有时候genfull生成的full.graph没有函数调用关系,在CentOS6上生成的图只有那个函数,在CentOS5上会报一个错误
1
Error: <stdin>: syntax error in line 4 near ';'
可以不用自带的genfull,自己写个脚本生成full.graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
echo "digraph fullgraph {" > full.graph
echo "node [ fontname=Helvetica, fontsize=12 ];" >> full.graph
find . -name '*.c.cdepn' -exec cat {} \; | \
awk -F"[ {}]+" '{
if ($1 == "F") {
print "\""$2 "\" [label=\"" $2 "\\n" $3 ":\"];"
} else if ($1 == "C") {
print "\"" $2 "\" -> \"" $4 "\" [label=\"" $3 "\"];"
}
}' \
| sort | uniq -u >> full.graph
echo "}" >> full.graph
http://blog.csdn.net/lanxuezaipiao/article/details/16991731
一、Graphviz + CodeViz简单介绍
CodeViz是《Understanding The Linux Virtual Memory Manager》的作者 Mel Gorman 写的一款分析C/C++源代码中函数调用关系的open source工具(类似的open source软件有 egypt、ncc)。其基本原理是给 GCC 打个补丁(如果你的gcc版本不符合它的要求还得先下载正确的gcc版本),让它在编译每个源文件时 dump 出其中函数的 call graph,然后用 Perl 脚本收集并整理调用关系,转交给Graphviz绘制图形(Graphviz属于后端,CodeViz属于前端)。
CodeViz 原本是作者用来分析 Linux virtual memory 的源码时写的一个小工具,现在已经基本支持 C++ 语言,最新的 1.0.9 版能在 Windows + Cygwin 下顺利地编译使用。
基本介绍就到这儿,如果你对其原理比较感兴趣,可以参考这篇文章:分析函数调用关系图(call graph)的几种方法
二、Graphviz + CodeViz编译安装
CentOS5 需要安装ann_libs http://rpm.pbone.net/index.php3?stat=3&limit=2&srodzaj=3&dl=40&search=ann-libs
1. 安装 GraphViz
调用图的生成依赖于 GraphViz,所以首先要安装 GraphViz。可以下载源码包编译、安装(下载主页:http://www.graphviz.org/Download.php )。
如果是Ubuntu系统可以直接apt安装:
1
sudo apt-get install graphviz
CentOS6
CentOS5
1
2
3
4
