

http://blog.csdn.net/DroidPhone/article/details/8104433
我们已经在前面几章介绍了低分辨率定时器和高精度定时器的实现原理,内核为了方便其它子系统,在时间子系统中提供了一些用于延时或调度的API,例如msleep,hrtimer_nanosleep等等,这些API基于低分辨率定时器或高精度定时器来实现,本章的内容就是讨论这些方便、好用的API是如何利用定时器系统来完成所需的功能的。
1. msleep
msleep相信大家都用过,它可能是内核用使用最广泛的延时函数之一,它会使当前进程被调度并让出cpu一段时间,因为这一特性,它不能用于中断上下文,只能用于进程上下文中。要想在中断上下文中使用延时函数,请使用会阻塞cpu的无调度版本mdelay。msleep的函数原型如下:
1
| |
延时的时间由参数msecs指定,单位是毫秒,事实上,msleep的实现基于低分辨率定时器,所以msleep的实际精度只能也是1/HZ级别。内核还提供了另一个比较类似的延时函数msleep_interruptible:
1
| |
延时的单位同样毫秒数,它们的区别如下:
函数 延时单位 返回值 是否可被信号中断
msleep 毫秒 无 否
msleep_interruptible 毫秒 未完成的毫秒数 是
最主要的区别就是msleep会保证所需的延时一定会被执行完,而msleep_interruptible则可以在延时进行到一半时被信号打断而退出延时,剩余的延时数则通过返回值返回。两个函数最终的代码都会到达schedule_timeout函数,它们的调用序列如下图所示:
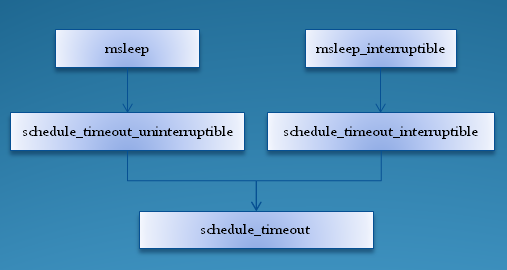
图1.1 两个延时函数的调用序列
下面我们看看schedule_timeout函数的实现,函数首先处理两种特殊情况,一种是传入的延时jiffies数是个负数,则打印一句警告信息,然后马上返回,另一种是延时jiffies数是MAX_SCHEDULE_TIMEOUT,表明需要一直延时,直接执行调度即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
然后计算到期的jiffies数,并在堆栈上建立一个低分辨率定时器,把到期时间设置到该定时器中,启动定时器后,通过schedule把当前进程调度出cpu的运行队列:
1 2 3 4 5 | |
到这个时候,进程已经被调度走,那它如何返回继续执行?我们看到定时器的到期回调函数是process_timeout,参数是当前进程的task_struct指针,看看它的实现:
1 2 3 4 | |
噢,没错,定时器一旦到期,进程会被唤醒并继续执行:
1 2 3 4 5 6 7 8 9 10 | |
schedule返回后,说明要不就是定时器到期,要不就是因为其它时间导致进程被唤醒,函数要做的就是删除在堆栈上建立的定时器,返回剩余未完成的jiffies数。
说完了关键的schedule_timeout函数,我们看看msleep如何实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
msleep先是把毫秒转换为jiffies数,通过一个while循环保证所有的延时被执行完毕,延时操作通过schedule_timeout_uninterruptible函数完成,它仅仅是在把进程的状态修改为TASK_UNINTERRUPTIBLE后,调用上述的schedule_timeout来完成具体的延时操作,TASK_UNINTERRUPTIBLE状态保证了msleep不会被信号唤醒,也就意味着在msleep期间,进程不能被kill掉。
看看msleep_interruptible的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
msleep_interruptible通过schedule_timeout_interruptible中转,schedule_timeout_interruptible的唯一区别就是把进程的状态设置为了TASK_INTERRUPTIBLE,说明在延时期间有信号通知,while循环会马上终止,剩余的jiffies数被转换成毫秒返回。实际上,你也可以利用schedule_timeout_interruptible或schedule_timeout_uninterruptible构造自己的延时函数,同时,内核还提供了另外一个类似的函数,不用我解释,看代码就知道它的用意了:
1 2 3 4 5 | |
