同指向数据区的起始位置,如图3-15a所示。例如,某个以太网设备驱动的接收函数,在分配SKB之后,向数据缓存区填充数据之前,会有这样的一条语句skb_reserve(skb, 2),这是因为以太网头长度为14B,再加上2B就正好16字节边界对齐,所以大多数以太网设备都会在数据包之前保留2B。
当SKB在协议栈中向下传递时,每一层协议都把skb->data指针向上移动,然后复制本层首部,同时更新skb->len。这些操作都使用图3-15 中所示的函数完成。
2.skb_push()
skb_push()在数据缓存区的前头加入一块数据,与skb_reserve()类似,也并没有真正向数据缓存区中添加数据,而只是移动数据缓存区的头指针data和尾指针tail。数据由其他函数复制到数据缓存区中。
函数执行步骤如下:
1)当TCP发送数据时,会根据一些条件,如TCP最大分段长度MSS、是否支持聚合分散I/O等,分配一个SKB。
2)TCP需在数据缓存区的头部预留足够的空间,用来填充各层首部。MAX_TCP_HEADER是各层首部长度的总和,它考虑了最坏的情况:由于TCP层不知道将要用哪个接口发送包,它为每一层预留了最大的首部长度,甚至还考虑了出现多个IP首部的可能性,因为在内核编译支持IP over IP的情况下,会遇到多个IP首部。
3)把TCP负载复制到数据缓存区。需要注意的是,图3-16 只是一个例子,TCP负载可能会被组织成其他形式,例如分片,在后续章节中将会看到一个分片的数据缓存区是什么样的。
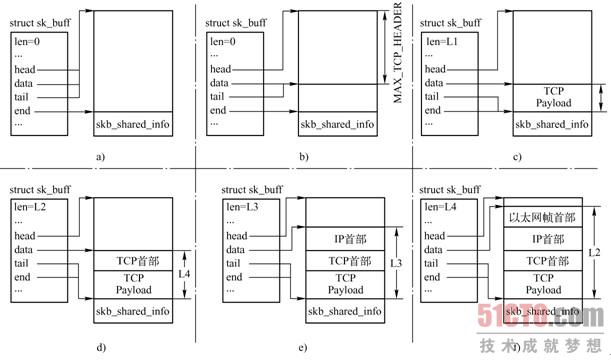
4)TCP层添加TCP首部。
5)SKB传递到IP层,IP层为数据包添加IP首部。
6)SKB传递到链路层,链路层为数据包添加链路层首部。
3.skb_put()
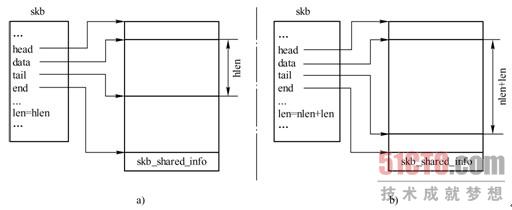
skb_put()修改指向数据区末尾的指针tail,使之往下移len字节,即使数据区向下扩大len字节,并更新数据区长度len。调用skb_put()前后,SKB结构变化如图3-17所示。
4.skb_pull()
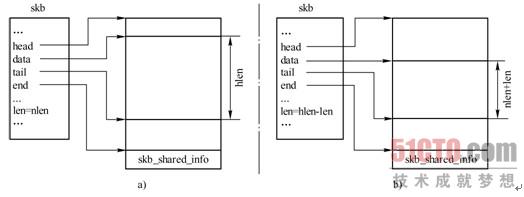
skb_pull()通过将data指针往下移动,在数据区首部忽略len字节长度的数据,通常用于接收到数据包后在各层间由下往上传递时,上层忽略下层的首部。调用skb_pull()前后,SKB结构变化如图3-18所示。
五、克隆和复制SKB
1.skb_clone()
如果一个SKB会被不同的用户独立操作,而这些用户可能只是修改SKB描述符中的某些字段值,如h、nh,则内核没有必要为每个用户复制一份完整的SKB描述及其相应的数据缓存区,而会为了提高性能,只作克隆操作。克隆过程只复制SKB描述符,同时增加数据缓存区的引用计数,以免共享数据被提前释放。完成这些功能的是skb_clone()。一个使用包克隆的场景是,一个接收包程序要把该包传递给多个接收者,例如包处理函数或者一个或多个网络模块。原始的及克隆的SKB描述符的cloned值都会被设置为1,克隆SKB描述符的users值置为1,这样在第一次释放时就会释放掉。同时将数据缓存区引用计数dataref递增1,因为又多了一个克隆SKB描述符指向它。
