/* to find an entry in a page-table-directory */
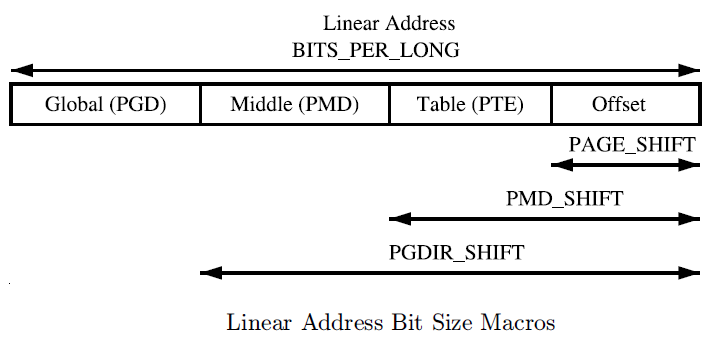
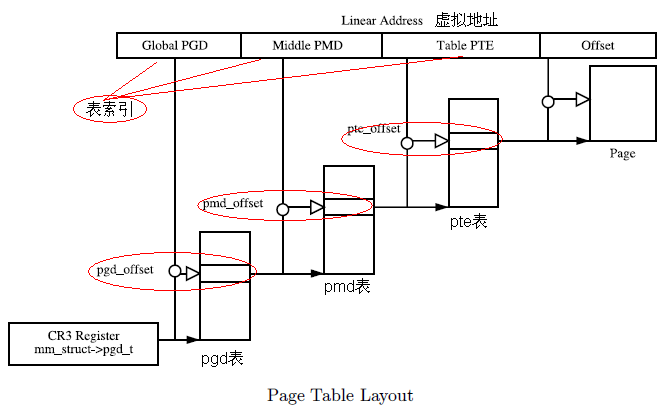
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT) //获得在pgd表中的索引
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr)) //获得pmd表的起始地址
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
• pmd_offset
根据通过pgd_offset获取的pgd 项和虚拟地址,获取相关的pmd项(即pte表的起始地址)
12
/* Find an entry in the second-level page table.. */
#define pmd_offset(dir, addr) ((pmd_t *)(dir)) //即为pgd项的值
/**
* follow_page - look up a page descriptor from a user-virtual address
* @vma: vm_area_struct mapping @address
* @address: virtual address to look up
* @flags: flags modifying lookup behaviour
*
* @flags can have FOLL_ flags set, defined in <linux/mm.h>
*
* Returns the mapped (struct page *), %NULL if no mapping exists, or
* an error pointer if there is a mapping to something not represented
* by a page descriptor (see also vm_normal_page()).
*/
struct page *follow_page(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *ptep, pte;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
goto out;
}
page = NULL;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
goto no_page_table;
pud = pud_offset(pgd, address);
if (pud_none(*pud))
goto no_page_table;
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pud(mm, address, pud, flags & FOLL_WRITE);
goto out;
}
if (unlikely(pud_bad(*pud)))
goto no_page_table;
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
goto no_page_table;
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pmd(mm, address, pmd, flags & FOLL_WRITE);
goto out;
}
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(mm, pmd);
goto split_fallthrough;
}
spin_lock(&mm->page_table_lock);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(&mm->page_table_lock);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(mm, address,
pmd, flags);
spin_unlock(&mm->page_table_lock);
goto out;
}
} else
spin_unlock(&mm->page_table_lock);
/* fall through */
}
split_fallthrough:
if (unlikely(pmd_bad(*pmd)))
goto no_page_table;
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte))
goto unlock;
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if ((flags & FOLL_DUMP) ||
!is_zero_pfn(pte_pfn(pte)))
goto bad_page;
page = pte_page(pte);
}
if (flags & FOLL_GET)
get_page(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here and migration is
* blocked by the pte's page reference, we need
* only check for file-cache page truncation.
*/
if (page->mapping)
mlock_vma_page(page);
unlock_page(page);
}
}
unlock:
pte_unmap_unlock(ptep, ptl);
out:
return page;
bad_page:
pte_unmap_unlock(ptep, ptl);
return ERR_PTR(-EFAULT);
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return page;
no_page_table:
/*
* When core dumping an enormous anonymous area that nobody
* has touched so far, we don't want to allocate unnecessary pages or
* page tables. Return error instead of NULL to skip handle_mm_fault,
* then get_dump_page() will return NULL to leave a hole in the dump.
* But we can only make this optimization where a hole would surely
* be zero-filled if handle_mm_fault() actually did handle it.
*/
if ((flags & FOLL_DUMP) &&
(!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return page;
}
1. First Fit分配器
First Fit分配器是最基本的内存分配器,它使用bitmap而不是空闲块列表来表示内存。在bitmap中,如果page对应位为1,则表示此page已经被分配,为0则表示此page没有被分配。为了分配小于一个page的内存块,First Fit分配器记录了最后被分配的PFN (Page Frame Number)和分配的结束地址在页内的偏移量。随后小的内存分配被Merge到一起并存储到同一页中。
First Fit分配器不会造成严重的内存碎片,但其效率较低,由于内存经常通过线性地址进行search,而First Fit中的小块内存经常在物理内存的开始处,为了分配大块内存而不得不扫描前面大量的内存。