wget http://www.graphviz.org/graphviz-rhel.repo
cp graphviz-rhel.repo /etc/yum.repos.d/
yum list available 'graphviz*'
yum install 'graphviz*'
2. 安装 CodeViz
1
yum -y install glibc-devel glibc-devel.i686/i386
错误
1
2
There is no layout engine support for "dot".
Perhaps "dot -c" needs to be run (with installer's privileges) to register the plugins?
执行dot -c
下载CodeVize源码包: http://www.csn.ul.ie/~mel/projects/codeviz/
解压:tar xvf codeviz-1.0.12.tar.gz (目前最新版是1.0.12)
进入解压后的目录:cd codeviz-1.0.12/
CodeViz 使用了一个 patch 版本的 GCC 编译器,而且不同的 CodeViz 版本使用的GCC 版本也不同,可以下载 CodeViz 的源码包后查看 Makefile 文件来确定要使用的 GCC 版本,codeviz-1.0.12 使用 GCC-4.6.2。实际上安装 CodeViz 时安装脚本make会检查当前的GCC版本如果不符合则会自动下载对应的 GCC并打 patch,但由于GCC较大如果网速不好且在虚拟机中的话容易下载失败或系统错误什么的,因此这里我们还是分步安装比较好,先安装gcc再回来安装CodeViz。
(1)安装 GCC
下载gcc-4.6.2.tar.gz到 cd codeviz-1.0.12目录下的compilers里。
下载地址:ftp://ftp.gnu.org/pub/gnu/gcc/gcc-4.6.2/gcc-4.6.2.tar.gz
CodeViz 的安装脚本 compilers/install_gcc-4.6.2.sh 会自动检测 compilers 目录下是否有 gcc 的源码包,若没有则自动下载并打 patch。这里前面已经下载,直接移到该目录即可,则剩下的就是解压安装了。install_gcc-3.4.6.sh 会解压缩 gcc打 patch,并将其安装到指定目录,若是没有指定目录,则缺省使用$HOME/gcc-graph,通常指定安装在/usr/
local/gcc-graph(这时需要 root 权限)。
修改install_gcc-4.6.2.sh文件,将make bootstrap改成make bootstrap CXXFLAGS=-fPIC CFLAGS=-fPIC -j4
安装: ./install_gcc-4.6.2.sh
注意:这里可能安装时有些错误,具体错误及解决方案见后面。
(2)安装 CodeViz
./configure && make install-codeviz
注1:不需要 make ,因为make的作用就是检测是否有gcc若没有则下载源码包,所以这里只要安装 codeviz 即可。具体查看 Makefile 文件。
