

http://www.wowotech.net/kernel_synchronization/460.html
自旋锁用于处理器之间的互斥,适合保护很短的临界区,并且不允许在临界区睡眠。申请自旋锁的时候,如果自旋锁被其他处理器占有,本处理器自旋等待(也称为忙等待)。
进程、软中断和硬中断都可以使用自旋锁。
自旋锁的实现经历了3个阶段:
(1) 最早的自旋锁是无序竞争的,不保证先申请的进程先获得锁。
(2) 第2个阶段是入场券自旋锁,进程按照申请锁的顺序排队,先申请的进程先获得锁。
(3) 第3个阶段是MCS自旋锁。入场券自旋锁存在性能问题:所有申请锁的处理器在同一个变量上自旋等待,缓存同步的开销大,不适合处理器很多的系统。MCS自旋锁的策略是为每个处理器创建一个变量副本,每个处理器在自己的本地变量上自旋等待,解决了性能问题。
入场券自旋锁和MCS自旋锁都属于排队自旋锁(queued spinlock),进程按照申请锁的顺序排队,先申请的进程先获得锁。
1. 数据结构
自旋锁的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 | |
可以看到,数据类型spinlock对raw_spinlock做了封装,然后数据类型raw_spinlock对arch_spinlock_t做了封装,各种处理器架构需要自定义数据类型arch_spinlock_t。
spinlock和raw_spinlock(原始自旋锁)有什么关系?
Linux内核有一个实时内核分支(开启配置宏CONFIG_PREEMPT_RT)来支持硬实时特性,内核主线只支持软实时。
对于没有打上实时内核补丁的内核,spinlock只是封装raw_spinlock,它们完全一样。如果打上实时内核补丁,那么spinlock使用实时互斥锁保护临界区,在临界区内可以被抢占和睡眠,但raw_spinlock还是自旋锁。
目前主线版本还没有合并实时内核补丁,说不定哪天就会合并进来,为了使代码可以兼容实时内核,最好坚持3个原则:
(1)尽可能使用spinlock。
(2)绝对不允许被抢占和睡眠的地方,使用raw_spinlock,否则使用spinlock。
(3)如果临界区足够小,使用raw_spinlock。
2. 使用方法
定义并且初始化静态自旋锁的方法是:
1
| |
在运行时动态初始化自旋锁的方法是:
1
| |
申请自旋锁的函数是:
1 2 3 4 5 | |
释放自旋锁的函数是:
1 2 3 4 | |
定义并且初始化静态原始自旋锁的方法是:
1
| |
在运行时动态初始化原始自旋锁的方法是:
1
| |
申请原始自旋锁的函数是:
1 2 3 4 5 | |
释放原始自旋锁的函数是:
1 2 3 4 | |
3. 入场券自旋锁
入场券自旋锁(ticket spinlock)的算法类似于银行柜台的排队叫号:
1 2 3 | |
ARM64架构定义的数据类型arch_spinlock_t如下所示:
1 2 3 4 5 6 7 8 9 10 | |
成员next是排队号,成员owner是服务号。
在多处理器系统中,函数spin_lock()负责申请自旋锁,ARM64架构的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
第6~18行代码,申请排队号,然后把自旋锁的排队号加1,这是一个原子操作,有两种实现方法:
1)第9~13行代码,使用指令ldaxr(带有获取语义的独占加载)和stxr(独占存储)实现,指令ldaxr带有获取语义,后面的加载/存储指令必须在指令ldaxr完成之后开始执行。
2)第15~16行代码,如果处理器支持大系统扩展,那么使用带有获取语义的原子加法指令ldadda实现,指令ldadda带有获取语义,后面的加载/存储指令必须在指令ldadda完成之后开始执行。
第21~22行代码,如果服务号等于当前进程的排队号,进入临界区。
