struct timer_list {
/*
* All fields that change during normal runtime grouped to the
* same cacheline
*/
struct list_head entry;
unsigned long expires;
struct tvec_base *base;
void (*function)(unsigned long);
unsigned long data;
int slack;
......
};
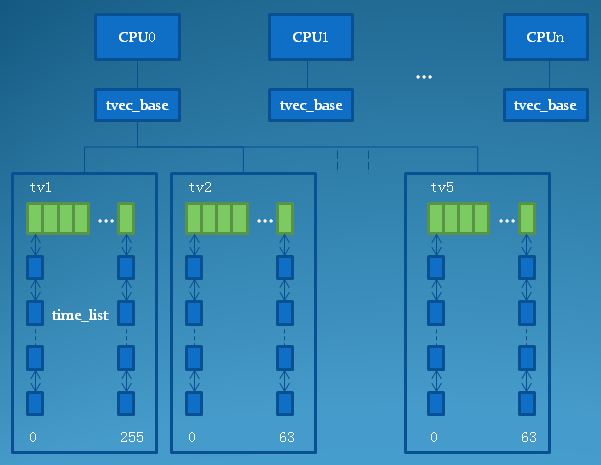
entry 字段用于把一组定时器组成一个链表,至于内核如何对定时器进行分组,我们会在后面进行解释。
expires 字段指出了该定时器的到期时刻,也就是期望定时器到期时刻的jiffies计数值。
base 每个cpu拥有一个自己的用于管理定时器的tvec_base结构,该字段指向该定时器所属的cpu所对应tvec_base结构。
function 字段是一个函数指针,定时器到期时,系统将会调用该回调函数,用于响应该定时器的到期事件。
data 该字段用于上述回调函数的参数。
slack 对有些对到期时间精度不太敏感的定时器,到期时刻允许适当地延迟一小段时间,该字段用于计算每次延迟的HZ数。
static int cascade(struct tvec_base *base, struct tvec *tv, int index)
{
/* cascade all the timers from tv up one level */
struct timer_list *timer, *tmp;
struct list_head tv_list;
list_replace_init(tv->vec + index, &tv_list); // 移除需要迁移的链表
/*
* We are removing _all_ timers from the list, so we
* don't have to detach them individually.
*/
list_for_each_entry_safe(timer, tmp, &tv_list, entry) {
BUG_ON(tbase_get_base(timer->base) != base);
// 重新加入到定时器系统中,实际上将会迁移到下一级的tv数组中
internal_add_timer(base, timer);
}
return index;
}
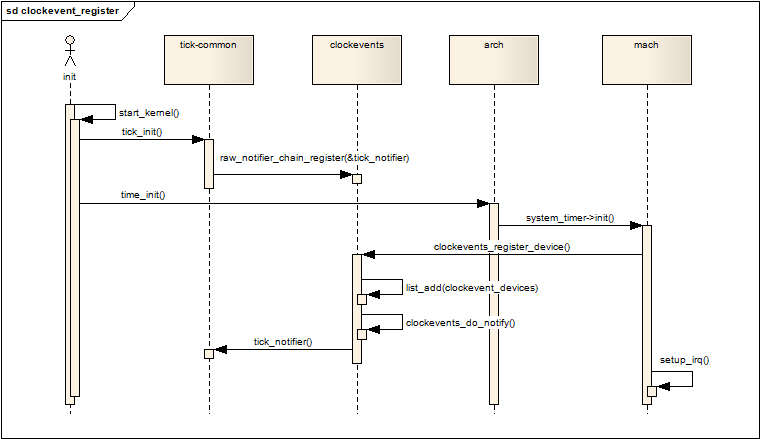
static int tick_notify(struct notifier_block *nb, unsigned long reason,
void *dev)
{
switch (reason) {
case CLOCK_EVT_NOTIFY_ADD:
return tick_check_new_device(dev);
case CLOCK_EVT_NOTIFY_BROADCAST_ON:
case CLOCK_EVT_NOTIFY_BROADCAST_OFF:
case CLOCK_EVT_NOTIFY_BROADCAST_FORCE:
......
case CLOCK_EVT_NOTIFY_BROADCAST_ENTER:
case CLOCK_EVT_NOTIFY_BROADCAST_EXIT:
......
case CLOCK_EVT_NOTIFY_CPU_DYING:
......
case CLOCK_EVT_NOTIFY_CPU_DEAD:
......
case CLOCK_EVT_NOTIFY_SUSPEND:
......
case CLOCK_EVT_NOTIFY_RESUME:
......
