http://simohayha.iteye.com/blog/566980
这次来详细看内核的time_wait状态的实现,在前面介绍定时器的时候,time_wait就简单的介绍了下。这里我们会先介绍tw状态的实现,然后来介绍内核协议栈如何处理tw状态。
首先我们要知道在linux内核中time_wait的处理是由tcp_time_wait这个函数来做得,比如我们在closing状态收到一个fin,就会调用tcp_time_wait.而内核为time_wait状态的socket专门设计了一个结构就是inet_timewait_sock,并且是挂载在inet_ehash_bucket的tw上(这个结构前面也已经介绍过了)。这里要注意,端口号的那个hash链表中也是会保存time_wait状态的socket的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
struct inet_timewait_sock {
//common也就是包含了一些socket的必要信息。
struct sock_common __tw_common;
#define tw_family __tw_common.skc_family
#define tw_state __tw_common.skc_state
#define tw_reuse __tw_common.skc_reuse
#define tw_bound_dev_if __tw_common.skc_bound_dev_if
#define tw_node __tw_common.skc_nulls_node
#define tw_bind_node __tw_common.skc_bind_node
#define tw_refcnt __tw_common.skc_refcnt
#define tw_hash __tw_common.skc_hash
#define tw_prot __tw_common.skc_prot
#define tw_net __tw_common.skc_net
//tw状态的超时时间
int tw_timeout;
//这个用来标记我们是正常进入tw还是说由于超时等一系列原因进入(比如超时等一系列原因)
volatile unsigned char tw_substate;
/* 3 bits hole, try to pack */
//和tcp option中的接收窗口比例类似
unsigned char tw_rcv_wscale;
//也就是标示sock的4个域,源目的端口和地址
__be16 tw_sport;
__be32 tw_daddr __attribute__((aligned(INET_TIMEWAIT_ADDRCMP_ALIGN_BYTES)));
__be32 tw_rcv_saddr;
__be16 tw_dport;
//本地端口。
__u16 tw_num;
kmemcheck_bitfield_begin(flags);
/* And these are ours. */
//几个标记位。
unsigned int tw_ipv6only : 1,
tw_transparent : 1,
tw_pad : 14, /* 14 bits hole */
tw_ipv6_offset : 16;
kmemcheck_bitfield_end(flags);
unsigned long tw_ttd;
//链接到端口的hash表中。
struct inet_bind_bucket *tw_tb;
//链接到全局的tw状态hash表中。
struct hlist_node tw_death_node;
};
然后我们要知道linux有两种方式执行tw状态的socket,一种是等待2×MSL时间(内核中是60秒),一种是基于RTO来计算超时时间。
基于RTO的超时时间也叫做recycle模式,这里内核会通过sysctl_tw_recycle(也就是说我们能通过sysctl来打开这个值)以及是否我们还保存有从对端接收到的最近的数据包的时间戳来判断是否进入打开recycle模式的处理。如果进入则会调用tcp_v4_remember_stamp来得到是否打开recycle模式。
下面就是这个片断的代码片断:
1
2
3
4
//必须要设置sysctl_tw_recycle以及保存有最后一次的时间戳.
if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp)
//然后调用remember_stamp(在ipv4中被初始化为tcp_v4_remember_stamp)来得到是否要打开recycle模式。
recycle_ok = icsk->icsk_af_ops->remember_stamp(sk);
然后我们来看tcp_v4_remember_stamp,在看这个之前,我们需要理解inet_peer结构,这个结构也就是保存了何当前主机通信的主机的一些信息,我前面在分析ip层的时候有详细分析这个结构,因此可以看我前面的blog:
http://simohayha.iteye.com/blog/437695
tcp_v4_remember_stamp主要用来从全局的inet_peer中得到对应的当前sock的对端的信息(通过ip地址).然后设置相关的时间戳(tcp_ts_stamp和tcp_ts).这里要特别注意一个东西,那就是inet_peer是ip层的东西,因此它的key是ip地址,它会忽略端口号。所以说这里inet_peer的这两个时间戳是专门为解决tw状态而设置的。
然后我们来看下tcp option的几个关键的域:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct tcp_options_received {
/* PAWS/RTTM data */
//这个值为我们本机更新ts_recent的时间
long ts_recent_stamp;
//这个表示最近接收的那个数据包的时间戳
u32 ts_recent;
//这个表示这个数据包发送时的时间戳
u32 rcv_tsval;
//这个表示当前数据包所回应的数据包的时间戳。
u32 rcv_tsecr;
//如果上面两个时间戳都有设置,则saw_tstamp设置为1.
