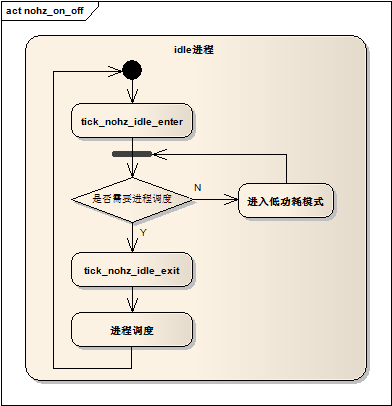
static void tick_nohz_restart(struct tick_sched *ts, ktime_t now)
{
hrtimer_cancel(&ts->sched_timer);
hrtimer_set_expires(&ts->sched_timer, ts->idle_tick);
while (1) {
/* Forward the time to expire in the future */
hrtimer_forward(&ts->sched_timer, now, tick_period);
if (ts->nohz_mode == NOHZ_MODE_HIGHRES) {
hrtimer_start_expires(&ts->sched_timer,
HRTIMER_MODE_ABS_PINNED);
/* Check, if the timer was already in the past */
if (hrtimer_active(&ts->sched_timer))
break;
} else {
if (!tick_program_event(
hrtimer_get_expires(&ts->sched_timer), 0))
break;
}
/* Reread time and update jiffies */
now = ktime_get();
tick_do_update_jiffies64(now);
}
}
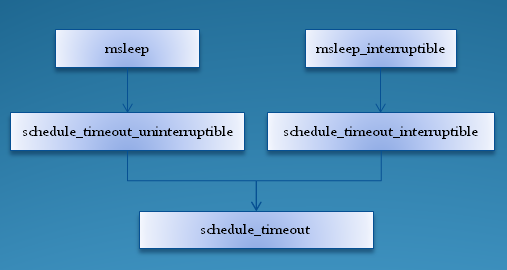
signed long __sched schedule_timeout_uninterruptible(signed long timeout)
{
__set_current_state(TASK_UNINTERRUPTIBLE);
return schedule_timeout(timeout);
}
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
signed long __sched schedule_timeout_interruptible(signed long timeout)
{
__set_current_state(TASK_INTERRUPTIBLE);
return schedule_timeout(timeout);
}
unsigned long msleep_interruptible(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout && !signal_pending(current))
timeout = schedule_timeout_interruptible(timeout);
return jiffies_to_msecs(timeout);
}
int __hrtimer_start_range_ns(struct hrtimer *timer, ktime_t tim,
unsigned long delta_ns, const enum hrtimer_mode mode,
int wakeup)
{
......
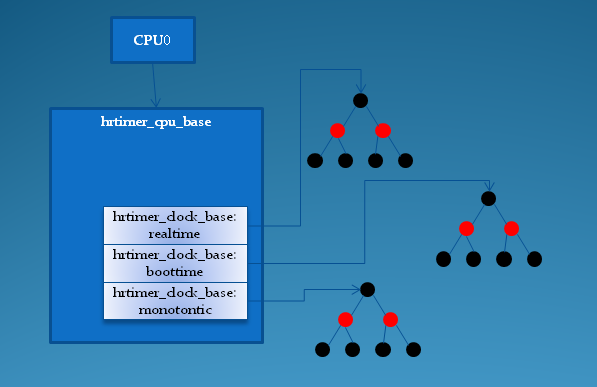
/* 取得hrtimer_clock_base指针 */
base = lock_hrtimer_base(timer, &flags);
/* 如果已经在红黑树中,先移除它: */
ret = remove_hrtimer(timer, base); ......
/* 如果是相对时间,则需要加上当前时间,因为内部是使用绝对时间 */
if (mode & HRTIMER_MODE_REL) {
tim = ktime_add_safe(tim, new_base->get_time());
......
}
/* 设置到期的时间范围 */
hrtimer_set_expires_range_ns(timer, tim, delta_ns);
......
/* 把hrtime按到期时间排序,加入到对应时间基准系统的红黑树中 */
/* 如果该定时器的是最早到期的,将会返回true */
leftmost = enqueue_hrtimer(timer, new_base);
/*
* Only allow reprogramming if the new base is on this CPU.
* (it might still be on another CPU if the timer was pending)
*
* XXX send_remote_softirq() ?
* 定时器比之前的到期时间要早,所以需要重新对tick_device进行编程,重新设定的的到期时间
*/
if (leftmost && new_base->cpu_base == &__get_cpu_var(hrtimer_bases))
hrtimer_enqueue_reprogram(timer, new_base, wakeup);
unlock_hrtimer_base(timer, &flags);
return ret;
}
void hrtimer_interrupt(struct clock_event_device *dev)
{
......
for (i = 0; i < HRTIMER_MAX_CLOCK_BASES; i++) {
......
while ((node = timerqueue_getnext(&base->active))) {
......
if (basenow.tv64 < hrtimer_get_softexpires_tv64(timer)) {
ktime_t expires;
expires = ktime_sub(hrtimer_get_expires(timer),
base->offset);
if (expires.tv64 < expires_next.tv64)
expires_next = expires;
break;
}
__run_hrtimer(timer, &basenow);
}
}
/*
* Store the new expiry value so the migration code can verify
* against it.
