

http://www.wowotech.net/linux_kenrel/soft-irq.html
一、前言
对于中断处理而言,linux将其分成了两个部分,一个叫做中断handler(top half),是全程关闭中断的,另外一部分是deferable task(bottom half),属于不那么紧急需要处理的事情。在执行bottom half的时候,是开中断的。有多种bottom half的机制,例如:softirq、tasklet、workqueue或是直接创建一个kernel thread来执行bottom half(这在旧的kernel驱动中常见,现在,一个理智的driver厂商是不会这么做的)。本文主要讨论softirq机制。由于tasklet是基于softirq的,因此本文也会提及tasklet,但主要是从需求层面考虑,不会涉及其具体的代码实现。
在普通的驱动中一般是不会用到softirq,但是由于驱动经常使用的tasklet是基于softirq的,因此,了解softirq机制有助于撰写更优雅的driver。softirq不能动态分配,都是静态定义的。内核已经定义了若干种softirq number,例如网络数据的收发、block设备的数据访问(数据量大,通信带宽高),timer的deferable task(时间方面要求高)。本文的第二章讨论了softirq和tasklet这两种机制有何不同,分别适用于什么样的场景。第三章描述了一些context的概念,这是要理解后续内容的基础。第四章是进入softirq的实现,对比hard irq来解析soft irq的注册、触发,调度的过程。
- 注:本文中的linux kernel的版本是3.14
二、为何有softirq和tasklet
1、为何有top half和bottom half
中断处理模块是任何OS中最重要的一个模块,对系统的性能会有直接的影响。想像一下:如果在通过U盘进行大量数据拷贝的时候,你按下一个key,需要半秒的时间才显示出来,这个场景是否让你崩溃?因此,对于那些复杂的、需要大量数据处理的硬件中断,我们不能让handler中处理完一切再恢复现场(handler是全程关闭中断的),而是仅仅在handler中处理一部分,具体包括:
(1)有实时性要求的
(2)和硬件相关的。例如ack中断,read HW FIFO to ram等
(3)如果是共享中断,那么获取硬件中断状态以便判断是否是本中断发生
除此之外,其他的内容都是放到bottom half中处理。在把中断处理过程划分成top half和bottom half之后,关中断的top half被瘦身,可以非常快速的执行完毕,大大减少了系统关中断的时间,提高了系统的性能。
我们可以基于下面的系统进一步的进行讨论:
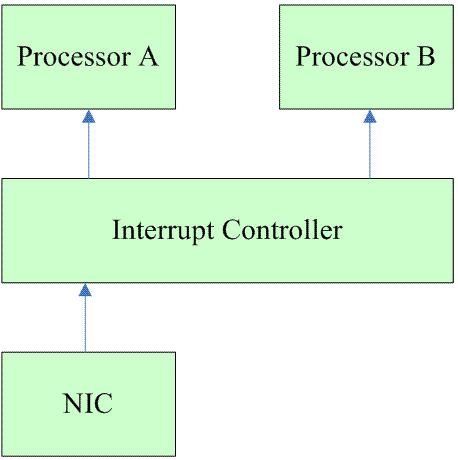
当网卡控制器的FIFO收到的来自以太网的数据的时候(例如半满的时候,可以软件设定),可以将该事件通过irq signal送达Interrupt Controller。Interrupt Controller可以把中断分发给系统中的Processor A or B。
NIC的中断处理过程大概包括:
1
| |
我们先假设Processor A处理了这个网卡中断事件,于是NIC的中断handler在Processor A上欢快的执行,这时候,Processor A的本地中断是disable的。NIC的中断handler在执行的过程中,网络数据仍然源源不断的到来,但是,如果NIC的中断handler不操作NIC的寄存器来ack这个中断的话,NIC是不会触发下一次中断的。还好,我们的NIC interrupt handler总是在最开始就会ack,因此,这不会导致性能问题。ack之后,NIC已经具体再次trigger中断的能力。当Processor A上的handler 在处理接收来自网络的数据的时候,NIC的FIFO很可能又收到新的数据,并trigger了中断,这时候,Interrupt controller还没有umask,因此,即便还有Processor B(也就是说有处理器资源),中断控制器也无法把这个中断送达处理器系统。因此,只能眼睁睁的看着NIC FIFO填满数据,数据溢出,或者向对端发出拥塞信号,无论如何,整体的系统性能是受到严重的影响。
注意:对于新的interrupt controller,可能没有mask和umask操作,但是原理是一样的,只不过NIC的handler执行完毕要发生EOI而已。
要解决上面的问题,最重要的是尽快的执行完中断handler,打开中断,unmask IRQ(或者发送EOI),方法就是把耗时的handle Data in the ram这个步骤踢出handler,让其在bottom half中执行。
