

blog.tek-life.com/认识linux物理内存回收机制/
Introduction
本文所讲的物理页面回收是指动态的回收:即,空闲的内存不够用的时候,系统采取相应的方法将正在使用的内存释放,补充空闲内存,以满足内存的分配。
Text
1.All channels for page freeing。首先先简单看一下系统中的内存释放的三种渠道。
1-1>. 在用户进程退出的时候,释放内存。当用户进程退出的时候,会调用do_exit. do_exit最终会调用free_pagetables函数。该函数的作用是:遍历vma,根据vma中的虚拟地址找到实际的物理页,将其释放。在之前讲过,对于用户进程的虚拟地址区间,是以红黑树组织的。
1-2>. 手动的释放。在驱动中,分配内存使用alloc_pages(),释放内存用free_pages(这一点,类似于c语言中的malloc和free)。必须配对使用。否则会造成内存泄漏。
1-3>. 按需求调用内存回收例程来释放内存。这个区别于前两种的最大不同:它是动态的,按需的。当内存不够的时候,系统会自动按照一定的方式,将某些正在使用的内存释放掉,放进buddy system中再利用。
2. Overview for page frame reclaiming。
2-1>. 先来看一下内存将会回收哪些页面
用户进程的页面都是通过page fault进行分配的。通过page fault进行分配的页面都是可以进行回收的。 这些页面总体可以划分为两种,分别是文件页(file cache)和匿名页(anonymous cache). 文件页,顾名思义,它是和外部存储设备上的某个文件相对应。匿名页,其内容不来自于外部存储设备,例如用户进程中的堆栈。这两种页面是内存回收的目标页面。
2-2>. 内存回收采用的主要算法是近似于LRU的算法。位于LRU链表前面的页是活跃的,位于LRU链表后面的页是不活跃的。为什么说是近似呢?
1. 页面在链表上排序并不是严格依据LRU不断移动的。他们挂上去后是不移动的。除非在进行页面回收的时候,有些页面从后面,可能会插入到前面;
2. Linux在LRU的基础上又引入了一个Referrenced标志。这种带Referenced标志的近似LRU的算法被有些人称之为Second-Chance Algorithm.
简单看一下Second-Chance Algorithm. 当一个页从一个LRU链表上除去的时候,需要再看一下Referenced标志。如果该标志设置了,就将其置为0,不能将该页移出。

图1
以图一为例,当某个页面被访问后,Referenced标志被设置。当需要从该list上面回收某些页时,从后向前扫描该list上的页面。对于那些设置为1(Referenced标志被设置),reset为0,不被移出链表。对于那些设置为0的页面,移出链表。
2-3>. Linux为了实现该算法,给每个zone都提供了5个LRU链表。这5个LRU链表分为3类,一类是活跃链表(active list),活跃链表有两个:一个是链接file page cache的LRU list, 另一个是链接anonymous page cache的LRU list. 另一类是非活跃链表(inactive list),非活跃链表也有两个:一个是链接file page cache 的LRU list, 另一个是链接anonymous page cache的LRU list. 内存回收例程从inactive list链表上获取页进行回收。第三类是unevictable链表,这个链表上挂载的是那些被mlock()或者locked的页面。Mlock(),是一个系统调用,用户程序通过该系统调用锁定某些页阻止系统将其换出。被Locked的页面通常是文件系统防止其他进程touch的页面。被锁定的页面都挂载unevictable链表上。
加入到active list链表上的页其page->flags上都要设置PG_active标志。凡是设置了PG_unevictable标志的都要挂载unevictable LRU list上。没有设置PG_active/PG_unevictable标志的都处于inactive状态。处于相关状态的页面通过page->lru 链接到对应的链表上。
当某个页被访问后,提高该页面的活跃度。提高活跃度的方法是:或者对page->flags设置PG_referenced标志,或者对page->flags设置PG_active(同时该物理页面从inactive_list链表上转移到active_list链表上). 有PG_referenced和PG_active标志,可以得到页面的状态,该活跃度由低到高依次为:00->01->10->11
2-4>. 对于一个可回收页面,按照LRU的算法,只有处于inactive状态的页并且没有设置PG_referenced标志位的页才能被回收。但实际上Linux在实现的时候并没有严格按照这中算法,PG_referenced位只是用来参考的。从下面的状态转换图中可以看出这一点。状态转换图一共有4种状态。
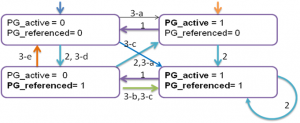
图2
当页面通过page fault被分配的时候,file page cache 被加入到非活动链表中(inactive list), 匿名页(anonymous page cache)被加入到活动链表中(active list)。该状态迁移图所涉及的函数主要有以下几个:shrink_active_list,make_page_accessed,page_check_references。
1)当inactive链表上的页数不够的时候,会调用shrink_active_list,该函数会将active链表上的页move到inactive链表上。对应于上图标号为1的转移;
2). make_page_accessed().