*/
cpu_base->expires_next = expires_next;
raw_spin_unlock(&cpu_base->lock);
/* Reprogramming necessary ? */
if (expires_next.tv64 == KTIME_MAX ||
!tick_program_event(expires_next, 0)) {
cpu_base->hang_detected = 0;
return;
}
如果这时的tick_program_event返回了非0值,表示过期时间已经在当前时间的前面,这通常由以下原因造成:
系统正在被调试跟踪,导致时间在走,程序不走;
定时器的回调函数花了太长的时间;
系统运行在虚拟机中,而虚拟机被调度导致停止运行;
为了避免这些情况的发生,接下来系统提供3次机会,重新执行前面的循环,处理到期的定时器:
raw_spin_lock(&cpu_base->lock);
now = hrtimer_update_base(cpu_base);
cpu_base->nr_retries++;
if (++retries < 3)
goto retry;
如果3次循环后还无法完成到期处理,系统不再循环,转为计算本次总循环的时间,
然后把tick_device的到期时间强制设置为当前时间加上本次的总循环时间,不过推后的时间被限制在100ms以内:
delta = ktime_sub(now, entry_time);
if (delta.tv64 > cpu_base->max_hang_time.tv64)
cpu_base->max_hang_time = delta;
/*
* Limit it to a sensible value as we enforce a longer
* delay. Give the CPU at least 100ms to catch up.
*/
if (delta.tv64 > 100 * NSEC_PER_MSEC)
expires_next = ktime_add_ns(now, 100 * NSEC_PER_MSEC);
else
expires_next = ktime_add(now, delta);
tick_program_event(expires_next, 1);
printk_once(KERN_WARNING "hrtimer: interrupt took %llu ns\n",
ktime_to_ns(delta));
}
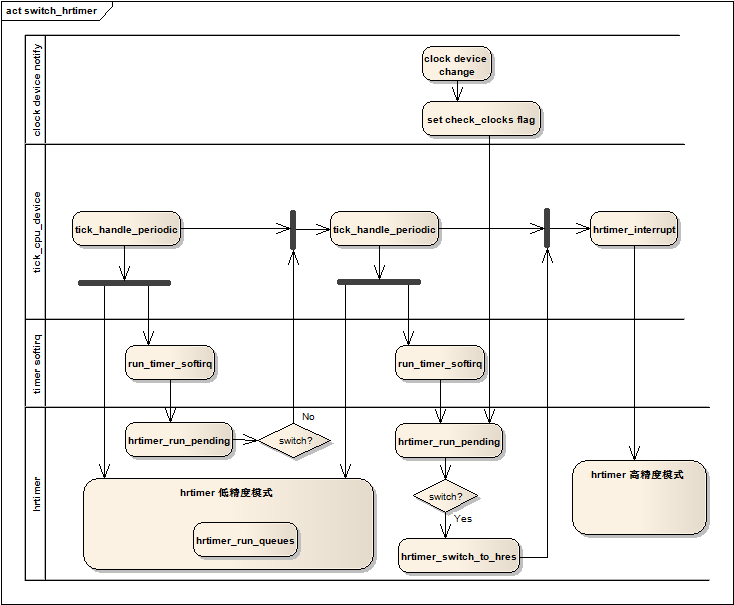
static int hrtimer_switch_to_hres(void)
{
int i, cpu = smp_processor_id();
struct hrtimer_cpu_base *base = &per_cpu(hrtimer_bases, cpu);
unsigned long flags;
if (base->hres_active)
return 1;
接着,通过tick_init_highres函数接管tick_device关联的clock_event_device:
local_irq_save(flags);
if (tick_init_highres()) {
local_irq_restore(flags);
printk(KERN_WARNING "Could not switch to high resolution "
"mode on CPU %d\n", cpu);
return 0;
}
void tick_setup_sched_timer(void)
{
struct tick_sched *ts = &__get_cpu_var(tick_cpu_sched);
ktime_t now = ktime_get();
/*
* Emulate tick processing via per-CPU hrtimers:
*/
hrtimer_init(&ts->sched_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);
ts->sched_timer.function = tick_sched_timer;
/* Get the next period (per cpu) */
hrtimer_set_expires(&ts->sched_timer, tick_init_jiffy_update());
for (;;) {
hrtimer_forward(&ts->sched_timer, now, tick_period);
hrtimer_start_expires(&ts->sched_timer,
HRTIMER_MODE_ABS_PINNED);
/* Check, if the timer was already in the past */
if (hrtimer_active(&ts->sched_timer))
break;
now = ktime_get();
}
#ifdef CONFIG_NO_HZ
if (tick_nohz_enabled)
ts->nohz_mode = NOHZ_MODE_HIGHRES;
#endif
}