2、为何有softirq和tasklet
OK,linux kernel已经把中断处理分成了top half和bottom half,看起来已经不错了,那为何还要提供softirq、tasklet和workqueue这些bottom half机制,linux kernel本来就够复杂了,bottom half还来添乱。实际上,在早期的linux kernel还真是只有一个bottom half机制,简称BH,简单好用,但是性能不佳。后来,linux kernel的开发者开发了task queue机制,试图来替代BH,当然,最后task queue也消失在内核代码中了。现在的linux kernel提供了三种bottom half的机制,来应对不同的需求。
workqueue和softirq、tasklet有本质的区别:workqueue运行在process context,而softirq和tasklet运行在interrupt context。因此,出现workqueue是不奇怪的,在有sleep需求的场景中,defering task必须延迟到kernel thread中执行,也就是说必须使用workqueue机制。softirq和tasklet是怎么回事呢?从本质上将,bottom half机制的设计有两方面的需求,一个是性能,一个是易用性。设计一个通用的bottom half机制来满足这两个需求非常的困难,因此,内核提供了softirq和tasklet两种机制。softirq更倾向于性能,而tasklet更倾向于易用性。
我们还是进入实际的例子吧,还是使用上一节的系统图。在引入softirq之后,网络数据的处理如下:
关中断:
1
| |
开中断:在softirq上下文中进行handle Data in the ram的动作
同样的,我们先假设Processor A处理了这个网卡中断事件,很快的完成了基本的HW操作后,raise softirq。在返回中断现场前,会检查softirq的触发情况,因此,后续网络数据处理的softirq在processor A上执行。在执行过程中,NIC硬件再次触发中断,Interrupt controller将该中断分发给processor B,执行动作和Processor A是类似的,因此,最后,网络数据处理的softirq在processor B上执行。
为了性能,同一类型的softirq有可能在不同的CPU上并发执行,这给使用者带来了极大的痛苦,因为驱动工程师在撰写softirq的回调函数的时候要考虑重入,考虑并发,要引入同步机制。但是,为了性能,我们必须如此。
当网络数据处理的softirq同时在Processor A和B上运行的时候,网卡中断又来了(可能是10G的网卡吧)。这时候,中断分发给processor A,这时候,processor A上的handler仍然会raise softirq,但是并不会调度该softirq。也就是说,softirq在一个CPU上是串行执行的。这种情况下,系统性能瓶颈是CPU资源,需要增加更多的CPU来解决该问题。
如果是tasklet的情况会如何呢?为何tasklet性能不如softirq呢?如果一个tasklet在processor A上被调度执行,那么它永远也不会同时在processor B上执行,也就是说,tasklet是串行执行的(注:不同的tasklet还是会并发的),不需要考虑重入的问题。我们还是用网卡这个例子吧(注意:这个例子仅仅是用来对比,实际上,网络数据是使用softirq机制的),同样是上面的系统结构图。假设使用tasklet,网络数据的处理如下:
关中断:
1
| |
开中断:在softirq上下文中(一般使用TASKLET_SOFTIRQ这个softirq)进行handle Data in the ram的动作
同样的,我们先假设Processor A处理了这个网卡中断事件,很快的完成了基本的HW操作后,schedule tasklet(同时也就raise TASKLET_SOFTIRQ softirq)。在返回中断现场前,会检查softirq的触发情况,因此,在TASKLET_SOFTIRQ softirq的handler中,获取tasklet相关信息并在processor A上执行该tasklet的handler。在执行过程中,NIC硬件再次触发中断,Interrupt controller将该中断分发给processor B,执行动作和Processor A是类似的,虽然TASKLET_SOFTIRQ softirq在processor B上可以执行,但是,在检查tasklet的状态的时候,如果发现该tasklet在其他processor上已经正在运行,那么该tasklet不会被处理,一直等到在processor A上的tasklet处理完,在processor B上的这个tasklet才能被执行。这样的串行化操作虽然对驱动工程师是一个福利,但是对性能而言是极大的损伤。
