python dict 是指针
1 2 3 4 5 6 7 8 9 | |
utf8
1
| |
时间戳、int互转
1 2 | |


1 2 3 4 5 6 7 8 9 | |
1
| |
1 2 | |
http://blog.csdn.net/DroidPhone/article/details/8112948
在前面章节的讨论中,我们一直基于一个假设:Linux中的时钟事件都是由一个周期时钟提供,不管系统中的clock_event_device是工作于周期触发模式,还是工作于单触发模式,也不管定时器系统是工作于低分辨率模式,还是高精度模式,内核都竭尽所能,用不同的方式提供周期时钟,以产生定期的tick事件,tick事件或者用于全局的时间管理(jiffies和时间的更新),或者用于本地cpu的进程统计、时间轮定时器框架等等。周期性时钟虽然简单有效,但是也带来了一些缺点,尤其在系统的功耗上,因为就算系统目前无事可做,也必须定期地发出时钟事件,激活系统。为此,内核的开发者提出了动态时钟这一概念,我们可以通过内核的配置项CONFIG_NO_HZ来激活特性。有时候这一特性也被叫做tickless,不过还是把它称呼为动态时钟比较合适,因为并不是真的没有tick事件了,只是在系统无事所做的idle阶段,我们可以通过停止周期时钟来达到降低系统功耗的目的,只要有进程处于活动状态,时钟事件依然会被周期性地发出。
在动态时钟正确工作之前,系统需要切换至动态时钟模式,而要切换至动态时钟模式,需要一些前提条件,最主要的一条就是cpu的时钟事件设备必须要支持单触发模式,当条件满足时,系统切换至动态时钟模式,接着,由idle进程决定是否可以停止周期时钟,退出idle进程时则需要恢复周期时钟。
在上一章的内容里,我们曾经提到,切换到高精度模式后,高精度定时器系统需要使用一个高精度定时器来模拟传统的周期时钟,其中利用了tick_sched结构中的一些字段,事实上,tick_sched结构也是实现动态时钟的一个重要的数据结构,在smp系统中,内核会为每个cpu都定义一个tick_sched结构,这通过一个percpu全局变量tick_cpu_sched来实现,它在kernel/time/tick-sched.c中定义:
1 2 3 4 | |
tick_sched结构在include/linux/tick.h中定义,我们看看tick_sched结构的详细定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
sched_timer 该字段用于在高精度模式下,模拟周期时钟的一个hrtimer,请参看Linux时间子系统之六:高精度定时器(HRTIMER)的原理和实现。
check_clocks 该字段用于实现clock_event_device和clocksource的异步通知机制,帮助系统切换至高精度模式或者是动态时钟模式。
nohz_mode 保存动态时钟的工作模式,基于低分辨率和高精度模式下,动态时钟的实现稍有不同,根据模式它可以是以下的值:
NOHZ_MODE_INACTIVE 系统动态时钟尚未激活
NOHZ_MODE_LOWRES 系统工作于低分辨率模式下的动态时钟
NOHZ_MODE_HIGHRES 系统工作于高精度模式下的动态时钟
idle_tick 该字段用于保存停止周期时钟是的内核时间,当退出idle时要恢复周期时钟,需要使用该时间,以保持系统中时间线(jiffies)的正确性。
tick_stopped 该字段用于表明idle状态的周期时钟已经停止。
idle_jiffies 系统进入idle时的jiffies值,用于信息统计。
idle_calls 系统进入idle的统计次数。
idle_sleeps 系统进入idle且成功停掉周期时钟的次数。
idle_active 表明目前系统是否处于idle状态中。
idle_entrytime 系统进入idle的时刻。
idle_waketime idle状态被打断的时刻。
idle_exittime 系统退出idle的时刻。
idle_sleeptime 累计各次idle中停止周期时钟的总时间。
sleep_length 本次idle中停止周期时钟的时间。
last_jiffies 系统中最后一次周期时钟的jiffies值。
next_jiffies 预计下一次周期时钟的jiffies。
idle_expires 进入idle后,下一个最先到期的定时器时刻。
我们知道,根据系统目前的工作模式,系统提供周期时钟(tick)的方式会有所不同,当处于低分辨率模式时,由cpu的tick_device提供周期时钟,而当处于高精度模式时,是由一个高精度定时器来提供周期时钟,下面我们分别讨论一下在两种模式下的动态时钟实现方式。