注意:这里为什么不是通常用的make install,因为这里make install的作用是先安装gcc再安装codeviz,而前面已经安装了 gcc,所以这里只需要安装 codeviz ,即make install-codeviz脚本,该脚本也就是将genfull 和 gengraph 复制到/usr/local/bin 目录下。
目前为止,CodeViz 安装完成了。
可以不用分开装,直接make,make install也可以
三、基本实用方法
GraphViz 支持生成不同风格的调用图,但是一些需要安装额外的支持工具或者库程序,有兴趣的朋友可以到官网上查找相关资料。这里重点讲述 CodeViz 的使用方法,具体的图像风格控制不再详述。
CodeViz 使用两个脚本来生成调用图,一个是 genfull,该脚本可以生成项目的完整调用图,因此调用图可能很大很复杂,缺省使用 cdepn 文件来创建调用图;另一个是gengraph,该脚本可以对给定一组函数生成一个小的调用图,还可以生成对应的postscript 文件。安装时这两个脚本被复制到/usr/local/bin 目录下,所以可以直接使用而不需要指定路径。其基本步骤如下:
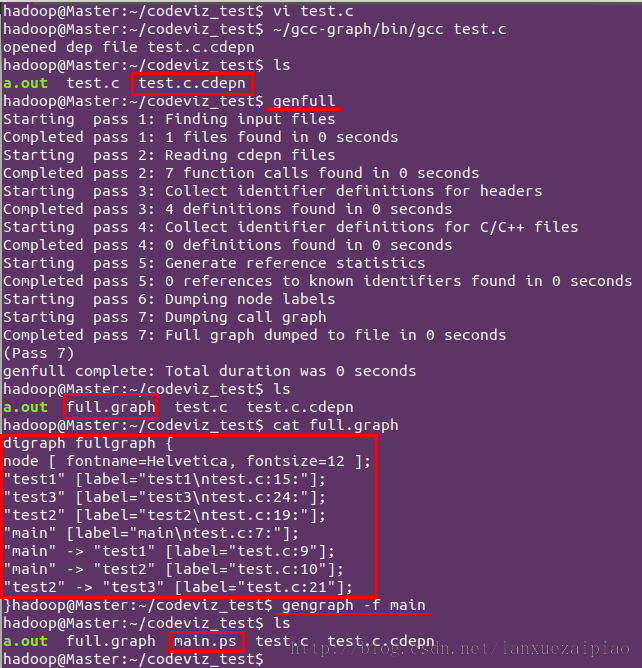
下面以编译一个简单的test.c文件为例进行说明:
1.使用刚刚安装的gcc-4.6.2来编译当前目录下所有.c文件,gcc/g++为编译的每个 C/C++文件生成.cdepn 文件。只要编译(参数 -c)就行,无需链接。
1
$ /usr/local/gccgraph/bin/gcc test.c
2.调用genful会在当前目录生成一个full.graph文件,该脚本可以生成项目的完整调用图信息文件,记录了所有函数在源码中的位置和它们之间的调用关系。 因此调用图信息文件可能很大很复杂,,缺省使用 cdepn 文件来创建调用图信息文件。
3.使用gengraph可以对给定一组函数生成一个小的调用图,显示函数调用关系。
四、简单示例演示
自己编写个简单的程序,看下效果再说~~~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// test.c
#include <stdio.h>
void test3()
{
}
void test2()
{
test3();
}
void test1()
{
}
int main()
{
test1();
test2();
return 0;
}
按照上面的三个步骤依次进行如下图所示:
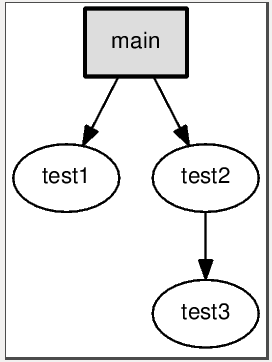
打开main.ps看到效果如下,一目了然:
五、进阶使用
当然大家使用CodeViz都不是用来玩的,而是用于真正的项目中,四中简单的使用根本不够,下面来点稍微高深点的。
1.先来分析下上面的执行流程