2. hrtimer_nanosleep
第一节讨论的msleep函数基于时间轮定时系统,只能提供毫秒级的精度,实际上,它的精度取决于HZ的配置值,如果HZ小于1000,它甚至无法达到毫秒级的精度,要想得到更为精确的延时,我们自然想到的是要利用高精度定时器来实现。没错,linux为用户空间提供了一个api:nanosleep,它能提供纳秒级的延时精度,该用户空间函数对应的内核实现是sys_nanosleep,它的工作交由高精度定时器系统的hrtimer_nanosleep函数实现,最终的大部分工作则由do_nanosleep完成。调用过程如下图所示:
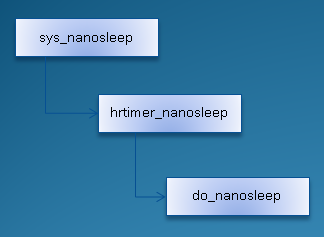
图 2.1 nanosleep的调用过程
与msleep的实现相类似,hrtimer_nanosleep函数首先在堆栈中创建一个高精度定时器,设置它的到期时间,然后通过do_nanosleep完成最终的延时工作,当前进程在挂起相应的延时时间后,退出do_nanosleep函数,销毁堆栈中的定时器并返回0值表示执行成功。不过do_nanosleep可能在没有达到所需延时数量时由于其它原因退出,如果出现这种情况,hrtimer_nanosleep的最后部分把剩余的延时时间记入进程的restart_block中,并返回ERESTART_RESTARTBLOCK错误代码,系统或者用户空间可以根据此返回值决定是否重新调用nanosleep以便把剩余的延时继续执行完成。下面是hrtimer_nanosleep的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
接着我们看看do_nanosleep的实现代码,它首先通过hrtimer_init_sleeper函数,把定时器的回调函数设置为hrtimer_wakeup,把当前进程的task_struct结构指针保存在hrtimer_sleeper结构的task字段中:
1 2 3 4 5 6 7 8 9 10 | |
然后,通过一个do/while循环内:启动定时器,挂起当前进程,等待定时器或其它事件唤醒进程。这里的循环体实现比较怪异,它使用hrtimer_active函数间接地判断定时器是否到期,如果hrtimer_active返回false,说明定时器已经过期,然后把hrtimer_sleeper结构的task字段设置为NULL,从而导致循环体的结束,另一个结束条件是当前进程收到了信号事件,所以,当因为是定时器到期而退出时,do_nanosleep返回true,否则返回false,上述的hrtimer_nanosleep正是利用了这一特性来决定它的返回值。以下是do_nanosleep循环体的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
除了hrtimer_nanosleep,高精度定时器系统还提供了几种用于延时/挂起进程的api:
schedule_hrtimeout 使得当前进程休眠指定的时间,使用CLOCK_MONOTONIC计时系统;
schedule_hrtimeout_range 使得当前进程休眠指定的时间范围,使用CLOCK_MONOTONIC计时系统;
schedule_hrtimeout_range_clock 使得当前进程休眠指定的时间范围,可以自行指定计时系统;
usleep_range 使得当前进程休眠指定的微妙数,使用CLOCK_MONOTONIC计时系统;
它们之间的调用关系如下:
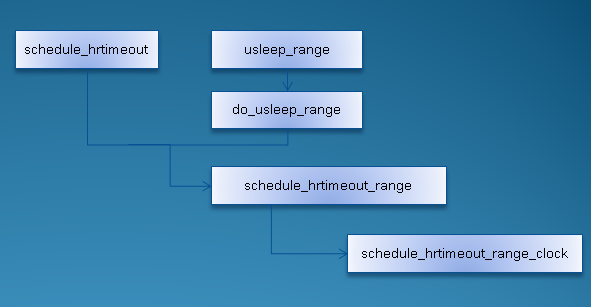
图 2.2 schedule_hrtimeout_xxxx系列函数
最终,所有的实现都会进入到schedule_hrtimeout_range_clock函数。需要注意的是schedule_hrtimeout_xxxx系列函数在调用前,最好利用set_current_state函数先设置进程的状态,在这些函数返回前,进城的状态会再次被设置为TASK_RUNNING。如果事先把状态设置为TASK_UNINTERRUPTIBLE,它们会保证函数返回前一定已经经过了所需的延时时间,如果事先把状态设置为TASK_INTERRUPTIBLE,则有可能在尚未到期时由其它信号唤醒进程从而导致函数返回。主要实现该功能的函数schedule_hrtimeout_range_clock和前面的do_nanosleep函数实现原理基本一致。大家可以自行参考内核的代码,它们位于:kernel/hrtimer.c。