}
return NOTIFY_OK;
}
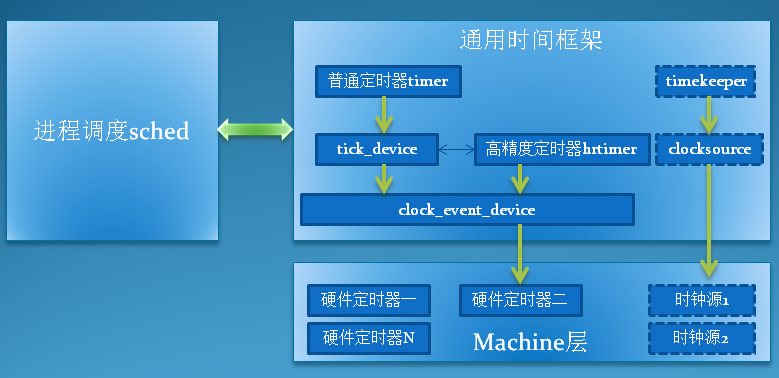
void tick_handle_periodic(struct clock_event_device *dev)
{
int cpu = smp_processor_id();
ktime_t next;
tick_periodic(cpu);
if (dev->mode != CLOCK_EVT_MODE_ONESHOT)
return;
next = ktime_add(dev->next_event, tick_period);
for (;;) {
if (!clockevents_program_event(dev, next, false))
return;
if (timekeeping_valid_for_hres())
tick_periodic(cpu);
next = ktime_add(next, tick_period);
}
}
monotonic time 该时间自系统开机后就一直单调地增加,它不像xtime可以因用户的调整时间而产生跳变,不过该时间不计算系统休眠的时间,也就是说,系统休眠时,monotoic时间不会递增。
raw monotonic time 该时间与monotonic时间类似,也是单调递增的时间,唯一的不同是:raw monotonic time“更纯净”,他不会受到NTP时间调整的影响,它代表着系统独立时钟硬件对时间的统计。
boot time 与monotonic时间相同,不过会累加上系统休眠的时间,它代表着系统上电后的总时间。
123456
时间种 类 精度(统计单位) 访问速度 累计休眠时间 受NTP调整的影响
RTC 低 慢 Yes Yes
xtime 高 快 Yes Yes
monotonic 高 快 No Yes
raw monotonic 高 快 No No
boot time 高 快 Yes Yes
2. struct timekeeper
内核用timekeeper结构来组织与时间相关的数据,它的定义如下:
1234567891011121314151617181920212223242526272829
struct timekeeper {
struct clocksource *clock; /* Current clocksource used for timekeeping. */
u32 mult; /* NTP adjusted clock multiplier */
int shift; /* The shift value of the current clocksource. */
cycle_t cycle_interval; /* Number of clock cycles in one NTP interval. */
u64 xtime_interval; /* Number of clock shifted nano seconds in one NTP interval. */
s64 xtime_remainder; /* shifted nano seconds left over when rounding cycle_interval */
u32 raw_interval; /* Raw nano seconds accumulated per NTP interval. */
u64 xtime_nsec; /* Clock shifted nano seconds remainder not stored in xtime.tv_nsec. */
/* Difference between accumulated time and NTP time in ntp
* shifted nano seconds. */
s64 ntp_error;
/* Shift conversion between clock shifted nano seconds and
* ntp shifted nano seconds. */
int ntp_error_shift;
struct timespec xtime; /* The current time */
struct timespec wall_to_monotonic;
struct timespec total_sleep_time; /* time spent in suspend */
struct timespec raw_time; /* The raw monotonic time for the CLOCK_MONOTONIC_RAW posix clock. */
ktime_t offs_real; /* Offset clock monotonic -> clock realtime */
ktime_t offs_boot; /* Offset clock monotonic -> clock boottime */
seqlock_t lock; /* Seqlock for all timekeeper values */
};