首先使用刚刚安装的gcc编译我们的.c文件(PS:这里一定要指定刚刚安装gcc的地方,否则用的是系统gcc而非我们安装的gcc),然后genfull创建full.graph文件,可以使用genfull --help或者genfull --man来查看如何使用。最简单的方式是在项目的顶级目录以无参数方式运行。由于项目的完全调用信息非常庞大,所以通常只是简单的生成项目的full.graph,然后在后面使用genfull获取需要的调用信息。若是需要完整信息则将full.graph由dot处理然后查看来生成的postscript文件。(dot是GraphViz中的一个工具,具体使用没有深究过,感兴趣的读者可以自行查阅~~~)。到test.c所在目录运行genfull看到生成了full.graph文件,大家可以用cat查看下。接下来使用gengraph生成函数调用图,可以使用gengraph --help或gengraph --man来查看如何使用。对于我而言,目前只关注下面几个选项就够了,即:
1
2
3
4
5
6
7
8
-f:指定顶级函数,即入口函数,如main等(当然不限定是main了);
-o:指定输出的postfile文件名,不指定的话就是函数名了,如上面的main;
--output-type:指定输出类型,例如png、gif、html和ps,缺省是ps,如上面的main.ps;
-d:指定最大调用层数;
-s:仅仅显示指定的函数,而不对其调用进行展开;
-i:忽略指定的函数
-t:忽略Linux特有的内核函数集;
-k:保留由-s忽略的内部细节形成的中间文件,为sub.graph
2.使用gengraph时的选项参数值要使用"“括起来,例如:
1
gengraph --output-type "png" -f main
3.命名冲突问题
在一个复杂的项目中,full.graph并不十分完美。例如,kernel中的模块有许多同名函数,这时genfull不能区分它们,有两种方法可以解决,其中第一种方法太复杂易错不推荐使用,这里就介绍下第二种方法,即使用genfull的-s选项,-s指定了检测哪些子目录。例如kernel中在mm目录和drivers/char/drm目录下都定义了alloc_pages函数,那么可以以下列方式调用genfull:
1
genfull -s "mm include/linux drivers/block arch/i386"
实际的使用中,-s非常方便,请大家记住这个选项。
4.使用Daemon/Client模式
当full.graph很大时,大量的时间花费到读取输入文件上了,例如kernel的full.graph是很大的,前面生成的大约有15M,这还不是全部内核的函数调用分析信息。为了节省时间,可以讲gengraph以daemon方式运行,这药使用-p选项:
1
gengraph -p -g linux-2.6.25/full.graph
该命令返回时gengraph以daemon方式运行,同时在/tmp目录下生成了codeviz.pipe文件。要生成函数调用图,可以使用-q选项:
1
gengraph -q -t -d 2 -f alloc_pages
要终止gengraph的运行,使用如下命令:
1
echo QUIT > /tmpcodeviz.pipe
六、进阶演示
以分析《嵌入式实时操作系统 uC/OS-II (第二版)》中的第一个范例程序为例,是什么程序不要紧,这里主要看的是如何使用及使用后的效果。
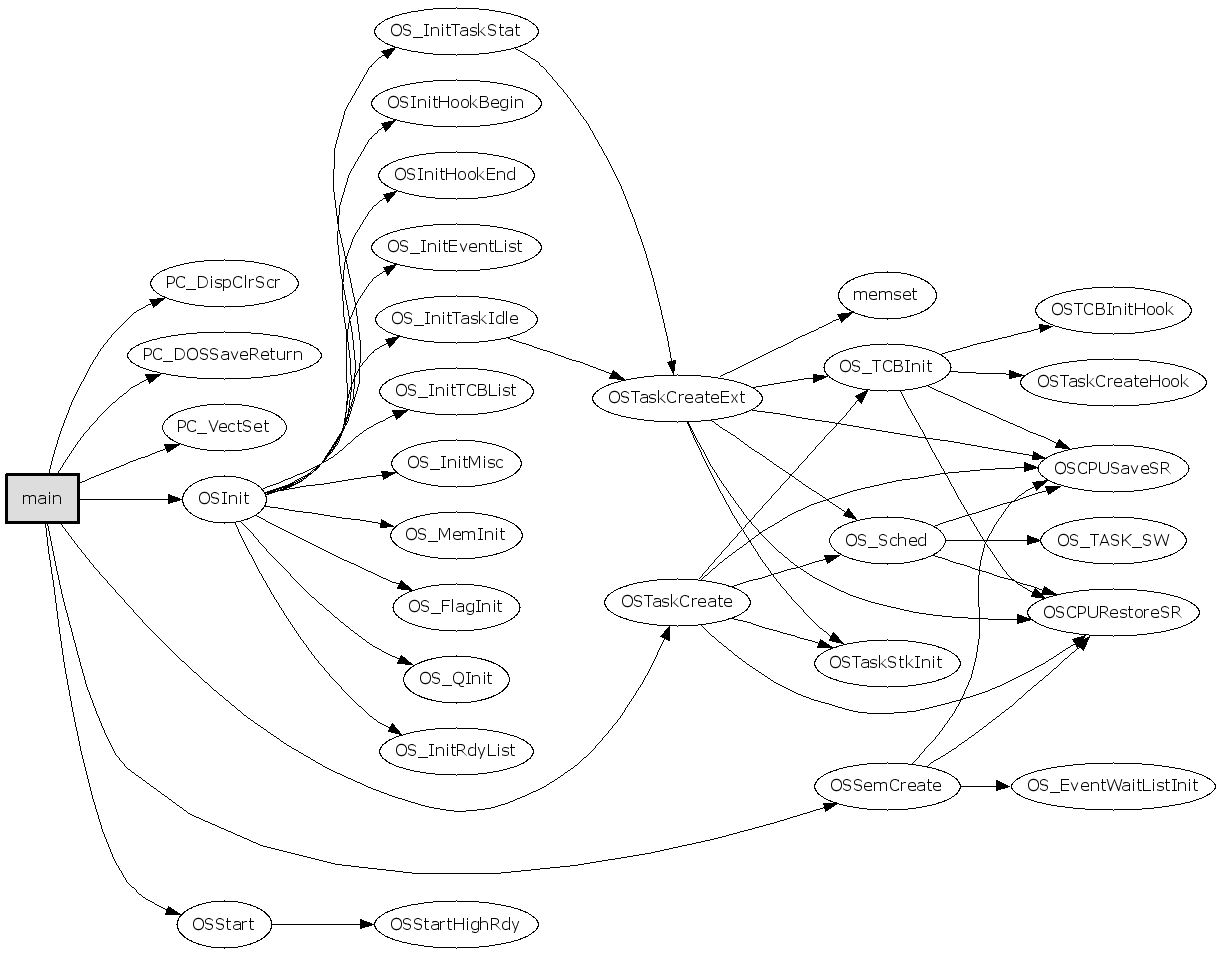
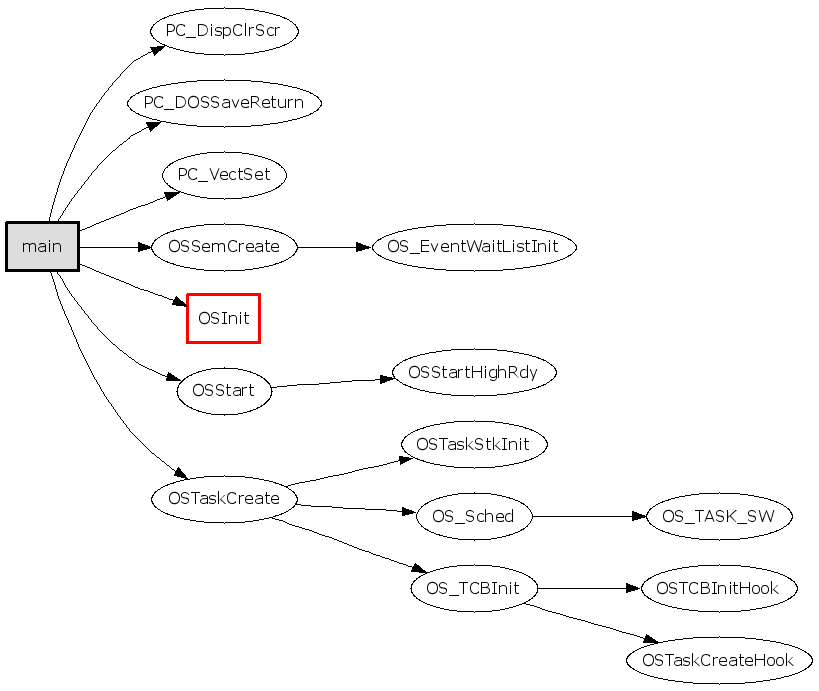
首先分析main():
1.