三、理解softirq需要的基础知识(各种context)
1、preempt_count
为了更好的理解下面的内容,我们需要先看看一些基础知识:一个task的thread info数据结构定义如下(只保留和本场景相关的内容):
1 2 3 4 5 | |
preempt_count这个成员被用来判断当前进程是否可以被抢占。如果preempt_count不等于0(可能是代码调用preempt_disable显式的禁止了抢占,也可能是处于中断上下文等),说明当前不能进行抢占,如果preempt_count等于0,说明已经具备了抢占的条件(当然具体是否要抢占当前进程还是要看看thread info中的flag成员是否设定了_TIF_NEED_RESCHED这个标记,可能是当前的进程的时间片用完了,也可能是由于中断唤醒了优先级更高的进程)。 具体preempt_count的数据格式可以参考下图:

preemption count用来记录当前被显式的禁止抢占的次数,也就是说,每调用一次preempt_disable,preemption count就会加一,调用preempt_enable,该区域的数值会减去一。preempt_disable和preempt_enable必须成对出现,可以嵌套,最大嵌套的深度是255。
hardirq count描述当前中断handler嵌套的深度。对于ARM平台的linux kernel,其中断部分的代码如下:
1 2 3 4 5 6 7 8 9 10 | |
通用的IRQ handler被irq_enter和irq_exit这两个函数包围。irq_enter说明进入到IRQ context,而irq_exit则说明退出IRQ context。在irq_enter函数中会调用preempt_count_add(HARDIRQ_OFFSET),为hardirq count的bit field增加1。在irq_exit函数中,会调用preempt_count_sub(HARDIRQ_OFFSET),为hardirq count的bit field减去1。hardirq count占用了4个bit,说明硬件中断handler最大可以嵌套15层。在旧的内核中,hardirq count占用了12个bit,支持4096个嵌套。当然,在旧的kernel中还区分fast interrupt handler和slow interrupt handler,中断handler最大可以嵌套的次数理论上等于系统IRQ的个数。在实际中,这个数目不可能那么大(内核栈就受不了),因此,即使系统支持了非常大的中断个数,也不可能各个中断依次嵌套,达到理论的上限。基于这样的考虑,后来内核减少了hardirq count占用bit数目,改成了10个bit(在general arch的代码中修改为10,实际上,各个arch可以redefine自己的hardirq count的bit数)。但是,当内核大佬们决定废弃slow interrupt handler的时候,实际上,中断的嵌套已经不会发生了。因此,理论上,hardirq count要么是0,要么是1。不过呢,不能总拿理论说事,实际上,万一有写奇葩或者老古董driver在handler中打开中断,那么这时候中断嵌套还是会发生的,但是,应该不会太多(一个系统中怎么可能有那么多奇葩呢?呵呵),因此,目前hardirq count占用了4个bit,应付15个奇葩driver是妥妥的。
对softirq count进行操作有两个场景:
(1)也是在进入soft irq handler之前给 softirq count加一,退出soft irq handler之后给 softirq count减去一。由于soft irq handler在一个CPU上是不会并发的,总是串行执行,因此,这个场景下只需要一个bit就够了,也就是上图中的bit 8。通过该bit可以知道当前task是否在sofirq context。
(2)由于内核同步的需求,进程上下文需要禁止softirq。这时候,kernel提供了local_bf_enable和local_bf_disable这样的接口函数。这部分的概念是和preempt disable/enable类似的,占用了bit9~15,最大可以支持127次嵌套。
2、一个task的各种上下文
看完了preempt_count之后,我们来介绍各种context:
1 2 3 4 5 | |