u16 saw_tstamp : 1, //TIMESTAMP seen on SYN packet
tstamp_ok : 1, //d-scack标记
dsack : 1, //Wscale seen on SYN packet
wscale_ok : 1, //SACK seen on SYN packet
sack_ok : 4, //下面两个是窗口扩大倍数,主要是为了解决一些特殊网络下大窗口的问题。
snd_wscale : 4,
rcv_wscale : 4;
/* SACKs data */
u8 num_sacks;
u16 user_mss;
u16 mss_clamp;
};
而inet_peer中的两个时间戳与option中的ts_recent和ts_recent_stamp类似。
来看tcp_v4_remember_stamp的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
int tcp_v4_remember_stamp(struct sock *sk)
{
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct rtable *rt = (struct rtable *)__sk_dst_get(sk);
struct inet_peer *peer = NULL;
int release_it = 0;
//得到对应peer(两种得到的方式)。
if (!rt || rt->rt_dst != inet->daddr) {
peer = inet_getpeer(inet->daddr, 1);
release_it = 1;
} else {
if (!rt->peer)
rt_bind_peer(rt, 1);
peer = rt->peer;
}
//如果peer不存在则会返回0,也就是关闭recycle模式。
if (peer) {
//这里tcp_ts以及tcp_ts_stamp保存的是最新的时间戳,所以这里与当前的sock的时间戳比较小的话就要更新。
if ((s32)(peer->tcp_ts - tp->rx_opt.ts_recent) <= 0 ||(peer->tcp_ts_stamp + TCP_PAWS_MSL < get_seconds() &&
peer->tcp_ts_stamp <= tp->rx_opt.ts_recent_stamp)) {
//更新时间戳。
peer->tcp_ts_stamp = tp->rx_opt.ts_recent_stamp;
peer->tcp_ts = tp->rx_opt.ts_recent;
}
if (release_it)
inet_putpeer(peer);
return 1;
}
//关闭recycle模式。
return 0;
}
ok,我们来看tcp_time_wait的实现,这里删掉了ipv6以及md5的部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
//这里也就是2*MSL=60秒。
#define TCP_TIMEWAIT_LEN (60*HZ)
//这里的state标记我们是正常进入tw状态,还是由于死在fin-wait-2状态才进入tw状态的。
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
//TW的socket
struct inet_timewait_sock *tw = NULL;
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
//recycle模式的标记。
int recycle_ok = 0;
//上面已经分析过了。
if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp)
recycle_ok = icsk->icsk_af_ops->remember_stamp(sk);
//然后判断tw状态的sock数量是否已经超过限制。
if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets)
//没有的话alloc一个新的。
tw = inet_twsk_alloc(sk, state);
//如果tw不为空才会进入处理。
if (tw != NULL) {
struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw);
//计算对应的超时时间,这里可以看到刚好是3.5*rto.
const int rto = (icsk->icsk_rto << 2) - (icsk->icsk_rto >> 1);
//更新对应的域。
tw->tw_rcv_wscale = tp->rx_opt.rcv_wscale;
tcptw->tw_rcv_nxt = tp->rcv_nxt;
tcptw->tw_snd_nxt = tp->snd_nxt;
tcptw->tw_rcv_wnd = tcp_receive_window(tp);
tcptw->tw_ts_recent = tp->rx_opt.ts_recent;
tcptw->tw_ts_recent_stamp = tp->rx_opt.ts_recent_stamp;
//更新链表(下面会分析)。
__inet_twsk_hashdance(tw, sk, &tcp_hashinfo);
//如果传递进来的超时时间小于我们计算的,则让他等于我们计算的超时时间。
/* Get the TIME_WAIT timeout firing. */
if (timeo < rto)
timeo = rto;
//如果打开recycle模式,则超时时间为我们基于rto计算的时间。
if (recycle_ok) {
tw->tw_timeout = rto;
} else {
//否则为2*MSL=60秒
tw->tw_timeout = TCP_TIMEWAIT_LEN;
//如果正常进入则timeo也就是超时时间为2*MSL.