1
gengraph --output-type gif -f main
分析main()的call graph,得到的图如下,看不出要领:
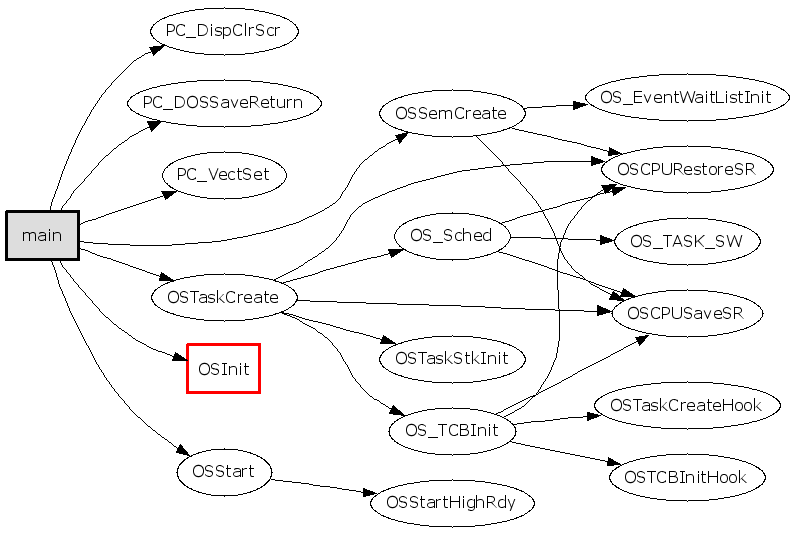
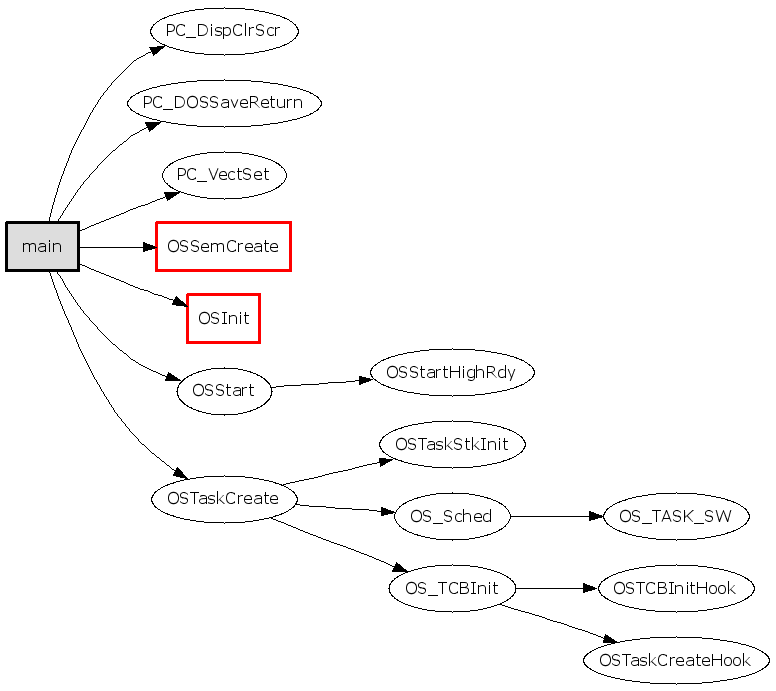
2.