回看之前一篇文章:Linux时间子系统之四:定时器的引擎:clock_event_device中的关于tick_device一节,不管tick_device的工作模式(周期触发或者是单次触发),tick_device所关联的clock_event_device的事件回调处理函数都是:tick_handle_periodic,不管当前是否处于idle状态,他都会精确地按HZ数来提供周期性的tick事件,这不符合动态时钟的要求,所以,要使动态时钟发挥作用,系统首先要切换至支持动态时钟的工作模式:NOHZ_MODE_LOWRES 。
动态时钟模式的切换过程的前半部分和切换至高精度定时器模式所经过的路径是一样的,请参考:Linux时间子系统之六:高精度定时器(HRTIMER)的原理和实现。这里再简单描述一下过程:系统工作于周期时钟模式,定期地发出tick事件中断,tick事件中断触发定时器软中断:TIMER_SOFTIRQ,执行软中断处理函数run_timer_softirq,run_timer_softirq调用hrtimer_run_pending函数:
1 2 3 4 5 6 7 8 | |
tick_check_oneshot_change函数的参数决定了现在是要切换至低分辨率动态时钟模式,还是高精度定时器模式,我们现在假设系统不支持高精度定时器模式,hrtimer_is_hres_enabled会直接返回false,对应的tick_check_oneshot_change函数的参数则是true,表明需要切换至动态时钟模式。tick_check_oneshot_change在检查过timekeeper和clock_event_device都具备动态时钟的条件后,通过tick_nohz_switch_to_nohz函数切换至动态时钟模式:
首先,该函数通过tick_switch_to_oneshot函数把tick_device的工作模式设置为单触发模式,并把它的中断事件回调函数置换为tick_nohz_handler,接着把tick_sched结构中的模式字段设置为NOHZ_MODE_LOWRES:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
上面的代码中,明明现在没有切换至高精度模式,为什么要初始化tick_sched结构中的高精度定时器?原因并不是要使用它的定时功能,而是想重用hrtimer代码中的hrtimer_forward函数,利用这个函数来计算下一次tick事件的时间。
上一节提到,当切换至低分辨率动态时钟模式后,tick_device的事件中断处理函数会被设置为tick_nohz_handler,总体来说,它和周期时钟模式的事件处理函数tick_handle_periodic所完成的工作大致类似:更新时间、更新jiffies计数值、调用update_process_time更新进程信息和触发定时器软中断等等,最后重新编程tick_device,使得它在下一个正确的tick时刻再次触发本函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
因为现在工作于动态时钟模式,所以,tick时钟可能在idle进程中被停掉不止一个tick周期,所以当该函数被再次触发时,离上一次触发的时间可能已经不止一个tick周期,tick_nohz_reprogram对tick_device进行编程时必须正确地处理这一情况,它利用了前面所说的hrtimer_forward函数来实现这一特性:
1 2 3 4 5 | |
开启动态时钟模式后,周期时钟的开启和关闭由idle进程控制,idle进程内最终是一个循环,循环的一开始通过tick_nohz_idle_enter检测是否允许关闭周期时钟若干时间,然后进入低功耗的idle模式,当有中断事件使得cpu退出低功耗idle模式后,判断是否有新的进程被激活从而需要重新调度,如果需要则通过tick_nohz_idle_exit重新启用周期时钟,然后重新进行进程调度,等待下一次idle的发生,我们可以用下图来表示:
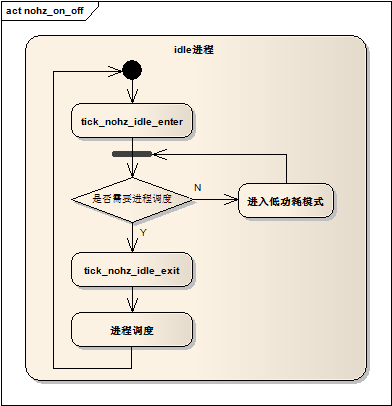
图2.3.1 idle进程中的动态时钟处理