if (state == TCP_TIME_WAIT)
timeo = TCP_TIMEWAIT_LEN;
}
//最关键的一个函数,我们后面会详细分析。
inet_twsk_schedule(tw, &tcp_death_row, timeo,
TCP_TIMEWAIT_LEN);
//更新引用计数。
inet_twsk_put(tw);
} else {
LIMIT_NETDEBUG(KERN_INFO "TCP: time wait bucket table overflow\n");
}
tcp_update_metrics(sk);
tcp_done(sk);
}
然后我们来看__inet_twsk_hashdance函数,这个函数主要是用于更新对应的全局hash表。有关这几个hash表的结构可以去看我前面的blog。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
void __inet_twsk_hashdance(struct inet_timewait_sock *tw, struct sock *sk,
struct inet_hashinfo *hashinfo)
{
const struct inet_sock *inet = inet_sk(sk);
const struct inet_connection_sock *icsk = inet_csk(sk);
//得到ehash。
struct inet_ehash_bucket *ehead = inet_ehash_bucket(hashinfo, sk->sk_hash);
spinlock_t *lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
struct inet_bind_hashbucket *bhead;
//下面这几步是将tw sock链接到bhash中。
bhead = &hashinfo->bhash[inet_bhashfn(twsk_net(tw), inet->num,hashinfo->bhash_size)];
spin_lock(&bhead->lock);
//链接到bhash。这里icsk的icsk_bind_hash也就是bash的一个元素。
tw->tw_tb = icsk->icsk_bind_hash;
WARN_ON(!icsk->icsk_bind_hash);
//将tw加入到bash中。
inet_twsk_add_bind_node(tw, &tw->tw_tb->owners);
spin_unlock(&bhead->lock);
spin_lock(lock);
atomic_inc(&tw->tw_refcnt);
//将tw sock加入到ehash的tw chain中。
inet_twsk_add_node_rcu(tw, &ehead->twchain);
//然后从全局的establish hash中remove掉这个socket。详见sock的sk_common域。
if (__sk_nulls_del_node_init_rcu(sk))
sock_prot_inuse_add(sock_net(sk), sk->sk_prot, -1);
spin_unlock(lock);
}
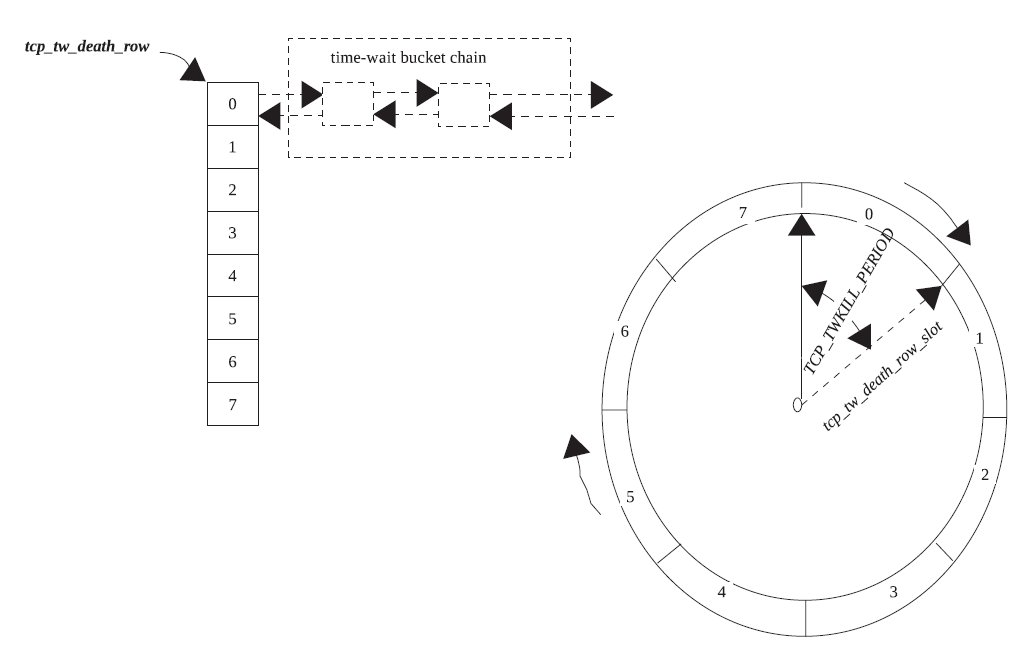
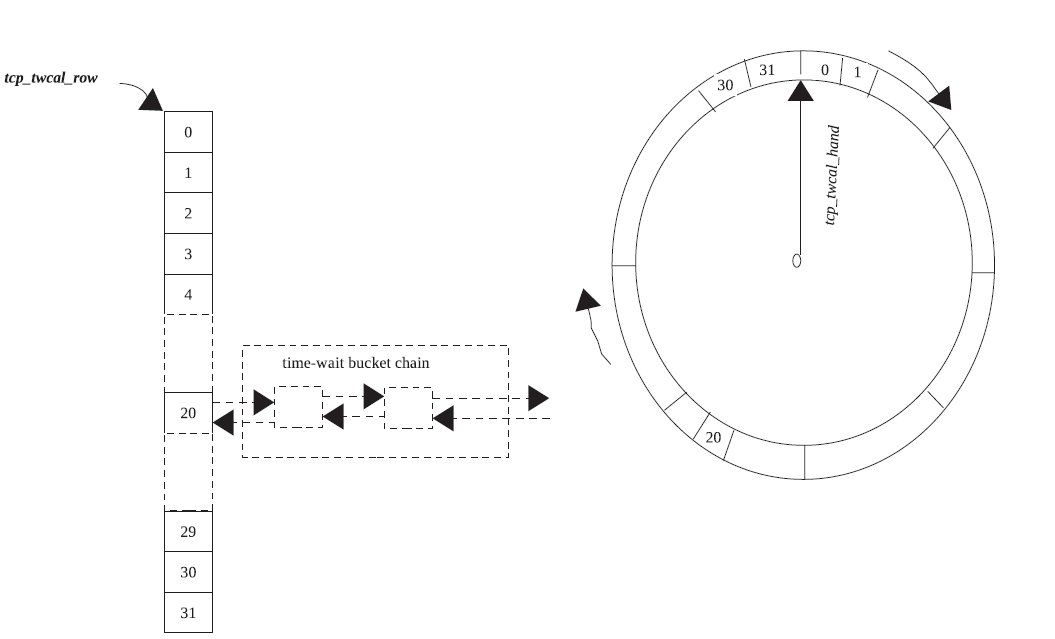
这里我们要知道还有一个专门的全局的struct inet_timewait_death_row类型的变量tcp_death_row来保存所有的tw状态的socket。而整个tw状态的socket并不是全部加入到定时器中,而是将tcp_death_row加入到定时器中,然后每次定时器超时通过tcp_death_row来查看定时器的超时情况,从而处理tw状态的sock。
而这里定时器分为两种,一种是长时间的定时器,它也就是tw_timer域,一种是短时间的定时器,它也就是twcal_timer域。
而这里还有两个hash表,一个是twcal_row,它对应twcal_timer这个定时器,也就是说当twcal_timer超时,它就会从twcal_row中取得对应的twsock。对应的cells保存的就是tw_timer定时器超时所用的twsock。
