https://blog.csdn.net/nightelve/article/details/16865773
随着数据安全性要求的日益提升,我们越发需要将数据进行加密。在接下来的内容里,我将对比一些常用的对称加密算法:DES(Data Encryption),3DES(Triple DES),AES(Advanced Encryption Standard)以及Blowfish(效能最高)。
介绍
计算机加密技术分为对称加密,及非对称加密两种技术.
对称加密技术基本的实现是:数据发送方和数据接收方共享一个密钥,进行数据加密和解密工作。但是他也有个问题,就是一旦密钥被第三方获取,数据安全性就无法保证。
非对称加密技术中,数据发送方和接收方利用不同的密钥进行数据加密及解密工作。简言之,就是密钥1只能被用来加密数据,与此同时,密钥2用来解密数据。然而这种加密技术容易导致被人利用,通过频繁更新密钥进行攻击。所以说,我们需要把这两种算法结合使用,来构建一个更加强健的加密技术。
下面将对比DES (数据加密标准), 3DES (三重DES), AES (高级加密标准) and Blowfish(河豚鱼)这几种数据加密技术.
DES
数据加密标准是IBM提出的,第一个基于Lucifer算法的加密技术。作为第一个加密标准,自然会带有些许瑕疵漏洞使其不是特别的安全。
3DES
三重DES是DES的加强版,提供了DES的三重安全性。他和DES使用同样的算法,只是做了三次加密来提升安全级别。
AES
高级加密标准是由美国国家标准技术研究院(NIST)提出的,旨在取代DES加密技术。(作者所知道的)针对AES唯一的破解方式就是暴力破解。
Blowfish
Blowfish由Bruce Schneier发明的一种在世界范围被广泛使用的加密方式。Blowfish使用16到448位不同长度的密钥对数据进行16次加密。这样黑客们基本不可能对其进行解密。直到现在(作者发文时),还没有针对blowfish的破解(B. Schneier)
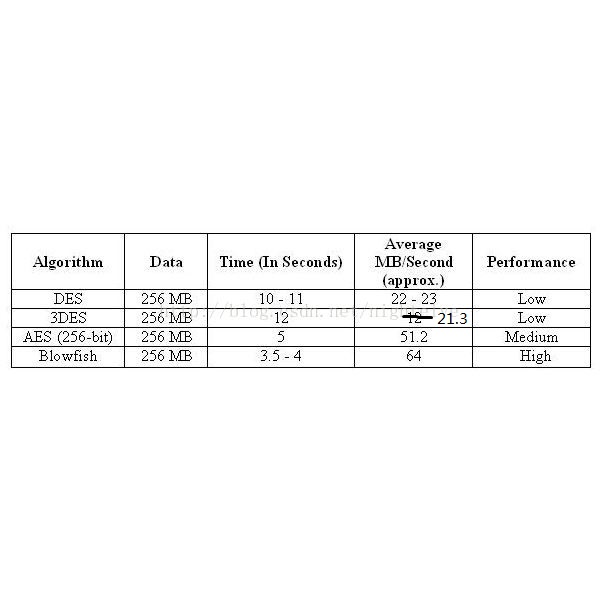
效能对比
根据对比结果,我们发现AES和Blowfish遥遥领先于其他几种加密方式。
底下是一组针对大约256MB尺寸数据进行加密的测试(此测试在Windows XP SP1操作系统,P4 2.1GHz CPU):