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
当通过read()系统调用或者读已经在cache中的页面时,会提高页面的活跃度。对应于上图标号为2的转移(00->01->10->11); 3) shrink_page_list->page_check_references()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | |
该函数被真正的页面回收函数shrink_page_list调用。所处理的对象是处于inactive状态的页面。分以下几种情况:
3-a). 如果是匿名页,并且最近被访问过(PTE_young置位),对应3-a的转移(Line 726)。即(inactive+PG_referenced)->active,inactive->active. (01->10或者00->10).
3-b). 如果是已经映射的文件页,最近被访问过(PTE_young置位),如果PG_referenced置位或者被两个进程最近访问过(这一点不知道理解的对否)(Line 744~745),对应于3-b的转移(01->11)。
3-c). 如果是已经映射的文件页,最近被访问过(PTE_young置位), 并且该page cache中的内容是可执行的(例如,用户进程的代码段),则inactive->(active+PG_referenced).(00->11, 01->11)
3-d). 如果是已经映射的文件页,最近被访问过(PTE_young置位), 则,设置PG_referenced标志,仍旧保留inactive状态,不进行回收。(00->01,01-01)
3-e). 除了以上情况,均进行回收。即:最近没有被访问过(PTE_YOUNG没有设置)的匿名页和文件页。
对于page_check_references()中的返回值,简单介绍一下:
PAGEREF_RECLAIM:进行回收;
PAGEREF_RECLAIM_CLEAN:若该页是干净的(clean),则进行回收;
PAGEREF_KEEP:仍然保持在inactive LRU list上,不进行回收。
PAGEREF_ACTIVATE:不进行回收,并将该页转移到active LRU list上。
2-5>. 由以上的状态转换图,简单了解一下一个可回收的物理页面可能的生命周期。
Free->inactive->[active]<–>inactive->reclaimable->free
对于一个文件页,其在buddy system中未被分配时,处于free状态。当被分配后,首先挂载在inactive LRU list上。若被进程访问,便会被active。当一段时间没有被访问后,就处于inactive状态,挂载在inactive 链表上等待回收。被回收例程回收后,就进入buddy system中,回归到free状态。
Free->Active<–>[inactive]->reclaimable->free
对于一个匿名页,通过page fault被分配后,挂载在active链表上,然后经过deactive变为inactive然后被回收进buddy system中。
对于匿名页和文件页,刚被分配后所设置的状态,可以得出:系统总是想尽快老化文件页面。在系统的眼中,文件页的换出成本要低于匿名页。
3. Synchronization Reclaiming
当内存分配不足的时候,内存回收例程就会被调用了。相关的代码在__alloc_pages中。
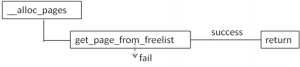
图3
若分配失败,就会进入到__alloc_pages_slowpath中。
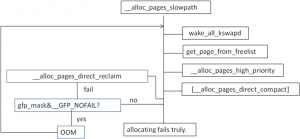
图4
该函数功能正如其名字所属,属于slow path。首先会唤醒各个node上的kswapd例程。kswapd是一个kernel thread,每一个node都有一个例程。该例程的函数体是kswapd().该例程会在第4节中降到。唤醒kwspad后,尝试重新调用get_page_from_freelist,分配内存。若失败,继续往下,如果需要分配内存的主儿在系统中的地位比较重要的话,会调用__alloc_pages_high_priority(). 该函数不会顾及系统设置的安全警告线(min water mark. 对于1GB左右的内存是min water mark是16MB),分配内存。如果仍然失败;则会调用__alloc_pages_direct_compat来migrate内存来达到compat的目的。这个内存的compat类似于磁盘的压缩整理,把在物理内存中正在使用的分散内存,给迁移整合,以便腾出大的连续的物理内存,满足某些进程大页面的需求。需要注意的是,压缩内存需要在build kernel的时候enable CONFIG_COMPACTION。若仍然失败,就调用__alloc_pages_direct_reclaim来回收内存了。回收内存后,会继续调用get_page_from_freelist,尝试看是否能否分配成功。如果仍然失败,并且分配内存的时候要求不允许失败,那么就进入OOM中。OOM主要的功能是选择一个占用内存量比较大的用户进程,杀掉以释放内存。释放结束后,跳到__alloc_pages_slowpath函数的开头,重新执行一遍,以满足内存分配。如果,允许内存分配失败,则就不会OOM了。以分配失败返回给调用者。
