

https://tqr.ink/2017/05/01/intel-82599-transmit-packet/
这篇文档主要介绍了网络数据包在二层的发送流程。网络数据包在二层的发送主要包括了网络设备层和驱动层两个部分,所以下面将会从这两个方面讲述报文在二层的发送流程。
网络设备层在报文发送时的处理流程
当网络协议栈上层准备好了待发送的报文,即构造了一个管理着待发送报文数据的skb对象之后,便会调用网络设备层的主入口函数dev_queue_xmit()进行后续的发送处理。
当上层已经准备好的skb对象达到网络设备层之后,一般来说并不是直接交给网卡驱动的(在没有设置TCQ_F_CAN_BYPASS的情况下),而是会用类型为struct netdev_queue的发送队列先将skb对象缓存起来,接着依次处理发送队列中的skb对象,将其中的报文数据交给网卡发送出去。而在类型为struct netdev_queue的发送队列中,真正用来缓存skb对象的则是类型为struct Qdisc的实例,该类型的实例通常会实现一组出入队列的回调函数,来实现skb的缓存,重传和移除等操作。当发送队列中struct Qdisc的实例设置了TCQ_F_CAN_BYPASS标志的时候,会将上层下发的skb对象直接通过网卡驱动交给网卡进行发送。
下图是网络设备层的报文发送主要流程:
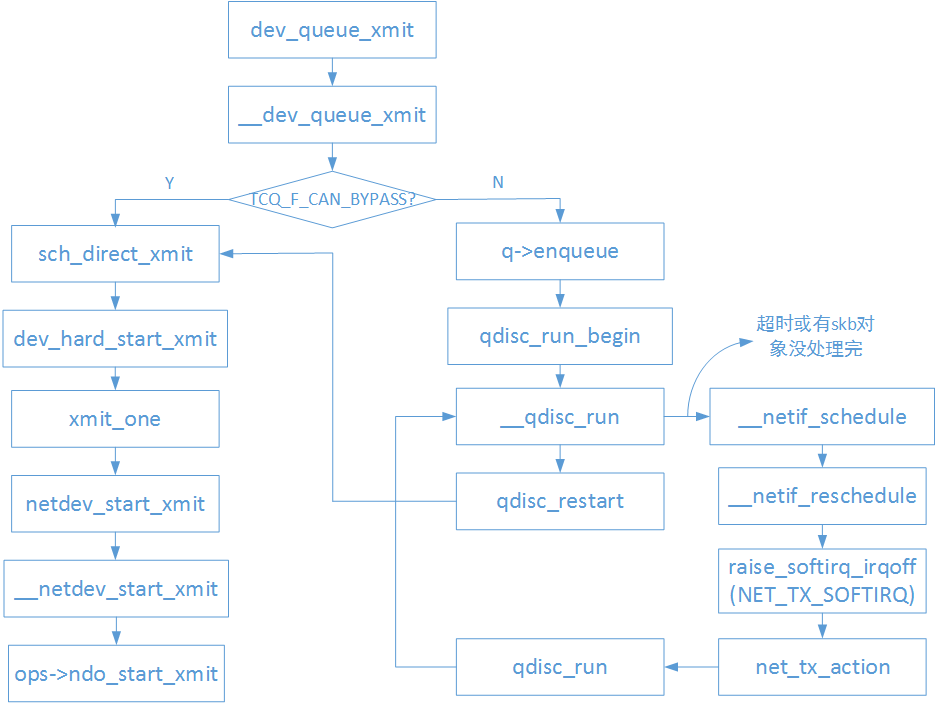
图1 网络设备层报文发送流程图
从上图中我们可以看到在网络设备层用struct Qdisc队列实例来缓存skb对象时,会调用函数 __qdisc_run() 来处理struct Qdisc队列实例中的skb对象,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
从 __qdisc_run() 函数的实现我们可以看到会有如下两种情况发生:
1) 一次性将struct Qdisc队列实例中所有的skb对象通过网卡驱动交给网卡发送出去。
2) 在某次处理struct Qdisc队列实例中的skb对象时,由于某些原因中途停止了,队列实例中可能还有skb对象没有处理完。
当struct Qdisc队列实例中还有skb对象没有处理完时,就会调用netif_schedule()函数触发一次发送软中断(NET_TX_SOFTIRQ),并将struct Qdisc队列实例加入到cpu私有数据对象softnet_data的output_queue链表成员中,在软中断中会遍历output_queue,继续处理其中的struct Qdisc队列实例剩余的skb对象。发送软中断处理函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
在net_tx_action()函数的实现中可以看到,其间接又调用了 __qdisc_run() 函数,这说明只要struct Qdisc队列实例中有skb对象没有处理完,就会继续触发发送软中断直到所有的队列中所有的skb对象都被处理完。
ixgbe驱动中和数据发送相关的内容
