

http://blog.csdn.net/freas_1990/article/details/9090601
swap是现代Unix操作系统一个非常重要的特性。尤其在大型数据库服务器上,swap往往是性能首要查看指标。
通俗的说法,在Unix里,将开辟一个磁盘分区,用作swap,这块磁盘将作为内存的的替代品,在内存不够用的时候,把一部分内存空间交换到磁盘上去。
而Unix的swap功能也成为了Unixer们认为Unix由于windows的一个论据(?)。在Unix里,swap一般被认为设置为内存的2倍大小。这个2倍大小的指标出自哪里,到目前为止我也没有找到(?如果你找到了可以留言或发私信)。
不过,在内存不断掉价的今天,swap的功效已经越来越弱化了——在2013年6月13日23:01,如果一个OLTP系统的swap使用超过了2G以上,基本上可以对这个系统的性能产生怀疑了。swap并不是一种优化机制,而是一种不得已而为之的手段,防止在内存紧张的时刻,操作系统性能骤降以至瞬间崩溃。swap的价值主要体现在可以把这个崩溃的时间提升至几小时到几十个小时不等。
本文主要关注CPU访问一个内存page时,发现该page不在内存中的情况。废话不多说了,先把swap的核心函数调用栈贴一下。
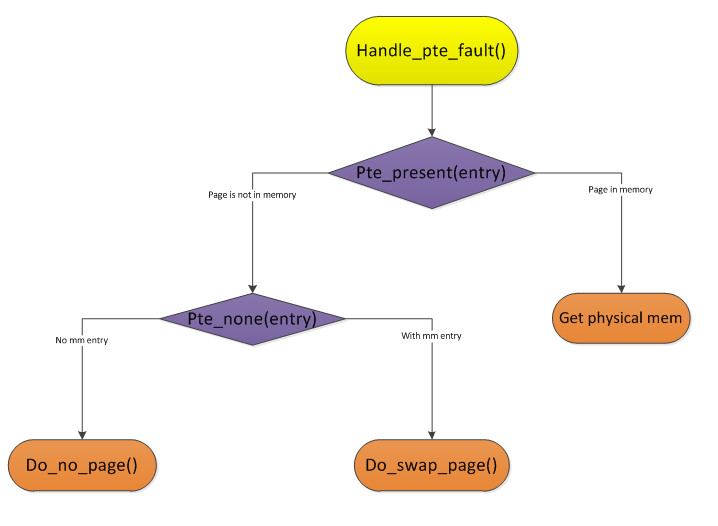
当CPU检查一个页目录项/页表项的Present标志位时,如果发现该标志位为0,则表示相应的物理页面不在内存。此时,CPU会被激发“页面异常”(中断中的fault),而去执行一段代码。
至于到底是这个内存页面需要重新构建、还是页面的内容是存储到磁盘上去了,CPU本身是不关心的,CPU只知道中断条件发生了,要根据中断描述符跳转到另外一段代码去执行,而真正的swap或者是真的缺页的智能判断是在这段中断服务程序里做的——真正的技术是在这段中断服务程序里。(所以我在《中断——一鞭一条痕(下)》里说,作为一个初学者,不必深究中断(interrupt)、异常(exception)、陷阱(trap)这三个概念)
pte_present()函数会检查当前页面的描述entry的present标志位,查看该page是否在内存中。如果不在内存中,调用pte_none()判断是否建立了页目录、页表映射。如果连映射都没建立,说明是“真没在内存中”,需要从头建立映射关系。如果建立了映射关系,说明此时,该页面被暂时存储到磁盘上去了,应该到磁盘上去把该page取回来放到内存里。
如何去取呢?
如何到磁盘取一个page的数据到内存中去,这是一个多么熟悉的概念!思考一下Oracle的内存管理,一个block如何读入到SGA的buffer cache里去吧。其实这几十年来,核心的本源技术无论是在操作系统内核还是在数据库内核里,都是通用的,都是用来极大限度提升CPU任务管理能力、内存管理效率的,所有的理念、技术都是通用的——如果你站在一个系统程序猿的角度来思考,一定能明白的——不要把自己局限在一个产品里,无论这个产品是数据库、CPU、还是操作系统,这些看似绚烂神秘的技术在30年以前,已经被人反复的讨论和意淫过了。
接下来就到了核心部分了——do_swap_page()函数。
源代码如下(linux/mm/memory.c line 2022~1060):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
这里有2个参数需要重点关注,一个是(pte_t *)page_table,另外一个是(swp_entry_t*)entry。
当一个page在内存中,不需要swap in时,描述该page的entry是pte_t类型的;反之,是swp_entry_t类型。
swap_entry_t(include/linux/shmem_fs.h)定义如下:
1 2 3 | |
问题出来了,既然都进入do_swap_page()函数了,说明是需要swap in了,为什么还会传入一个pte_t类型的变量呢?
答案是,当在do_swap_page()之前,page是在磁盘上的,描述类型是swp_entry_t,而do_swap_page()之后,页面已经从磁盘交换到内存了,这个时候描述类型就是pte_t了。
至于lookup_swap_cache、swapin_readahead(预读——read ahead)等函数就不一一分析了,从名字就可以看出其技巧了。都是些在数据库server上的常用技巧。如果你是行家,一眼就能看出来。