这里首先要介绍的是一个叫做IRQ context的术语。这里的IRQ context其实就是hard irq context,也就是说明当前正在执行中断handler(top half),只要preempt_count中的hardirq count大于0(=1是没有中断嵌套,如果大于1,说明有中断嵌套),那么就是IRQ context。
softirq context并没有那么的直接,一般人会认为当sofirq handler正在执行的时候就是softirq context。这样说当然没有错,sofirq handler正在执行的时候,会增加softirq count,当然是softirq context。不过,在其他context的情况下,例如进程上下文中,有有可能因为同步的要求而调用local_bh_disable,这时候,通过local_bh_disable/enable保护起来的代码也是执行在softirq context中。当然,这时候其实并没有正在执行softirq handler。如果你确实想知道当前是否正在执行softirq handler,in_serving_softirq可以完成这个使命,这是通过操作preempt_count的bit 8来完成的。
所谓中断上下文,就是IRQ context + softirq context+NMI context。
四、softirq机制
softirq和hardirq(就是硬件中断啦)是对应的,因此softirq的机制可以参考hardirq对应理解,当然softirq是纯软件的,不需要硬件参与。
1、softirq number
和IRQ number一样,对于软中断,linux kernel也是用一个softirq number唯一标识一个softirq,具体定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
HI_SOFTIRQ用于高优先级的tasklet,TASKLET_SOFTIRQ用于普通的tasklet。TIMER_SOFTIRQ是for software timer的(所谓software timer就是说该timer是基于系统tick的)。NET_TX_SOFTIRQ和NET_RX_SOFTIRQ是用于网卡数据收发的。BLOCK_SOFTIRQ和BLOCK_IOPOLL_SOFTIRQ是用于block device的。SCHED_SOFTIRQ用于多CPU之间的负载均衡的。HRTIMER_SOFTIRQ用于高精度timer的。RCU_SOFTIRQ是处理RCU的。这些具体使用情景分析会在各自的子系统中分析,本文只是描述softirq的工作原理。
2、softirq描述符
我们前面已经说了,softirq是静态定义的,也就是说系统中有一个定义softirq描述符的数组,而softirq number就是这个数组的index。这个概念和早期的静态分配的中断描述符概念是类似的。具体定义如下:
1 2 3 4 5 6 | |
系统支持多少个软中断,静态定义的数组就会有多少个entry。____cacheline_aligned保证了在SMP的情况下,softirq_vec是对齐到cache line的。softirq描述符非常简单,只有一个action成员,表示如果触发了该softirq,那么应该调用action回调函数来处理这个soft irq。对于硬件中断而言,其mask、ack等都是和硬件寄存器相关并封装在irq chip函数中,对于softirq,没有硬件寄存器,只有“软件寄存器”,定义如下:
1 2 3 4 5 6 7 8 | |
ipi_irqs这个成员用于处理器之间的中断,我们留到下一个专题来描述。__softirq_pending就是这个“软件寄存器”。softirq采用谁触发,谁负责处理的。例如:当一个驱动的硬件中断被分发给了指定的CPU,并且在该中断handler中触发了一个softirq,那么该CPU负责调用该softirq number对应的action callback来处理该软中断。因此,这个“软件寄存器”应该是每个CPU拥有一个(专业术语叫做banked register)。为了性能,irq_stat中的每一个entry被定义对齐到cache line。
3、如何注册一个softirq
通过调用open_softirq接口函数可以注册softirq的action callback函数,具体如下:
1 2 3 4 | |
softirq_vec是一个多CPU之间共享的数据,不过,由于所有的注册都是在系统初始化的时候完成的,那时候,系统是串行执行的。此外,softirq是静态定义的,每个entry(或者说每个softirq number)都是固定分配的,因此,不需要保护。
4、如何触发softirq?