在二层网络报文接收流程中,接收报文描述符承载了报文从网卡到主存的过程,与之相对应的,发送报文描述符则承载了报文从主存到网卡的过程。对于网卡驱动而言,当收到来自协议栈上层下发的网络报文时,网卡驱动会将存放着报文数据的地址写入到报文发送描述符中,并将填充了报文地址信息的描述符传递给网卡,而网卡则从报文发送描述符中存放的地址中读取报文数据。
报文发送描述符
对于82599网卡而言,其支持两种格式的报文发送描述符,即传统格式和高级格式。虽然有两种不同格式的报文发送描述符,但是两种格式的报文发送描述符所占用的内存大小是一样的(目前为16字节),只是对这块内存使用有所不同。对于两种不同格式的报文发送描述符,可以通过设置报文发送描述符中的TDESC.DEXT位进行区分,当该位设置为0的时候,表明使用的是传统格式;当该位设置为1的时候,表明使用的是高级格式。下面介绍高级格式的报文发送描述符。
相比于传统格式,高级格式的报文发送描述符可以用来支持更多的功能特性。高级格式的报文描述符由于需要支持更多的功能特性,所以分为了读格式和回写格式。
先来看下82599网卡中读格式的定义,如下图:

图2 高级格式报文发送描述符-读格式
从图中可以看到,读格式的报文发送描述符中主要包含了报文数据所在的内存地址和一些报文元信息,如报文长度等。这里不再详述,详细可以参考82599网卡的datasheet。
再来看下82599网卡中回写格式的定义:

图3 高级格式报文发送描述符-回写格式
从图中可以看到,回写格式的报文发送描述符中有效的域很少,只有STA,而STA中有效位有只有DD位,网卡驱动可以通过该位是否被置位来判断报文发送描述符对应的报文数据是否已经被网卡处理过了。
在初始化阶段,网卡驱动会申请一定数量的报文发送描述符,并将这些内存进行dma一致性映射,获取对应的物理地址,并写入到网卡的寄存器中,这样网卡驱动和网卡就能同时操作这些报文发送描述符了。当网卡驱动收到协议栈下发的skb对象后,会将skb对象中存放的报文数据进行dma映射,获取对应的物理地址,并存放到报文发送描述符中对应的成员中,这样网卡就能从报文发送描述符中获取存放了报文数据的物理地址,然后从该地址中读取报文数据,并发送到网络中去。
报文发送描述符环形队列
上面说到,报文发送描述符承载了报文从主存流入到网卡的过程,是网卡驱动和网卡都会操作的对象,那么自然而然会有以下几个疑问:
1)、报文发送描述符是以何种组织形式在网卡驱动和网卡之间进行传递的?
2)、网卡驱动怎么通知网卡报文发送描述符可用的?
在报文发送流程中,报文发送描述符是通过环形队列来管理的,当然这个环形队列是逻辑上的,队列中的描述符在内存上是连续的。网卡或者网卡驱动在进行操作的时候,如果发现已经到达了队列的末尾,那么下次操作又会从队列头部开始,从而实现环形的操作逻辑。报文发送描述符环形队列的结构体如下:
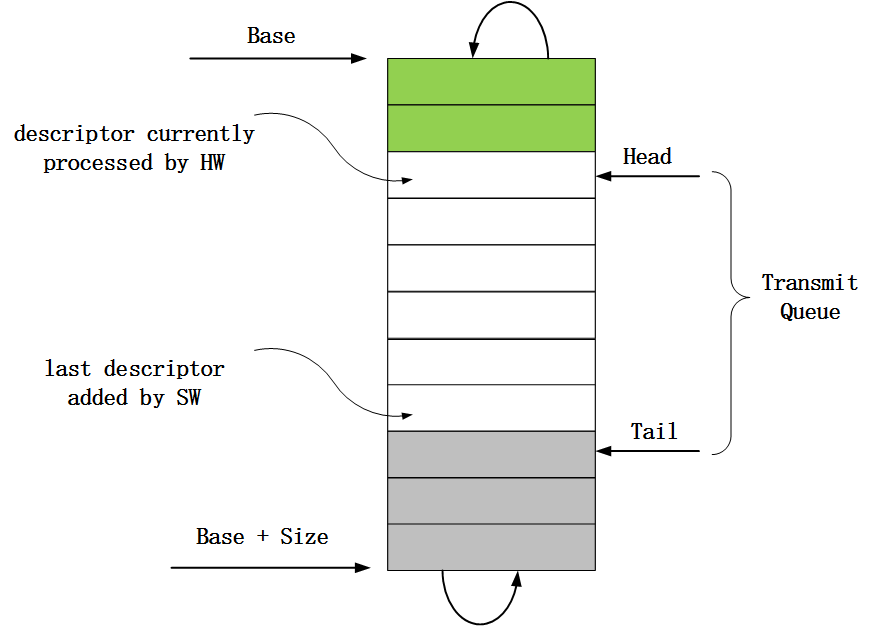
图4 报文发送描述符环形队列结构
对于第一和第二个问题,其中也已经在上面的描述符环形队列图中有体现。在对问题进行回答之前先要了解下82599网卡中和报文发送描述符环形队列相关的几个寄存器。