1
gengraph --output-type gif -f main -s OSInit
暂时不关心OSInit()的内部实现细节(参数 -s),让它显示为一个节点。得到的图如下,有点乱,不过好多了:
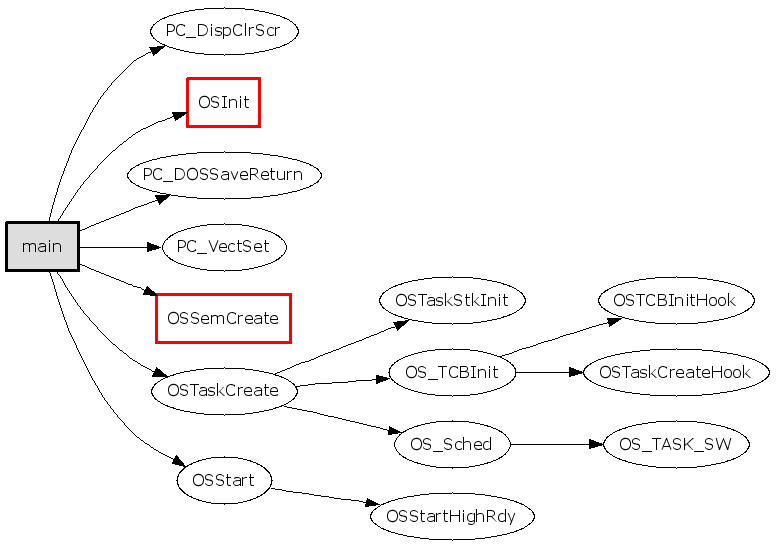
3.
1
gengraph --output-type gif -f main -s OSInit -i "OSCPUSaveSR;OSCPURestoreSR"
基本上每个函数都会有进入/退出临界区的代码,忽略之(参数 -i)。得到的图如下,基本清楚了:
4.
1
gengraph --output-type gif -f main -s "OSInit;OSSemCreate" -i "OSCPUSaveSR;OSCPURestoreSR" -k
OSSemCreate()的内部细节似乎也不用关心,不过保留中间文件sub.graph(参数 -k),得到的图如下,
5.
1
dot -Tgif -o main.gif sub.graph
修改sub.graph,使图形符合函数调用顺序,最后得到的图如下,有了这个都不用看代码了:)
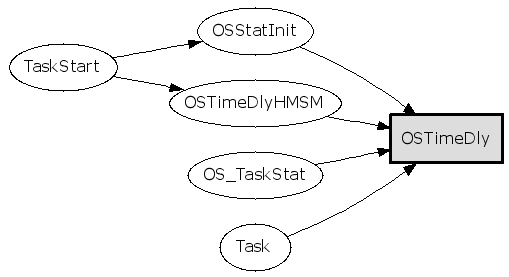
接着分析OSTimeDly()的被调用关系:
1
gengraph --output-type gif -r -f OSTimeDly
看看哪些函数调用了OSTimeDly(),参数 -r ,Task()和TaskStart()都是用户编写的函数:
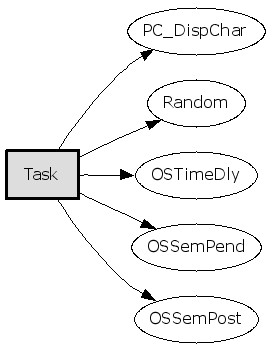
最后看看Task()直接调用了哪些函数:
1
gengraph --output-type gif -d 1 -f Task
只看从Task出发的第一层调用(参数 -d 1):
七、安装过程出现的错误及解决方案
1. 在运行./install_gcc-4.6.2.sh时出现下面错误:
1
gcc configure: error: Building GCC requires GMP 4.2+, MPFR 2.3.1+ and MPC 0.8.0+
从错误中可以看出:GCC编译需要GMP, MPFR, MPC这三个库(有的系统已经安装了就没有这个提示,我的没有安装),有两种安装方法(建议第二种):
(1)二进制源码安装(强烈不推荐)
我使用的版本为gmp-4.3.2,mpfr-2.4.2和mpc-0.8.1,在 ftp://gcc.gnu.org/pub/gcc/infrastructure/ 下载,根据提示的顺序分别安装GMP,MPFR和MPC(mpfr依赖gmp,mpc依赖gmp和mpfr),这里全部自己指定了安装目录,如果没有指定则默认分装在在/usr/include、/usr/lib和/usr/share,管理起来不方便,比如想卸载的时候还得一个个去找:
1
2
3
安装gmp: ./configure --prefix=/usr/local/gmp-4.3.2; make install
安装mpfr: ./configure --prefix=/usr/local/mpfr-2.4.2 --with-gmp=/usr/local/gmp-4.3.2/; make install
安装mpc: ./configure --prefix=/usr/local/mpc-0.8.1 --with-gmp=/usr/local/gmp-4.3.2/ --with-mpfr=/usr/local/mpfr-2.4.2/; make install
PS:安装过程中可能又出现新的错误提示,请看2、3、4条。
配置环境变量:我这里指定了安装位置,如果没有指定则这几个库的默认位置是/usr/local/include和/usr/local/lib,不管有没有指定GCC编译时都可能会找不到这三个库,需要确认库位置是否在环境变量LD_LIBRARY_PATH中,查看环境变量内容可以用命令
$echo $LD_LIBRARY_PATH
设置该环境变量命令如下:
1
2
3
指定安装:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/gmp-4.3.2/lib:/usr/local/mpfr-2.4.2/lib:/usr/local/mpc-0.8.1/lib
默认安装:$export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/lib
PS:十分不推荐这种安装方法,一般来说这样的确可以成功安装,但是也不排除安装过程中又出现新的问题,具体看问题5。
(2)gcc自带脚本安装(强烈推荐)
方法(1)的安装方法十分繁琐,安装过程中可能出现各种预料不到的新错误,因此gcc源码包中自带了一个gcc依赖库安装脚本download_prerequisites,位置在gcc源码目录中的contrib/download_prerequisites,因此只需要进入该目录,直接运行脚本安装即可:./download_prerequisites
PS:该脚本内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#!/bin/sh
# Download some prerequisites needed by gcc.
# Run this from the top level of the gcc source tree and the gcc
# build will do the right thing.
#
# (C) 2010 Free Software Foundation
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see http://www.gnu.org/licenses/.
MPFR=mpfr-2.4.2
GMP=gmp-4.3.2
MPC=mpc-0.8.1
wget ftp://gcc.gnu.org/pub/gcc/infrastructure/$MPFR.tar.bz2 || exit 1
tar xjf $MPFR.tar.bz2 || exit 1
ln -sf $MPFR mpfr || exit 1
wget ftp://gcc.gnu.org/pub/gcc/infrastructure/$GMP.tar.bz2 || exit 1
tar xjf $GMP.tar.bz2 || exit 1
ln -sf $GMP gmp || exit 1
wget ftp://gcc.gnu.org/pub/gcc/infrastructure/$MPC.tar.gz || exit 1
tar xzf $MPC.tar.gz || exit 1
ln -sf $MPC mpc || exit 1
rm $MPFR.tar.bz2 $GMP.tar.bz2 $MPC.tar.gz || exit 1
可见是通过wget的方式下载安装,因此如果没有安装wget则需要先安装下。
大家仔细看下这个脚本,发现非常简单,就是从网上自动下载三个依赖库并解压,然后建立三个改名后的软链接分别指向这三个库,这里建立软链接过程中也可能出错,具体看问题6,大家也可以自己修改脚本,改成直接修改名称然后移到gcc目录下。
技巧:从这里也可以看出,gcc所依赖的库其实只要解压了放在gcc当前目录下就行了,方法(1)的那么多步骤其实都可以省掉,直接将下载的三个压缩包解压后改名移到gcc下面即可,也不用设置环境变量了。
2. 编译gmp时出现错误:
No usable m4 in $PATH or /usr/5bin (see config.log for reasons).
由此可以看出是缺少M4文件。可以去这里下载:http://ftp.gnu.org/gnu/m4/ 然后编译安装,我由于是Ubuntu系统,就直接安装了。
1
sudo apt-get install m4
3. 安装mpfr时出现错误:
configure: error: gmp.h can’t be found, or is unusable.