__alloc_pages_direct_reclaim函数主要调用try_to_free_pages.
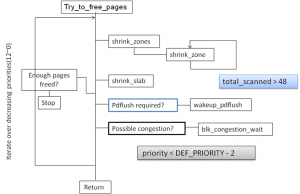
图5
try_to_free_pages()做的事情是,按照自定义的优先级从12开始,递减循环(优先级越小代表级别越高,回收的程度越剧烈)从要分配内存的zone以及其fall-back zone list中回收可用内存释放到buddy system中。它通过调用shrink_zones来达到依次扫描zone以及fall-back zone list的目的。对各个zone进行回收结束后,对slab也进行回收(本文不对slab的回收做分析)。如果至此,已经回收了足够多的内存(32个页),那么就返回。如果没有回收到32个页,则是否需要唤醒pdflush进程,该进程的作用是唤醒块设备的读写进程将脏页写到块设备上。唤醒pdflush的条件是看是否扫描了超过48个页。之后,如果这是的扫描优先级已经小于10了,那么睡眠1/10HZ,即1S.然后递减优先级,进行下一遍的循环。
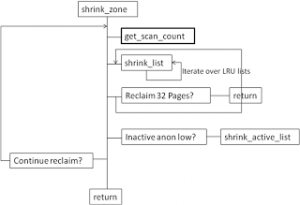
图6
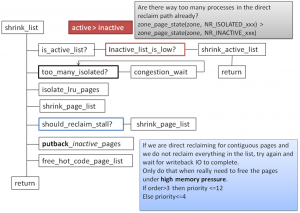
图7
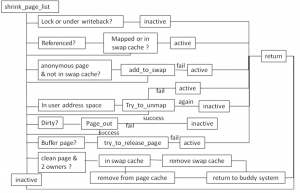
图8
关于swap cache的作用,请看下图(图9)。
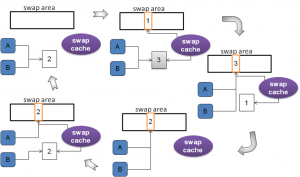
图9
有关对swap cache 作用的描述,最靠谱的分析是来自Understanding Linux Kernel. 摘录如下:
Consider a page P that is shared among two processes, A and B. Initially, the Page Table entries of both processes contain a reference to the page frame, and the page has two owners; this case is illustrated in Figure 17-8(a). When the PFRA selects the page for reclaiming, shrink_list( ) inserts the page frame in the swap cache. As illustrated in Figure 17-8(b), now the page frame has three owners, while the page slot in the swap area is referenced only by the swap cache. Next, the PFRA invokes try_to_unmap( ) to remove the references to the page frame from the Page Table of the processes; once this function terminates, the page frame is referenced only by the swap cache, while the page slot is referenced by the two processes and the swap cache, as illustrated in Figure 17-8©. Let’s suppose that, while the page’s contents are being written to disk, process B accesses the pagethat is, it tries to access a memory cell using a linear address inside the page. Then, the page fault handler finds the page frame in the swap cache and puts back its physical address in the Page Table entry of process B, as illustrated in Figure 17-8(d). Conversely, if the swap-out operation terminates without concurrent swap-in operations,the shrink_list( ) function removes the page frame from the swap cache and releases the page frame to the Buddy system, as illustrated in Figure 17-8(e).
Remark:
- Figure 17-8 请对照图9.
- 上图的函数都是来自于2.6.11内核。本文所参考的内核是3.4.因此引用中的函数可能和本文所述的函数不匹配。
4. Asynchronization reclaiming.
References
- Understanding Linux Kernel (3rd).
- Understanding virtual memory manager (2nd).
- Professional Linux Kernel Architecture.