还有两个slot,一个是slot域,一个是twcal_hand域,分别表示当前对应的定时器(上面介绍的两个)所正在执行的定时器的slot。
而上面所说的recycle模式也就是指twcal_timer定时器。
来看结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
struct inet_timewait_death_row {
//这几个域会在tcp_death_row中被初始化。
int twcal_hand;
unsigned long twcal_jiffie;
//短时间定时器。
struct timer_list twcal_timer;
//twcal_timer定时器对应的hash表
struct hlist_head twcal_row[INET_TWDR_RECYCLE_SLOTS];
spinlock_t death_lock;
//tw的个数。
int tw_count;
//超时时间。
int period;
u32 thread_slots;
struct work_struct twkill_work;
//长时间定时器
struct timer_list tw_timer;
int slot;
//短时间的定时器对应的hash表
struct hlist_head cells[INET_TWDR_TWKILL_SLOTS];
struct inet_hashinfo *hashinfo;
int sysctl_tw_recycle;
int sysctl_max_tw_buckets;
};
这里要注意INET_TWDR_TWKILL_SLOTS为8,而INET_TWDR_RECYCLE_SLOTS为32。
ok我们接着来看tcp_death_row的初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct inet_timewait_death_row tcp_death_row = {
//最大桶的个数。
.sysctl_max_tw_buckets = NR_FILE * 2,
//超时时间,
.period = TCP_TIMEWAIT_LEN / INET_TWDR_TWKILL_SLOTS,
//锁
.death_lock = __SPIN_LOCK_UNLOCKED(tcp_death_row.death_lock),
//可以看到它是链接到全局的inet_hashinfo中的。
.hashinfo = &tcp_hashinfo,
//定时器,这里要注意超时函数。
.tw_timer = TIMER_INITIALIZER(inet_twdr_hangman, 0,(unsigned long)&tcp_death_row),
//工作队列。其实也就是销毁twsock工作的工作队列。
.twkill_work = __WORK_INITIALIZER(tcp_death_row.twkill_work, inet_twdr_twkill_work),
/* Short-time timewait calendar */
//twcal_hand用来标记twcal_timer定时器是否还在工作。
.twcal_hand = -1,
.twcal_timer = TIMER_INITIALIZER(inet_twdr_twcal_tick, 0,(unsigned long)&tcp_death_row),
};
然后就是inet_twsk_schedule的实现,这个函数也就是tw状态的处理函数。他主要是用来基于超时时间来计算当前twsock的可用的位置。也就是来判断启动那个定时器,然后加入到那个队列。
因此这里的关键就是slot的计算。这里slot的计算是根据我们传递进来的timeo来计算的。
recycle模式下tcp_death_row的超时时间的就为2的INET_TWDR_RECYCLE_TICK幂。
我们一般桌面的hz为100,来看对应的值:
1
2
#elif HZ <= 128
# define INET_TWDR_RECYCLE_TICK (7 + 2 - INET_TWDR_RECYCLE_SLOTS_LOG)
可以看到这时它的值就为4.