第24~27行代码,如果服务号不等于当前进程的排队号,那么自旋等待。使用指令ldaxrh(带有获取语义的独占加载,h表示halfword,即2字节)读取服务号,指令ldaxrh带有获取语义,后面的加载/存储指令必须在指令ldaxrh完成之后开始执行。
第23行代码,sevl(send event local)指令的功能是发送一个本地事件,避免错过其他处理器释放自旋锁时发送的事件。
第24行代码,wfe(wait for event)指令的功能是使处理器进入低功耗状态,等待事件。
函数spin_unlock()负责释放自旋锁,ARM64架构的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
把自旋锁的服务号加1,有两种实现方法:
(1)第7~9行代码,使用指令ldrh(加载,h表示halfword,即2字节)和stlrh(带有释放语义的存储)实现,指令stlrh带有释放语义,前面的加载/存储指令必须在指令stlrh开始执行之前执行完。因为一次只能有一个进程进入临界区,所以只有一个进程把自旋锁的服务号加1,不需要是原子操作。
(2)第11~12行代码,如果处理器支持大系统扩展,那么使用带有释放语义的原子加法指令staddlh实现,指令staddlh带有释放语义,前面的加载/存储指令必须在指令staddlh开始执行之前执行完。
在单处理器系统中,自旋锁是空的。
1 2 3 4 5 6 7 8 9 10 | |
4. MCS自旋锁
入场券自旋锁存在性能问题:所有等待同一个自旋锁的处理器在同一个变量上自旋等待,申请或者释放锁的时候会修改锁,导致其他处理器存放自旋锁的缓存行失效,在拥有几百甚至几千个处理器的大型系统中,处理器申请自旋锁时竞争可能很激烈,缓存同步的开销很大,导致系统性能大幅度下降。
MCS(MCS是“Mellor-Crummey”和“Scott”这两个发明人的名字的首字母缩写)自旋锁解决了这个缺点,它的策略是为每个处理器创建一个变量副本,每个处理器在申请自旋锁的时候在自己的本地变量上自旋等待,避免缓存同步的开销。
4.1. 传统的MCS自旋锁
传统的MCS自旋锁包含:
(1)一个指针tail指向队列的尾部。
(2)每个处理器对应一个队列节点,即mcs_lock_node结构体,其中成员next指向队列的下一个节点,成员locked指示锁是否被其他处理器占有,如果成员locked的值为1,表示锁被其他处理器占有。
结构体的定义如下所示:
1 2 3 4 5 6 7 8 9 | |
其中____cacheline_aligned_in_smp 的作用是:在多处理器系统中,结构体的起始地址和长度都是一级缓存行长度的整数倍。
当没有处理器占有或者等待自旋锁的时候,队列是空的,tail是空指针。
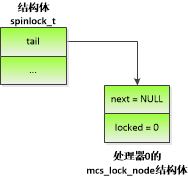
图 4.1 处理器0申请MCS自旋锁
如图 4.1所示,当处理器0申请自旋锁的时候,执行原子交换操作,使tail指向处理器0的mcs_lock_node结构体,并且返回tail的旧值。tail的旧值是空指针,说明自旋锁处于空闲状态,那么处理器0获得自旋锁。
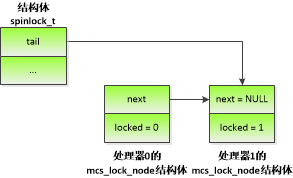
图 4.2 处理器1申请MCS自旋锁
如图 4.2所示,当处理器0占有自旋锁的时候,处理器1申请自旋锁,执行原子交换操作,使tail指向处理器1的mcs_lock_node结构体,并且返回tail的旧值。tail的旧值是处理器0的mcs_lock_node结构体的地址,说明自旋锁被其他处理器占有,那么使处理器0的mcs_lock_node结构体的成员next指向处理器1的mcs_lock_node结构体,把处理器1的mcs_lock_node结构体的成员locked设置为1,然后处理器1在自己的mcs_lock_node结构体的成员locked上面自旋等待,等待成员locked的值变成0。
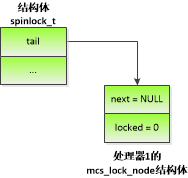
图 4.3 处理器0释放MCS自旋锁