图3-19 演示的是已克隆的SKB。
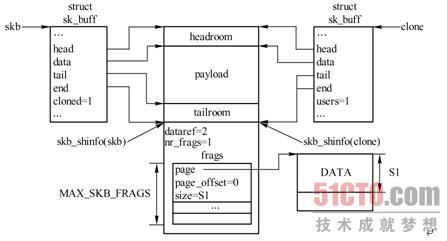
图3-19 所示是一个存在聚合分散I/O缓存区的例子,这个数据缓存区的一些数据保存在分片结构数组frags中。skb_share_check()用来检查SKB引用计数users,如果该字段表明SKB是被共享的,则克隆一个新的SKB。一个SKB被克隆后,该SKB数据缓存区中的内容就不能再被修改,这也意味着访问数据的函数没有必要加锁。skb_cloned()可以用来测试skb的克隆状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | |
436-438 由fclone标志来决定从哪个缓冲池中分配SKB描述符。如果紧邻的两个父子SKB描述符,前一个的fclone为SKB_FCLONE_ORIG,后一个的fclone为SKB_FCLONE_ UNAVAILABLE,则说明这两个SKB描述符是从skbuff_fclone_cache缓冲池中分配的,且父SKB描述符还没有被克隆,即子SKB描述符还是空的。否则即从skbuff_head_cache缓冲池中分配一个新的SKB来用于克隆。
451-508 将父SKB描述符各字段值赋给子SKB描述符的对应字段。
504 设置子SKB描述符引用计数users为1。
510 递增父SKB描述符中的数据区引用计数skb_shared_info结构的dataref。
511 设置父SKB描述符的成员cloned为1,表示该SKB已被克隆。
2.pskb_copy()
当一个函数不仅要修改SKB描述符,而且还要修改数据缓存区中的数据时,就需要同时复制数据缓存区。在这种情况下,程序员有两个选择。如果所修改的数据在skb->head和skb->end之间,可使用pskb_copy()来复制这部分数据,如图3-20所示。
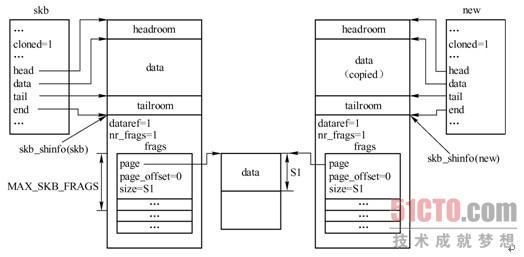
3.skb_copy()
如果同时需要修改聚合分散I/O存储区中的数据,就必须使用skb_copy(),如图3-21所示。从前面的章节中看到,skb_shared_info结构中也包含一个SKB链表frag_list。该链表在pskb_copy()和skb_copy()中的处理方式与frags数组处理方式相同。
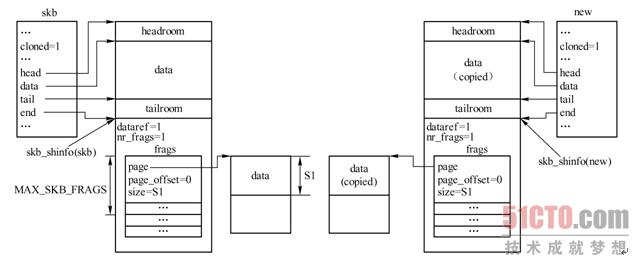
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
589-599 分配一个新的SKB,即包括SKB描述符和数据缓存区,然后在指针head和data之间预留源数据缓存区headroom长度的空间。
601 将新SKB的tail指针和数据区长度len设置为与源SKB的一样。
605-608 复制数据。
在讨论本书中不同主题时,有时会强调某个特定函数需要克隆或者复制一个SKB。在决定克隆或复制SKB时,各子系统程序员不能预测其他内核组件是否需要使用SKB中的原始数据。内核是模块化的,其状态变化是不可预测的,每个子系统都不知道其他子系统是如何操作数据缓存区的。因此,内核程序员需要记录各子系统对数据缓存区的修改,并且在修改数据缓存区前,复制一个新的数据缓存区,以免其他子系统需使用数据缓存区原始数据时出现错误。