停止周期时钟的时机在tick_nohz_idle_enter函数中,它把主要的工作交由tick_nohz_stop_sched_tick函数来完成。内核也不是每次进入tick_nohz_stop_sched_tick都会停止周期时钟,那么什么时候才会停止?我们想一想,这时候既然idle进程在运行,说明系统中的其他进程都在等待某种事件,系统处于无事所做的状态,唯一要处理的就是中断,除了定时器中断,其它的中断我们无法预测它会何时发生,但是我们可以知道最先一个到期的定时器的到期时间,也就是说,在该时间到期前,产生周期时钟是没有必要的,我们可以据此推算出周期时钟可以停止的tick数,然后重新对tick_device进行编程,使得在最早一个定时器到期前都不会产生周期时钟,实际上,tick_nohz_stop_sched_tick还做了一些限制:当下一个定时器的到期时间与当前jiffies值只相差1时,不会停止周期时钟,当定时器的到期时间与当前的jiffies值相差的时间大于timekeeper允许的最大idle时间时,则下一个tick时刻被设置timekeeper允许的最大idle时间,这主要是为了防止太长时间不去更新timekeeper中的系统时间,有可能导致clocksource的溢出问题。tick_nohz_stop_sched_tick函数体看起来很长,实现的也就是上述的逻辑,所以这里就不贴它的代码了,有兴趣的读者可以自行阅读内核的代码:kernel/time/tick-sched.c。
看了动态时钟的停止过程和tick_nohz_handler的实现方式,其实还有一个情况没有处理:当系统进入idle进程后,周期时钟被停止若干个tick周期,当这若干个tick周期到期后,tick事件必然会产生,tick_nohz_handler被触发调用,然后最先到期的定时器被处理。但是在tick_nohz_handler的最后,tick_device一定会被编程为紧跟着的下一个tick周期的时刻被触发,如果刚才的定时器处理后,并没有激活新的进程,我们的期望是周期时钟可以用下一个新的定时器重新计算可以停止的时间,而不是下一个tick时刻,但是tick_nohz_handler却仅仅简单地把tick_device的到期时间设为下一个周期的tick时刻,这导致了周期时钟被恢复,显然这不是我们想要的。为了处理这种情况,内核使用了一点小伎俩,我们知道定时器是在软中断中执行的,所以内核在irq_exit中的软件中断处理完后,加入了一小段代码,kernel/softirq.c :
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
关键的调用是tick_nohz_irq_exit:
1 2 3 4 5 6 7 8 9 | |
tick_nohz_irq_exit再次调用了tick_nohz_stop_sched_tick函数,使得系统有机会再次停止周期时钟若干个tick周期。
回到图2.3.1,当在idle进程中停止周期时钟后,在某一时刻,有新的进程被激活,在重新调度前,tick_nohz_idle_exit会被调用,该函数负责恢复被停止的周期时钟。tick_nohz_idle_exit最终会调用tick_nohz_restart函数,由tick_nohz_restart函数最后完成恢复周期时钟的工作。函数并不复杂:先是把上一次停止周期时钟的时刻设置到tick_sched结构的sched_timer定时器中,然后在通过hrtimer_forward函数把该定时器的到期时刻设置为当前时间的下一个tick时刻,对于高精度模式,启动该定时器即可,对于低分辨率模式,使用该时间对tick_device重新编程,最后通过tick_do_update_jiffies64更新jiffies数值,为了防止此时正在一个tick时刻的边界,可能当前时刻正好刚刚越过了该到期时间,函数使用了一个while循环:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
高精度模式和低分辨率模式的主要区别是在切换过程中,怎样切换到高精度模式,我已经在上一篇文章中做了说明,切换到高精度模式后,动态时钟的开启和关闭和低分辨率模式下没有太大的区别,也是通过tick_nohz_stop_sched_tick和tick_nohz_restart来控制,在这两个函数中,分别判断了当前的两种模式:
NOHZ_MODE_HIGHRES
NOHZ_MODE_LOWRES
如果是NOHZ_MODE_HIGHRES则对tick_sched结构的sched_timer定时器进行设置,如果是NOHZ_MODE_LOWRES,则直接对tick_device进行操作。
在进入和退出中断时,因为动态时钟的关系,中断系统需要作出一些配合。先说中断发生于周期时钟停止期间,如果不做任何处理,中断服务程序中如果要访问jiffies计数值,可能得到一个滞后的jiffies值,因为正常状态下,jiffies值会在恢复周期时钟时正确地更新,所以,为了防止这种情况发生,在进入中断的irq_enter期间,tick_check_idle会被调用:
1 2 3 4 5 | |