如图 4.3所示,处理器0释放自旋锁,发现自己的mcs_lock_node结构体的成员next不是空指针,说明有申请者正在等待锁,于是把下一个节点的成员locked设置为0,处理器1获得自旋锁。
处理器1释放自旋锁,发现自己的mcs_lock_node结构体的成员next是空指针,说明自己是最后一个申请者,于是执行原子比较交换操作:如果tail指向自己的mcs_lock_node结构体,那么把tail设置为空指针。
4.2. 小巧的MCS自旋锁
传统的MCS自旋锁存在的缺陷是:结构体的长度太大,因为mcs_lock_node结构体的起始地址和长度都必须是一级缓存行长度的整数倍,所以MCS自旋锁的长度是(一级缓存行长度 + 处理器数量 * 一级缓存行长度),而入场券自旋锁的长度只有4字节。自旋锁被嵌入到内核的很多结构体中,如果自旋锁的长度增加,会导致这些结构体的长度增加。
经过内核社区技术专家的努力,成功地把MCS自旋锁放进4个字节,实现了小巧的MCS自旋锁。自旋锁的定义如下所示:
1 2 3 4 5 | |
另外,为每个处理器定义1个队列节点数组,如下所示:
1 2 3 4 5 6 7 | |
配置宏CONFIG_PARAVIRT_SPINLOCKS用来启用半虚拟化的自旋锁,给虚拟机使用,本文不考虑这种使用场景。每个处理器需要4个队列节点,原因如下:
(1) 申请自旋锁的函数禁止内核抢占,所以进程在等待自旋锁的过程中不会被其他进程抢占。
(2) 进程在等待自旋锁的过程中可能被软中断抢占,然后软中断等待另一个自旋锁。
(3) 软中断在等待自旋锁的过程中可能被硬中断抢占,然后硬中断等待另一个自旋锁。
(4) 硬中断在等待自旋锁的过程中可能被不可屏蔽中断抢占,然后不可屏蔽中断等待另一个自旋锁。
综上所述,一个处理器最多同时等待4个自旋锁。
和入场券自旋锁相比,MCS自旋锁增加的内存开销是数组mcs_nodes。
队列节点的定义如下所示:
1 2 3 4 5 6 7 | |
其中成员next指向队列的下一个节点;成员locked指示锁是否被前一个等待者占有,如果值为1,表示锁被前一个等待者占有;成员count是嵌套层数,也就是数组mcs_nodes已分配的数组项的数量。
自旋锁的32个二进制位被划分成4个字段:
(1) locked字段,指示锁已经被占有,长度是一个字节,占用第0~7位。
(2) 一个pending位,占用第8位,第1个等待自旋锁的处理器设置pending位。
(3) index字段,是数组索引,指示队列的尾部节点使用数组mcs_nodes的哪一项。
(4) cpu字段,存放队列的尾部节点的处理器编号,实际存储的值是处理器编号加上1,cpu字段减去1才是真实的处理器编号。
index字段和cpu字段合起来称为tail字段,存放队列的尾部节点的信息,布局分两种情况:
(1) 如果处理器的数量小于2的14次方,那么第9~15位没有使用,第16~17位是index字段,第18~31位是cpu字段。
(2) 如果处理器的数量大于或等于2的14次方,那么第9~10位是index字段,第11~31位是cpu字段。
把MCS自旋锁放进4个字节的关键是:存储处理器编号和数组索引,而不是存储尾部节点的地址。
内核对MCS自旋锁做了优化:第1个等待自旋锁的处理器直接在锁自身上面自旋等待,不是在自己的mcs_spinlock结构体上自旋等待。这个优化带来的好处是:当锁被释放的时候,不需要访问mcs_spinlock结构体的缓存行,相当于减少了一次缓存没命中。后续的处理器在自己的mcs_spinlock结构体上面自旋等待,直到它们移动到队列的首部为止。
自旋锁的pending位进一步扩展这个优化策略。第1个等待自旋锁的处理器简单地设置pending位,不需要使用自己的mcs_spinlock结构体。第2个处理器看到pending被设置,开始创建等待队列,在自己的mcs_spinlock结构体的locked字段上自旋等待。这种做法消除了两个等待者之间的缓存同步,而且第1个等待者没使用自己的mcs_spinlock结构体,减少了一次缓存行没命中。