1)、TDBA寄存器。这个寄存器存放了报文发送描述符环形队列的起始地址,也就是上图中Base指向的地址。
2)、TDLEN寄存器。这个寄存器存放了报文发送描述符环形队列的长度,也就是报文发送描述符环形队列所占用的字节数,对应上图中的Size。
3)、TDH寄存器。这个寄存器存放的是一个距离队列头部的偏移值,代表的是第一个填充了报文地址信息的描述符。当网卡处理完一个描述符对应的报文数据后,就会更新TDH寄存器的值,使之指向下一个填充了报文地址信息的描述符。也就是说这个寄存器的值是由网卡来更新的,该寄存器对应上图中的Head。
4)、TDT寄存器。这个寄存器存放的也是一个距离队列头部的偏移值,代表的是最后一个存放了报文地址信息的描述符的下一个描述符。当网卡驱动将一个skb对象中所有的数据分段对应的物理地址都填充到了对应的报文发送描述符中后,就会更新该寄存器的值,使之指向下一个即将被填充报文地址信息并给网卡使用的描述符,该寄存器对应上图中的Tail。
在了解了这几个寄存器的作用之后,对于本节一开始提出的两个问题就比较容易知晓了。对于第一个问题,报文描述符是以环形队列的方式来组织的;对于第二个问题,因为网卡驱动在填充完一个skb对象中数据分段的报文地址信息到报文发送描述符后,网卡驱动都会更新TDT寄存器的值,所以网卡可以根据TDT寄存器知道自己当前可用的描述符信息,简单来说TDH和TDT之间的描述符就是网卡可以使用的。
数据分段和报文发送描述符关系
上面说到网卡驱动会将skb对象中存放了报文数据的内存进行dma映射,并将得到的物理地址存放到报文发送描述符中,而一个skb对象中可能存有多个数据分段,对于这种情况,网卡驱动则会将一个数据分段对应一个报文发送描述符,其对应关系如下图:
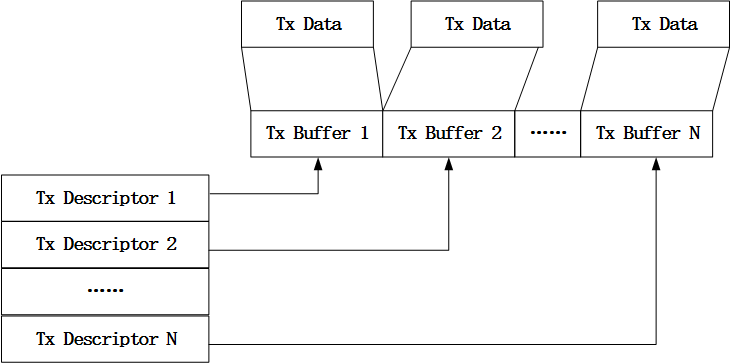
图5 数据分段与报文发送描述符对应关系
报文发送描述符的回收
当网卡完成报文发送之后,就会触发硬件中断。这里需要注意的是,新的数据包达到或者外发数据包的传输已经完成所触发的中断对应的中断号是同一个,所以在这个中断号对应的中断处理函数中需要考虑到是新的数据包达到所产生的中断,还是外发数据包的传输已经完成触发的中断。
另外,ixgbe驱动中因为使用了NAPI的收包方式,所以在中断处理函数中只是调用NAPI模块调度接口napi_schedule_irqoff()将设备加入到cpu私有数据中类型为struct softnet_data的对象的待轮询设备链表中,并触发软中断,而在软中断处理函数net_rx_action()中又只会调用设备注册的NAPI回调函数poll。所以无论是新的数据包达到,或者是外发数据包的传输已经完成所触发的中断,最终都会调用设备注册给NAPI接口的poll回调函数,因此报文发送描述符的回收也是在这个函数中完成的,在ixgbe驱动中,poll回调函数就是ixgbe_poll()。在ixgbe_poll()函数中又会调用ixgbe_clean_tx_irq()函数来完成报文发送描述符的回收,该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 | |
到这里,报文在二层的发送流程就介绍完了。