在linux kernel中,可以调用raise_softirq这个接口函数来触发本地CPU上的softirq,具体如下:
1 2 3 4 5 6 7 8 | |
虽然大部分的使用场景都是在中断handler中(也就是说关闭本地CPU中断)来执行softirq的触发动作,但是,这不是全部,在其他的上下文中也可以调用raise_softirq。因此,触发softirq的接口函数有两个版本,一个是raise_softirq,有关中断的保护,另外一个是raise_softirq_irqoff,调用者已经关闭了中断,不需要关中断来保护“soft irq status register”。
所谓trigger softirq,就是在__softirq_pending(也就是上面说的soft irq status register)的某个bit置一。从上面的定义可知,__softirq_pending是per cpu的,因此不需要考虑多个CPU的并发,只要disable本地中断,就可以确保对,__softirq_pending操作的原子性。
具体raise_softirq_irqoff的代码如下:
1 2 3 4 5 6 7 | |
(1)__raise_softirq_irqoff函数设定本CPU上的__softirq_pending的某个bit等于1,具体的bit是由soft irq number(nr参数)指定的。
(2)如果在中断上下文,我们只要set __softirq_pending的某个bit就OK了,在中断返回的时候自然会进行软中断的处理。但是,如果在context上下文调用这个函数的时候,我们必须要调用wakeup_softirqd函数用来唤醒本CPU上的softirqd这个内核线程。具体softirqd的内容请参考下一个章节。
5、disable/enable softirq
在linux kernel中,可以使用local_irq_disable和local_irq_enable来disable和enable本CPU中断。和硬件中断一样,软中断也可以disable,接口函数是local_bh_disable和local_bh_enable。虽然和想像的local_softirq_enable/disable有些出入,不过bh这个名字更准确反应了该接口函数的意涵,因为local_bh_disable/enable函数就是用来disable/enable bottom half的,这里就包括softirq和tasklet。
先看disable吧,毕竟禁止bottom half比较简单:
1 2 3 4 5 6 7 8 9 10 | |
看起来disable bottom half比较简单,就是讲current thread info上的preempt_count成员中的softirq count的bit field9~15加上一就OK了。barrier是优化屏障(Optimization barrier),会在内核同步系列文章中描述。
enable函数比较复杂,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
(1)disable/enable bottom half是一种内核同步机制。在硬件中断的handler(top half)中,不应该调用disable/enable bottom half函数来保护共享数据,因为bottom half其实是不可能抢占top half的。同样的,soft irq也不会抢占另外一个soft irq的执行,也就是说,一旦一个softirq handler被调度执行(无论在哪一个processor上),那么,本地的softirq handler都无法抢占其运行,要等到当前的softirq handler运行完毕后,才能执行下一个soft irq handler。注意:上面我们说的是本地,是local,softirq handler是可以在多个CPU上同时运行的,但是,linux kernel中没有disable all softirq的接口函数(就好像没有disable all CPU interrupt的接口一样,注意体会local_bh_enable/disable中的local的含义)。
说了这么多,一言以蔽之,local_bh_enable/disable是给进程上下文使用的,用于防止softirq handler抢占local_bh_enable/disable之间的临界区的。
irqs_disabled接口函数可以获知当前本地CPU中断是否是disable的,如果返回1,那么当前是disable 本地CPU的中断的。如果irqs_disabled返回1,有可能是下面这样的代码造成的:
1 2 3 4 5 6 7 8 9 | |
本质上,关本地中断是一种比关本地bottom half更强劲的锁,关本地中断实际上是禁止了top half和bottom half抢占当前进程上下文的运行。也许你会说:这也没有什么,就是有些浪费,至少代码逻辑没有问题。但事情没有这么简单,在local_bh_enable--->do_softirq--->__do_softirq中,有一条无条件打开当前中断的操作,也就是说,原本想通过local_irq_disable/local_irq_enable保护的临界区被破坏了,其他的中断handler可以插入执行,从而无法保证local_irq_disable/local_irq_enable保护的临界区的原子性,从而破坏了代码逻辑。
in_irq()这个函数如果不等于0的话,说明local_bh_enable被irq_enter和irq_exit包围,也就是说在中断handler中调用了local_bh_enable/disable。这道理是和上面类似的,这里就不再详细描述了。