在多处理器系统中,申请MCS自旋锁的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
第7行代码,执行带有获取语义的原子比较交换操作,如果锁的值是0,那么把锁的locked字段设置为1。获取语义保证后面的加载/存储指令必须在函数atomic_cmpxchg_acquire()完成之后开始执行。函数atomic_cmpxchg_acquire()返回锁的旧值。
第8~9行代码,如果锁的旧值是0,说明申请锁的时候锁处于空闲状态,那么成功地获得锁。
第10行代码,如果锁的旧值不是0,说明锁不是处于空闲状态,那么执行申请自旋锁的慢速路径。
申请MCS自旋锁的慢速路径如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | |
第8~11行代码,如果锁的状态是pending,即{tail=0,pending=1,locked=0},那么等待锁的状态变成locked,即{tail=0,pending=0,locked=1}。
第14~15行代码,如果锁的tail字段不是0或者pending位是1,说明已经有处理器在等待自旋锁,那么跳转到标号queue,本处理器加入等待队列。
第17~21行代码,如果锁处于locked状态,那么把锁的状态设置为locked & pending,即{tail=0,pending=1,locked=1};如果锁处于空闲状态(占有锁的处理器刚刚释放自旋锁),那么把锁的状态设置为locked。
第28~29行代码,如果上一步锁的状态从空闲变成locked,那么成功地获得锁。
第31行代码,等待占有锁的处理器释放自旋锁,即锁的locked字段变成0。
第32行代码,成功地获得锁,把锁的状态从pending改成locked,即清除pending位,把locked字段设置为1。
从第2个等待自旋锁的处理器开始,需要加入等待队列,处理如下:
(1) 第37~43行代码,从本处理器的数组mcs_nodes分配一个数组项,然后初始化。
(2) 第46~47行代码,如果锁处于空闲状态,那么获得锁。
(3) 第49行代码,把自旋锁的tail字段设置为本处理器的队列节点的信息,并且返回前一个队列节点的信息。
(4) 第52行代码,如果本处理器的队列节点不是队列首部,那么处理如下:
1)第56行代码,把前一个队列节点的next字段设置为本处理器的队列节点的地址。
2)第59行代码,本处理器在自己的队列节点的locked字段上面自旋等待,等待locked字段从0变成1,也就是等待本处理器的队列节点移动到队列首部。
(5) 第67行代码,本处理器的队列节点移动到队列首部以后,在锁自身上面自旋等待,等待自旋锁的pending位和locked字段都变成0,也就是等待锁的状态变成空闲。
(6) 锁的状态变成空闲以后,本处理器把锁的状态设置为locked,分两种情况:
1)第71行代码,如果队列还有其他节点,即还有其他处理器在等待锁,那么处理如下:
q第72行代码,把锁的locked字段设置为1。
q第83~86行代码,等待下一个等待者设置本处理器的队列节点的next字段。
q第88行代码,把下一个队列节点的locked字段设置为1。
2)第76行代码,如果队列只有一个节点,即本处理器是唯一的等待者,那么把锁的tail字段设置为0,把locked字段设置为1。
(7) 第92行代码,释放本处理器的队列节点。
释放MCS自旋锁的代码如下所示:
1 2 3 4 5 6 7 8 9 | |
第5行代码,执行带释放语义的原子减法操作,把锁的locked字段设置为0,释放语义保证前面的加载/存储指令在函数atomic_sub_return_release()开始执行之前执行完。
MCS自旋锁的配置宏是CONFIG_ARCH_USE_QUEUED_SPINLOCKS 和CONFIG_QUEUED_SPINLOCKS,目前只有x86处理器架构使用MCS自旋锁,默认开启MCS自旋锁的配置宏,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |