

https://blog.csdn.net/qq_38766930/article/details/123703178
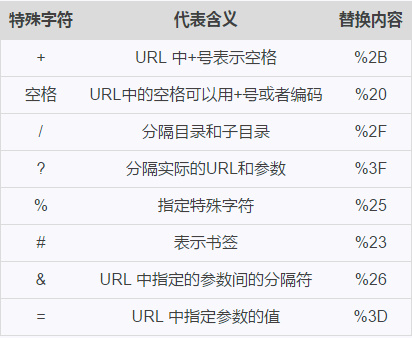
+、空格、=、%、&、#等字符
urlencode rawurlencode
https://www.jianshu.com/p/99c09270ad52
其实对于URL编码,rawurlencode才是标准,它定义在 RFC3986 上,这个 RFC 描述了如何定义一个 URL,URL 其实本质上不是 HTTP 协议的一部分,只是 URL 和 HTTP 协议结合的比较紧密,所以总觉得 HTTP 协议包含 URL。
先描述下rawurlencode,它也叫做百分号编码(Percent-encoding),首先思考一个问题,为什么URL需要编码,原因就在于早期的 URL 只有 ASCII 字符,所以无需编码。
但世界上有多种语言,为了让 URL 符合语义标准,必须转码,主要有以下几种字符需要编码:
1 2 3 4 | |
那么具体如何编码呢?
1 2 3 | |
接着说说urlencode,它基于rawurlencode标准,但有略微的不同,它定义在rfc1866,这个rfc属于html标准的一部分,编码方式和 application/x-www-form-urlencoded MIME 编码方式一致。
urlencode处理 query string 的编码,而 rawurlencode 被认为处理 url 编码,这可以看做一个区别。
urlencode 和 rawurlencode 在编码方式上有二处区别:
1 2 | |
那么为什么不能保持一致呢?可能是历史原因,但 rfc2396 认为 url 中的 + 符号是一个保留字符,所以 rawurlencode 编码方式更标准。
PHP htmlspecialchars() 函数
https://www.w3school.com.cn/php/func_string_htmlspecialchars.asp
htmlspecialchars() 函数把预定义的字符转换为 HTML 实体。
预定义的字符是:
1 2 3 4 5 | |
https://blog.csdn.net/YungGuo/article/details/110197818
apache log 中,参数之前的url是 \x , 参数是 %
例如
1
| |
%
如果是 % 直接用 urldecode
1
| |
\x
1 2 | |
上面这个是utf-8编码,但数据类型是字符串类型,而不是bytes类型的utf-8编码。
这样会导致一个结果:如果直接输出,显示的是乱码,也不能使用decode进行utf-8解码得到中文。
可能有人会说,既然得到的是utf-8编码,在前面加上 “ b ” ,字符串就是bytes类型了,再利用decode进行解码不就可以得到中文吗?但显然,这是行不通的,你不可能去手动一个个添加,那有没有其他方法呢?
答案肯定是有的,既然知道这个字符串是utf-8编码的,那么我换种方式,只要将字符串中的 “ \x ” 改为 “ % ” 利用urllib中的unquote方法解码就可以得到中文了,因为url中的中文utf-8编码和这里的区别就是url中编码是%开头。
1
| |