而tw_timer的slot也就是长时间定时器的slot的计算是这样的,它也就是用我们传递进来的超时时间timeo/16(可以看到就是2的INET_TWDR_RECYCLE_TICK次方)然后向上取整。
而这里twdr的period被设置为
1
2
3
4
TCP_TIMEWAIT_LEN / INET_TWDR_TWKILL_SLOTS,
//取slot的代码片断。
slot = DIV_ROUND_UP(timeo, twdr->period);
而我们下面取slot的时候也就是会用这个值来散列。可以看到散列表的桶的数目就为INET_TWDR_TWKILL_SLOTS个,因此这里也就是把时间分为INET_TWDR_TWKILL_SLOTS份,每一段时间内的超时twsock都放在一个桶里面,而大于60秒的都放在最后一个桶。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
void inet_twsk_schedule(struct inet_timewait_sock *tw,
struct inet_timewait_death_row *twdr,
const int timeo, const int timewait_len)
{
struct hlist_head *list;
int slot;
//得到slot。
slot = (timeo + (1 << INET_TWDR_RECYCLE_TICK) - 1) >> INET_TWDR_RECYCLE_TICK;
spin_lock(&twdr->death_lock);
/* Unlink it, if it was scheduled */
if (inet_twsk_del_dead_node(tw))
twdr->tw_count--;
else
atomic_inc(&tw->tw_refcnt);
//判断该添加到那个定时器。
if (slot >= INET_TWDR_RECYCLE_SLOTS) {
/* Schedule to slow timer */
//如果大于timewait_len也就是2*MSL=60秒,则slot为cells的最后一项。
if (timeo >= timewait_len) {
//设为最后一项。
slot = INET_TWDR_TWKILL_SLOTS - 1;
} else {
//否则timeo除于period然后向上取整。
slot = DIV_ROUND_UP(timeo, twdr->period);
//如果大于cells的桶的大小,则也是放到最后一个位置。
if (slot >= INET_TWDR_TWKILL_SLOTS)
slot = INET_TWDR_TWKILL_SLOTS - 1;
}
//然后设置超时时间,
tw->tw_ttd = jiffies + timeo;
//而twdr的slot为当前正在处理的slot,因此我们需要以这个slot为基准来计算真正的slot
slot = (twdr->slot + slot) & (INET_TWDR_TWKILL_SLOTS - 1);
//最后取得对应的链表。
list = &twdr->cells[slot];
} else {
//设置应当超时的时间。
tw->tw_ttd = jiffies + (slot << INET_TWDR_RECYCLE_TICK);
//判断定时器是否还在工作。如果是第一次我们一定会进入下面的处理
if (twdr->twcal_hand < 0) {
//如果没有或者第一次进入,则修改定时器然后重新启动定时器
twdr->twcal_hand = 0;
twdr->twcal_jiffie = jiffies;
//定时器的超时时间。可以看到时间为我们传进来的timeo(只不过象tick对齐了)
twdr->twcal_timer.expires = twdr->twcal_jiffie +(slot << INET_TWDR_RECYCLE_TICK);
//重新添加定时器。
add_timer(&twdr->twcal_timer);
} else {
//如果原本超时时间太小,则修改定时器的超时时间
if (time_after(twdr->twcal_timer.expires,
jiffies + (slot << INET_TWDR_RECYCLE_TICK)))
mod_timer(&twdr->twcal_timer,
jiffies + (slot << INET_TWDR_RECYCLE_TICK));
//和上面的tw_timer定时器类似,我们要通过当前正在执行的slot也就是twcal_hand来得到真正的slot。
slot = (twdr->twcal_hand + slot) & (INET_TWDR_RECYCLE_SLOTS - 1);
}
//取得该插入的桶。
list = &twdr->twcal_row[slot];
}
//将tw加入到对应的链表中。
hlist_add_head(&tw->tw_death_node, list);
//如果第一次则启动定时器。
if (twdr->tw_count++ == 0)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
spin_unlock(&twdr->death_lock);
}
我们先来总结一下上面的代码。当我们进入tw状态,然后我们会根据计算出来的timeo的不同来加载到不同的hash表中。而对应的定时器一个(tw_timer)是每peroid启动一次,一个是每(slot << INET_TWDR_RECYCLE_TICK)启动一次。
下面的两张图很好的表示了recycle模式(twcal定时器)和非recycle模式的区别:
先是非recycle模式:
然后是recycle模式:
接下来我们来看两个超时函数的实现,这里我只简单的介绍下两个超时函数,一个是inet_twdr_hangman,一个是inet_twdr_twcal_tick。
在inet_twdr_hangman中,每次只是遍历对应的slot的队列,然后将队列中的所有sock删除,同时也从bind_hash中删除对应的端口信息。这个函数就不详细分析了。
而在inet_twdr_twcal_tick中,每次遍历所有的twcal_row,然后超时的进行处理(和上面一样),然后没有超时的继续处理).
这里有一个j的计算要注意,前面我们知道我们的twcal的超时时间可以说都是以INET_TWDR_RECYCLE_SLOTS对齐的,而我们这里在处理超时的同时,有可能上面又有很多sock加入到了tw状态,因此这里我们的超时检测的间隔就是1 << INET_TWDR_RECYCLE_TICK。
来看inet_twdr_twcal_tick的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
void inet_twdr_twcal_tick(unsigned long data)
{
............................
if (twdr->twcal_hand < 0)
goto out;
//得到slot。
slot = twdr->twcal_hand;
//得到定时器启动时候的jiffes。
j = twdr->twcal_jiffie;
//遍历所有的twscok。
for (n = 0; n < INET_TWDR_RECYCLE_SLOTS; n++) {
//判断是否超时。
if (time_before_eq(j, now)) {
//处理超时的socket
struct hlist_node *node, *safe;
struct inet_timewait_sock *tw;
.......................................
} else {
if (!adv) {
adv = 1;
twdr->twcal_jiffie = j;
twdr->twcal_hand = slot;
}
//如果不为空,则将重新添加这些定时器
if (!hlist_empty(&twdr->twcal_row[slot])) {
mod_timer(&twdr->twcal_timer, j);
goto out;
}
}
//设置间隔
j += 1 << INET_TWDR_RECYCLE_TICK;
//更新
slot = (slot + 1) & (INET_TWDR_RECYCLE_SLOTS - 1);
}
//处理完毕则将twcal_hand设为-1.
twdr->twcal_hand = -1;
...............................