这是因为在安装mpfr时未先安装gmp导致的,mpfr依赖于gmp。
4. 安装mpc时出现错误:
configure: error: libgmp not found or uses a different ABI.和configure: error: libmpfr not found or uses a different ABI.“。
同样是因为未安装mpc依赖的库gmp和mpfr。
5. 在运行./install_gcc-4.6.2.sh过程中出现错误,即按照gcc过程中出现的问题:
(1)libmpfr.so.1: cannot open shared object file: No such file or directory
分析:该脚本就是安装gcc,但是如果你出现了问题1,并且使用方法(1)解决该问题,那么你后期就可能出现这样的问题,当然你运气没那么背的话一般不会出现这样的问题,反正我运行比较背,出现了这样的问题。
解决方法:可以参考这篇文章 http://blog.csdn.net/leo115/article/details/7671819 解决。
(2)../../gcc-4.6.2/gcc/realmpfr.h:27:17: fatal error: mpc.h: No such file or directory
分析:gcc没找到所依赖的库mpc,原因很多,最有可能是你没设置环境变量或mpc放的地方不对。
解决方法:设置环境变量,看问题1。
(3) /usr/include/stdc-predef.h:30:26: fatal error: bits/predefs.h: No such file or directory
分析:用命令"locate bits/predefs.h"下该头文件的路径,发现是在'/usr/include/x86_64-linux-gnu'
解决方法:设置环境变量:
1
#export C_INCLUDE_PATH=/usr/include/i386-linux-gnu && export CPLUS_INCLUDE_PATH=$C_INCLUDE_PATH
(4) /usr/bin/ld: cannot find crti.o: No such file or directory
分析:同样用"locate crti.o" 找下这个文件,在'/usr/lib/i386-linux-gnu/crti.o'。
解决方法:设置LIBRARY_PATH (LDFLAGS)这个环境变量如下:
1
#export LIBRARY_PATH=/usr/lib/i386-linux-gnu
(5)unwind-dw2.c:1031: error: field `info' has incomplete type
分析:这个错误搞了好久,因为网上找不到对应的解决方法,只说这是gcc的一个bug。
解决方法:深入到源文件中,发现错误的地方是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static _Unwind_Reason_Code
uw_frame_state_for (struct _Unwind_Context *context, _Unwind_FrameState *fs)
{
struct dwarf_fde *fde;
struct dwarf_cie *cie;
const unsigned char *aug, *insn, *end;
memset (fs, 0, sizeof (*fs));
context->args_size = 0;
context->lsda = 0;
fde = _Unwind_Find_FDE (context->ra - 1, &context->bases); //这里返回了NULL
if (fde == NULL)
{
/* Couldn't find frame unwind info for this function. Try a
* target-specific fallback mechanism. This will necessarily
* not profide a personality routine or LSDA. */
#ifdef MD_FALLBACK_FRAME_STATE_FOR
MD_FALLBACK_FRAME_STATE_FOR (context, fs, success); // 出错的地方
return _URC_END_OF_STACK;
success:
return _URC_NO_REASON;
#else
return _URC_END_OF_STACK; //出错返回
#endif
}
.....
}
出错的地方用标注了,因为fde返回了NULL,导致不能找到frame unwind info,最重要的是下面这个方法
1
MD_FALLBACK_FRAME_STATE_FOR (context, fs, success);
出错了,为什么返回NULL我肯定研究不出来,只知道这个函数调用失败了,导致不成功,于是我的解决方法十分偷懒,就是将下面的两行注释掉了,直接success,哈哈,勿喷我,因为这样做过后就解决了,后面一路成功~~~
1
2
// MD_FALLBACK_FRAME_STATE_FOR (context, fs, success); // 出错的地方
// return _URC_END_OF_STACK;
解决ln -s 软链接产生Too many levels of symbolic links错误
从网上查找了一下原因,原来是建立软连接的时候采用的是相对路径,所以才会产生这样的错误,解决方式是采用绝对路径建立软链接:这样问题就解决了。
八、小结
本文查阅了网上的许多资料比较详细的讲解了CodeViz的安装和使用。CodeViz依赖于GraphViz,因而可以生成十分丰富的函数调用图。具体选项的使用及图像格式的选择可由读者根据个人需要和偏好自己揣摩使用。在分析源码的时候,把这些图形打印在手边,在上面做笔记,实在方便收益颇多。
九、参考资料:
http://blog.csdn.net/delphiwcdj/article/details/9936717
http://www.cppblog.com/hacrwang/archive/2007/06/30/27296.html
http://www.cnblogs.com/xuxm2007/archive/2010/10/14/1851086.html