目录是 /sys/class/drm/card0/device/hwmon/hwmonX/
换内核之类的操作会改变 hwmonX
调节脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |


目录是 /sys/class/drm/card0/device/hwmon/hwmonX/
换内核之类的操作会改变 hwmonX
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
https://launchpad.net/ubuntu/+source/linux/+changelog
https://launchpad.net/ubuntu/bionic/+source/linux/+changelog
https://packages.ubuntu.com/xenial/linux-source-4.15.0
http://security.ubuntu.com/ubuntu/pool/main/l/linux-hwe/linux-source-4.15.0_4.15.0-58.64~16.04.1_all.deb
https://launchpad.net/ubuntu/xenial/amd64/linux-image-unsigned-4.15.0-58-generic-dbgsym
http://launchpadlibrarian.net/436393485/linux-image-unsigned-4.15.0-58-generic-dbgsym_4.15.0-58.64~16.04.1_amd64.ddeb
https://launchpad.net/ubuntu/bionic/amd64/linux-image-unsigned-4.15.0-58-generic-dbgsym
http://launchpadlibrarian.net/436226708/linux-image-unsigned-4.15.0-58-generic-dbgsym_4.15.0-58.64_amd64.ddeb
https://launchpad.net/ubuntu/xenial/+source/linux/+changelog
https://packages.ubuntu.com/bionic/linux-source-4.18.0
http://security.ubuntu.com/ubuntu/pool/main/l/linux-hwe/linux-source-4.18.0_4.18.0-25.26~18.04.1_all.deb
https://launchpad.net/ubuntu/bionic/amd64/linux-image-4.18.0-25-generic-dbgsym
http://launchpadlibrarian.net/430863032/linux-image-4.18.0-25-generic-dbgsym_4.18.0-25.26~18.04.1_amd64.ddeb
https://blog.gloriousdays.pw/2018/09/09/cannot-find-stdarg-h-on-linux-kernel-4-15-with-gcc-7-3/
这是一个非常奇怪的错误,出现在 Ubuntu 18.04 上,默认安装的内核版本是 4.15,gcc 是 7.3,在编译内核模块时报错:
1 2 3 4 5 6 7 | |
gcc 认为找不到 stdarg.h。看这个错误的位置,个人认为应该不是我配置的问题或者是我代码的问题,搜索了一下,也有很多在 4.15 内核上出现的同样错误。目前没有什么很好的解决方案,暂时性的方案是在编译的 Makefile 里面加一行:
1
| |
如果是 gcc 8,就相应把版本改成 8 就可以了
1 2 3 | |
按这里没成功 https://wiki.ubuntu.com/Kernel/BuildYourOwnKernel
1 2 | |
1 2 | |
https://www.kernel.org/doc/Documentation/cpu-freq/intel-pstate.txt
/sys/devices/system/cpu/intel_pstate/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | |
https://huataihuang.gitbooks.io/cloud-atlas/os/linux/kernel/cpu/intel_pstate.html
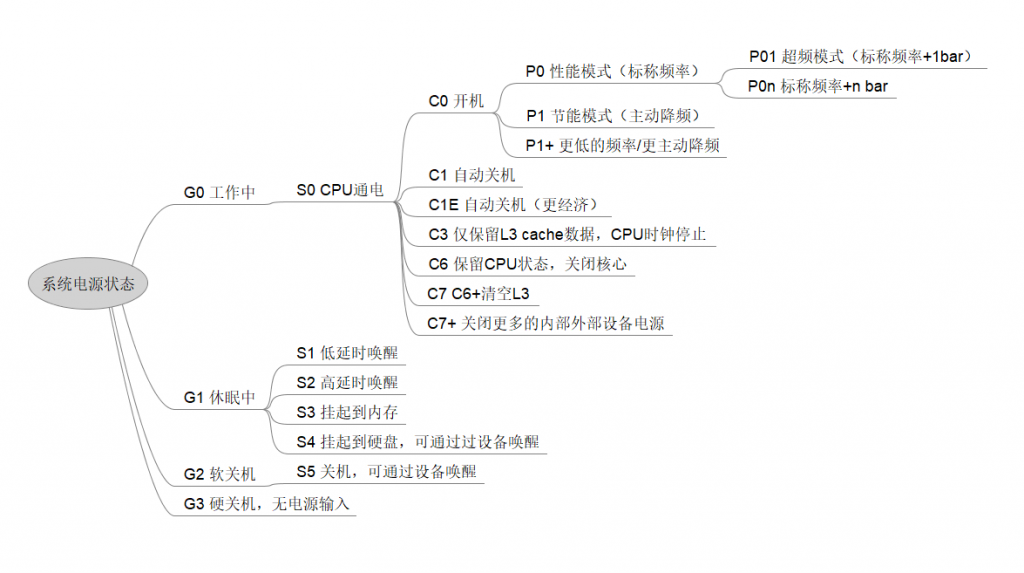
http://www.litrin.net/2018/12/28/cpu%E7%9A%84%E7%94%B5%E6%BA%90%E7%8A%B6%E6%80%81%E5%88%86%E7%B1%BB/