}
然后我们来看tcp怎么样进入tw状态。这里分为两种,一种是正常进入也就是在wait2收到一个fin,或者closing收到ack。这种都是比较简单的。我们就不分析了。
比较特殊的是,我们有可能会直接从wait1进入tw状态,或者是在wait2等待超时也将会直接进入tw状态。这个时候也就是没有收到对端的fin。
这个主要是为了处理当对端死在close_wait状态的时候,我们需要自己能够恢复到close状态,而不是一直处于wait2状态。
在看代码之前我们需要知道一个东西,那就是fin超时时间,这个超时时间我们可以通过TCP_LINGER2这个option来设置,并且这个值的最大值是sysctl_tcp_fin_timeout/HZ. 这里可以看到sysctl_tcp_fin_timeout是jiffies数,所以要转成秒。我这里简单的测试了下,linger2的默认值也就是60,刚好是2*MSL.
这里linger2也就是代表在tcp_wait2的最大生命周期。如果小于0则说明我们要跳过tw状态。
先来看在tcp_close中的处理,不过这里不理解为什么这么做的原因。
这里为什么有可能会为wait2状态呢,原因是如果设置了linger,则我们就会休眠掉,而休眠的时间可能我们已经收到ack,此时将会进入wait2的处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
if (sk->sk_state == TCP_FIN_WAIT2) {
struct tcp_sock *tp = tcp_sk(sk);
//如果小于0,则说明从wait2立即超时此时也就是相当于跳过tw状态,所以我们直接发送rst,然后进入close。
if (tp->linger2 < 0) {
tcp_set_state(sk, TCP_CLOSE);
tcp_send_active_reset(sk, GFP_ATOMIC);
NET_INC_STATS_BH(sock_net(sk),
LINUX_MIB_TCPABORTONLINGER);
} else {
//否则计算fin的时间,这里的超时时间是在linger2和3.5RTO之间取最大值。
const int tmo = tcp_fin_time(sk);
//如果超时时间很大,则说明我们需要等待时间很长,因此我们启动keepalive探测对端是否存活。
if (tmo > TCP_TIMEWAIT_LEN) {
inet_csk_reset_keepalive_timer(sk,
tmo - TCP_TIMEWAIT_LEN);
} else {
//否则我们直接进入tw状态。
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto out;
}
}
}
还有从wait1直接进入tw,和上面类似,我就不介绍了。
最后我们来看当内核处于tw状态后,再次接收到数据包后如何处理。这里的处理函数就是tcp_timewait_state_process,而他是在tcp_v4_rcv中被调用的,它会先判断是否处于tw状态,如果是的话,进入tw的处理。
这个函数的返回值分为4种。
1
2
3
4
5
6
7
8
9
10
11
enum tcp_tw_status
{
//这个代表我们成功处理了数据包。
TCP_TW_SUCCESS = 0,
//我们需要发送给对端一个rst。
TCP_TW_RST = 1,
//我们接收到了重传的fin,因此我们需要重传ack。
TCP_TW_ACK = 2,
//这个表示我们需要重新建立一个连接。
TCP_TW_SYN = 3
};
这里可能最后一个比较难理解,这里内核注释得很详细,主要是实现了RFC1122:
引用
RFC 1122:
“When a connection is […] on TIME-WAIT state […] [a TCP] MAY accept a new SYN from the remote TCP to reopen the connection directly, if it:
(1) assigns its initial sequence number for the new connection to be larger than the largest sequence number it used on the previous connection incarnation,and
(2) returns to TIME-WAIT state if the SYN turns out
to be an old duplicate".
来看这段处理代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
case TCP_TW_SYN: {
//取得一个sk。
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),&tcp_hashinfo,
iph->daddr, th->dest,inet_iif(skb));
if (sk2) {
//从tw中删除,然后继续执行(也就是开始三次握手)。
inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row);
inet_twsk_put(inet_twsk(sk));
sk = sk2;
goto process;
}
/* Fall through to ACK */
}
case TCP_TW_ACK:
//发送ack
tcp_v4_timewait_ack(sk, skb);
break;
//发送给对端rst。
case TCP_TW_RST:
goto no_tcp_socket;
//处理成功
case TCP_TW_SUCCESS:;
}
goto discard_it;
tcp_timewait_state_process这个函数具体的实现我就不介绍了,它就是分为两部分,一部分处理tw_substate == TCP_FIN_WAIT2的情况,一部分是正常情况。在前一种情况,我们对于syn的相应是直接rst的。而后一种我们需要判断是否新建连接。
而对于fin的处理他们也是不一样的,wait2的话,它会将当前的tw重新加入到定时器列表(inet_twsk_schedule).而后一种则只是重新发送ack。