(2)在local_bh_disable中我们为preempt_count增加了SOFTIRQ_DISABLE_OFFSET,在local_bh_enable函数中应该减掉同样的数值。这一步,我们首先减去了(SOFTIRQ_DISABLE_OFFSET-1),为何不一次性的减去SOFTIRQ_DISABLE_OFFSET呢?考虑下面运行在进程上下文的代码场景:
1 2 3 4 5 6 7 8 | |
在临界区内,有进程context 和softirq共享的数据,因此,在进程上下文中使用local_bh_enable/disable进行保护。假设在临界区代码执行的时候,发生了中断,由于代码并没有阻止top half的抢占,因此中断handler会抢占当前正在执行的thread。在中断handler中,我们raise了softirq,在返回中断现场的时候,由于disable了bottom half,因此虽然触发了softirq,但是不会调度执行。因此,代码返回临界区继续执行,直到local_bh_enable。一旦enable了bottom half,那么之前raise的softirq就需要调度执行了,因此,这也是为什么在local_bh_enable会调用do_softirq函数。
调用do_softirq函数来处理pending的softirq的时候,当前的task是不能被抢占的,因为一旦被抢占,下一次该task被调度运行的时候很可能在其他的CPU上去了(还记得吗?softirq的pending 寄存器是per cpu的)。因此,我们不能一次性的全部减掉,那样的话有可能preempt_count等于0,那样就允许抢占了。因此,这里减去了(SOFTIRQ_DISABLE_OFFSET-1),既保证了softirq count的bit field9~15被减去了1,又保持了preempt disable的状态。
(3)如果当前不是interrupt context的话,并且有pending的softirq,那么调用do_softirq函数来处理软中断。
(4)该来的总会来,在step 2中我们少减了1,这里补上,其实也就是preempt count-1。
(5)在softirq handler中很可能wakeup了高优先级的任务,这里最好要检查一下,看看是否需要进行调度,确保高优先级的任务得以调度执行。
5、如何处理一个被触发的soft irq
我们说softirq是一种defering task的机制,也就是说top half没有做的事情,需要延迟到bottom half中来执行。那么具体延迟到什么时候呢?这是本节需要讲述的内容,也就是说soft irq是如何调度执行的。
在上一节已经描述一个softirq被调度执行的场景,本节主要关注在中断返回现场时候调度softirq的场景。我们来看中断退出的代码,具体如下:
1 2 3 4 5 6 7 8 | |
代码中“!in_interrupt()”这个条件可以确保下面的场景不会触发sotfirq的调度:
(1)中断handler是嵌套的。也就是说本次irq_exit是退出到上一个中断handler。当然,在新的内核中,这种情况一般不会发生,因为中断handler都是关中断执行的。
(2)本次中断是中断了softirq handler的执行。也就是说本次irq_exit是不是退出到进程上下文,而是退出到上一个softirq context。这一点也保证了在一个CPU上的softirq是串行执行的(注意:多个CPU上还是有可能并发的)
我们继续看invoke_softirq的代码:
1 2 3 4 5 6 7 8 9 10 11 12 | |
force_irqthreads是和强制线程化相关的,主要用于interrupt handler的调试(一般而言,在线程环境下比在中断上下文中更容易收集调试数据)。如果系统选择了对所有的interrupt handler进行线程化处理,那么softirq也没有理由在中断上下文中处理(中断handler都在线程中执行了,softirq怎么可能在中断上下文中执行)。本身invoke_softirq这个函数是在中断上下文中被调用的,如果强制线程化,那么系统中所有的软中断都在sofirq的daemon进程中被调度执行。
如果没有强制线程化,softirq的处理也分成两种情况,主要是和softirq执行的时候使用的stack相关。如果arch支持单独的IRQ STACK,这时候,由于要退出中断,因此irq stack已经接近全空了(不考虑中断栈嵌套的情况,因此新内核下,中断不会嵌套),因此直接调用__do_softirq()处理软中断就OK了,否则就调用do_softirq_own_stack函数在softirq自己的stack上执行。当然对ARM而言,softirq的处理就是在当前的内核栈上执行的,因此do_softirq_own_stack的调用就是调用__do_softirq(),代码如下(删除了部分无关代码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
(注1)再次检查softirq pending,有可能上面的softirq handler在执行过程中,发生了中断,又raise了softirq。如果的确如此,那么我们需要跳转到restart那里重新处理soft irq。当然,也不能总是在这里不断的loop,因此linux kernel设定了下面的条件:
(1)softirq的处理时间没有超过2个ms
(2)上次的softirq中没有设定TIF_NEED_RESCHED,也就是说没有有高优先级任务需要调度
(3)loop的次数小于 10次
因此,只有同时满足上面三个条件,程序才会跳转到restart那里重新处理soft irq。否则wakeup_softirqd就OK了。这样的设计也是一个平衡的方案。一方面照顾了调度延迟:本来,发生一个中断,系统期望在限定的时间内调度某个进程来处理这个中断,如果softirq handler不断触发,其实linux kernel是无法保证调度延迟时间的。另外一方面,也照顾了硬件的thoughput:已经预留了一定的时间来处理softirq。