tick_check_nohz函数的最重要的作用就是更新jiffies计数值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
另外一种情况是在退出定时器中断时,需要重新评估周期时钟的运行状况,这一点已经在2.3节中做了说明,这里就不在赘述了。
http://blog.csdn.net/DroidPhone/article/details/8104433
我们已经在前面几章介绍了低分辨率定时器和高精度定时器的实现原理,内核为了方便其它子系统,在时间子系统中提供了一些用于延时或调度的API,例如msleep,hrtimer_nanosleep等等,这些API基于低分辨率定时器或高精度定时器来实现,本章的内容就是讨论这些方便、好用的API是如何利用定时器系统来完成所需的功能的。
msleep相信大家都用过,它可能是内核用使用最广泛的延时函数之一,它会使当前进程被调度并让出cpu一段时间,因为这一特性,它不能用于中断上下文,只能用于进程上下文中。要想在中断上下文中使用延时函数,请使用会阻塞cpu的无调度版本mdelay。msleep的函数原型如下:
1
| |
延时的时间由参数msecs指定,单位是毫秒,事实上,msleep的实现基于低分辨率定时器,所以msleep的实际精度只能也是1/HZ级别。内核还提供了另一个比较类似的延时函数msleep_interruptible:
1
| |
延时的单位同样毫秒数,它们的区别如下:
函数 延时单位 返回值 是否可被信号中断
msleep 毫秒 无 否
msleep_interruptible 毫秒 未完成的毫秒数 是
最主要的区别就是msleep会保证所需的延时一定会被执行完,而msleep_interruptible则可以在延时进行到一半时被信号打断而退出延时,剩余的延时数则通过返回值返回。两个函数最终的代码都会到达schedule_timeout函数,它们的调用序列如下图所示:
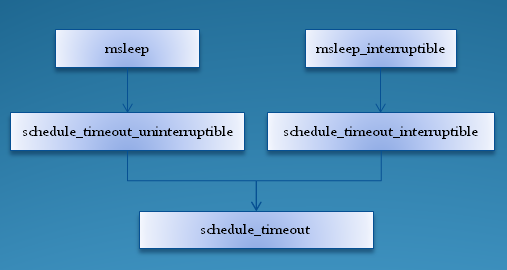
图1.1 两个延时函数的调用序列
下面我们看看schedule_timeout函数的实现,函数首先处理两种特殊情况,一种是传入的延时jiffies数是个负数,则打印一句警告信息,然后马上返回,另一种是延时jiffies数是MAX_SCHEDULE_TIMEOUT,表明需要一直延时,直接执行调度即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
然后计算到期的jiffies数,并在堆栈上建立一个低分辨率定时器,把到期时间设置到该定时器中,启动定时器后,通过schedule把当前进程调度出cpu的运行队列:
1 2 3 4 5 | |
到这个时候,进程已经被调度走,那它如何返回继续执行?我们看到定时器的到期回调函数是process_timeout,参数是当前进程的task_struct指针,看看它的实现:
1 2 3 4 | |
噢,没错,定时器一旦到期,进程会被唤醒并继续执行:
1 2 3 4 5 6 7 8 9 10 | |
schedule返回后,说明要不就是定时器到期,要不就是因为其它时间导致进程被唤醒,函数要做的就是删除在堆栈上建立的定时器,返回剩余未完成的jiffies数。
说完了关键的schedule_timeout函数,我们看看msleep如何实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
msleep先是把毫秒转换为jiffies数,通过一个while循环保证所有的延时被执行完毕,延时操作通过schedule_timeout_uninterruptible函数完成,它仅仅是在把进程的状态修改为TASK_UNINTERRUPTIBLE后,调用上述的schedule_timeout来完成具体的延时操作,TASK_UNINTERRUPTIBLE状态保证了msleep不会被信号唤醒,也就意味着在msleep期间,进程不能被kill掉。
看看msleep_interruptible的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
msleep_interruptible通过schedule_timeout_interruptible中转,schedule_timeout_interruptible的唯一区别就是把进程的状态设置为了TASK_INTERRUPTIBLE,说明在延时期间有信号通知,while循环会马上终止,剩余的jiffies数被转换成毫秒返回。实际上,你也可以利用schedule_timeout_interruptible或schedule_timeout_uninterruptible构造自己的延时函数,同时,内核还提供了另外一个类似的函数,不用我解释,看代码就知道它的用意了:
1 2 3 4 5 | |
第一节讨论的msleep函数基于时间轮定时系统,只能提供毫秒级的精度,实际上,它的精度取决于HZ的配置值,如果HZ小于1000,它甚至无法达到毫秒级的精度,要想得到更为精确的延时,我们自然想到的是要利用高精度定时器来实现。没错,linux为用户空间提供了一个api:nanosleep,它能提供纳秒级的延时精度,该用户空间函数对应的内核实现是sys_nanosleep,它的工作交由高精度定时器系统的hrtimer_nanosleep函数实现,最终的大部分工作则由do_nanosleep完成。调用过程如下图所示:
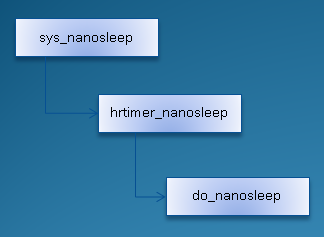
图 2.1 nanosleep的调用过程
与msleep的实现相类似,hrtimer_nanosleep函数首先在堆栈中创建一个高精度定时器,设置它的到期时间,然后通过do_nanosleep完成最终的延时工作,当前进程在挂起相应的延时时间后,退出do_nanosleep函数,销毁堆栈中的定时器并返回0值表示执行成功。不过do_nanosleep可能在没有达到所需延时数量时由于其它原因退出,如果出现这种情况,hrtimer_nanosleep的最后部分把剩余的延时时间记入进程的restart_block中,并返回ERESTART_RESTARTBLOCK错误代码,系统或者用户空间可以根据此返回值决定是否重新调用nanosleep以便把剩余的延时继续执行完成。下面是hrtimer_nanosleep的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
接着我们看看do_nanosleep的实现代码,它首先通过hrtimer_init_sleeper函数,把定时器的回调函数设置为hrtimer_wakeup,把当前进程的task_struct结构指针保存在hrtimer_sleeper结构的task字段中:
1 2 3 4 5 6 7 8 9 10 | |
然后,通过一个do/while循环内:启动定时器,挂起当前进程,等待定时器或其它事件唤醒进程。这里的循环体实现比较怪异,它使用hrtimer_active函数间接地判断定时器是否到期,如果hrtimer_active返回false,说明定时器已经过期,然后把hrtimer_sleeper结构的task字段设置为NULL,从而导致循环体的结束,另一个结束条件是当前进程收到了信号事件,所以,当因为是定时器到期而退出时,do_nanosleep返回true,否则返回false,上述的hrtimer_nanosleep正是利用了这一特性来决定它的返回值。以下是do_nanosleep循环体的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
除了hrtimer_nanosleep,高精度定时器系统还提供了几种用于延时/挂起进程的api:
schedule_hrtimeout 使得当前进程休眠指定的时间,使用CLOCK_MONOTONIC计时系统;
schedule_hrtimeout_range 使得当前进程休眠指定的时间范围,使用CLOCK_MONOTONIC计时系统;
schedule_hrtimeout_range_clock 使得当前进程休眠指定的时间范围,可以自行指定计时系统;
usleep_range 使得当前进程休眠指定的微妙数,使用CLOCK_MONOTONIC计时系统;
它们之间的调用关系如下:
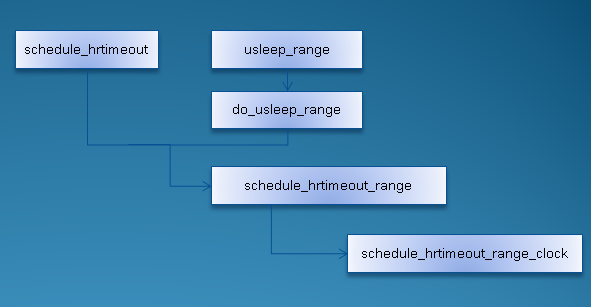
图 2.2 schedule_hrtimeout_xxxx系列函数
最终,所有的实现都会进入到schedule_hrtimeout_range_clock函数。需要注意的是schedule_hrtimeout_xxxx系列函数在调用前,最好利用set_current_state函数先设置进程的状态,在这些函数返回前,进城的状态会再次被设置为TASK_RUNNING。如果事先把状态设置为TASK_UNINTERRUPTIBLE,它们会保证函数返回前一定已经经过了所需的延时时间,如果事先把状态设置为TASK_INTERRUPTIBLE,则有可能在尚未到期时由其它信号唤醒进程从而导致函数返回。主要实现该功能的函数schedule_hrtimeout_range_clock和前面的do_nanosleep函数实现原理基本一致。大家可以自行参考内核的代码,它们位于:kernel/hrtimer.c。