

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
test指令
TEST对两个参数(目标,源)执行AND逻辑操作,并根据结果设置标志寄存器,结果本身不会保存。TEST AX,BX 与 AND AX,BX 命令有相同效果
语法: TEST R/M, R/M/DATA
影响标志: C,O,P,Z,S(其中C与O两个标志会被设为0)
结果: 执行AND逻辑操作结果为0则设置ZF零标志为1
TEST的一个非常普遍的用法是用来测试一方寄存器是否为空:
1 2 | |
如果ECX为零,设置ZF零标志为1,JZ跳转
LVS详解
http://www.cnblogs.com/xiaocen/p/3709869.html
简介:
Linux 虚拟服务器(Linux Virtual Server. LVS),是一个由章文松开发的自由软件.利用KVS可以实现高可用的、可伸缩缩的Web, Mail, Cache和Medial等网络股务..井在此基 础上开发支持庞大用户数的,可伸缩的,高可用的电子商务应用。LVS1998年发展到现在,已经变得比较成熟,目前广泛应用在各种网络服务和电了商务应用 中.
LVS具有很好的伸缩缩性、可靠性和管埋性,通过LVS要实现的最终目标是:利用linux 操作系统和LVS集群软件实现一个高可用、高性能,低成本的服务器应用集群。
LVS集群的组成
利用LVS架设的服务器群系统由3个部分组成:最前端的是负栽均衡层(这里用 Lo ad Balancer表示),中间是服务器集群层(用Server Array表示). LVS体系结构如下图所示:
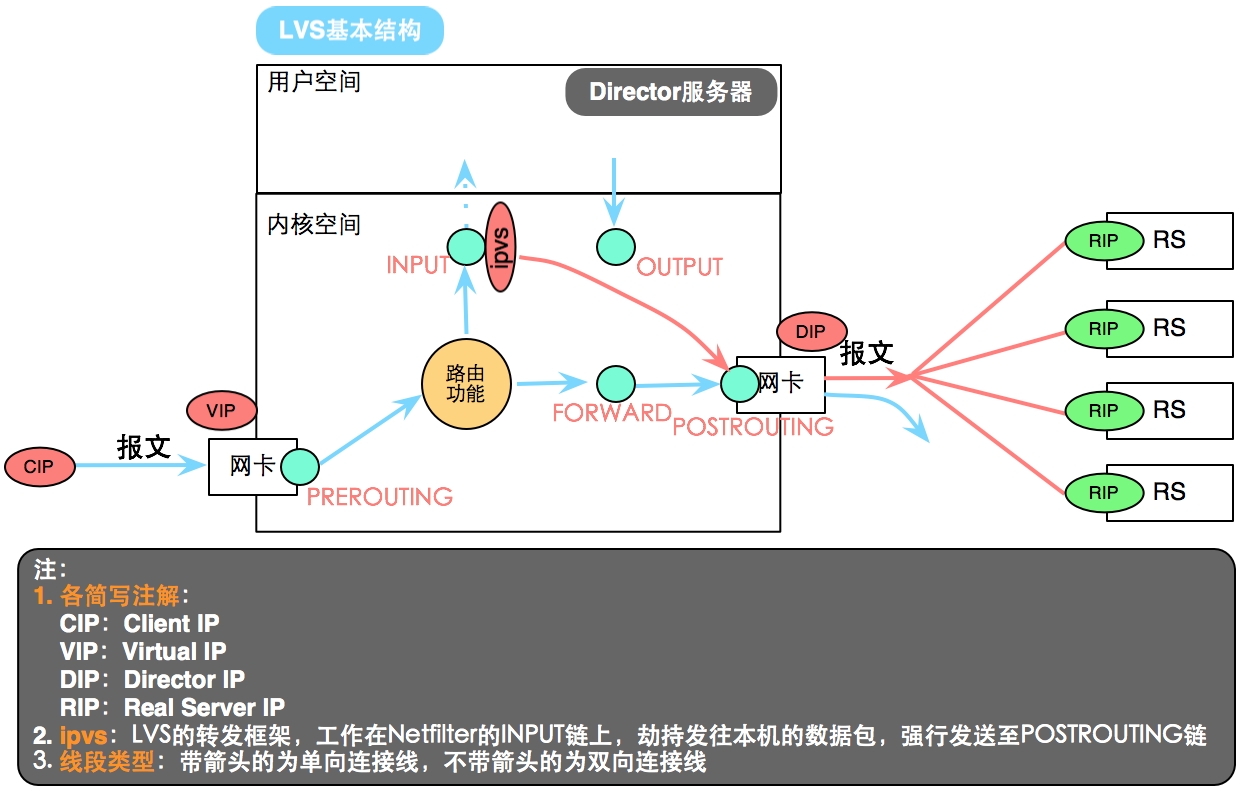
下面对LVS的各个组成部分进行详细介绍
负栽均衡层:位于整个集群系统的最前端,由一台或多台负栽调度器(Dircctm Server)组成.LVS核心模块IPVS就安装在director Server上,而director的主要作用类似于一个路由器,它含有为完成LVS功能所设定的路由表,通过这些路由表把用户的请求分发给服务器群组层 的应用服务器(real Server)。同时,在director server上还要安装队real server的监控模块Ldirectord,此模块用于监测各个real server 服务的健康状况。在real server 不可同时可以讲其从LVS路由表中剔除,在恢复时重新加入。
服务器群组层:由一组实际运行应用服务的机器组成,real Server可以是Web服务器、Mail服务器、FTP服务器、DNS服务器、视颊服务器中的一个或多个,每个Real Server之间通过高速的LAN或分布在
各地的WAN相连接:实际的应用中, Director Server也可以同时兼任Real Server的角色
共字存储层是为所有Real Server提供共亨存储空问和内容一致性的存储区域,一般由磁盘阵列设备组成。为了提俱内容的一致性,一般可以通过NFS网络义件系统共 亨数据,但是NFS在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件 系统,例如Red Hat的GFS文件系统,Oracle提供的OS2文件系统等。
从整个LVS结构可以看出,Director Server是整个LVS的核心。目前,用干Director Server 的操作系统只有Linux和FreeBSD, Linux 2.6内核完全内置了LVS的各个模块,不用任何 设置就可以支持LVS功能。
对于 Real.Server,几乎所有的系统平台,如 Linux、.. Windows、Solaris、AIX、BSD 系列等都能很好地支持它
LVS集群的特点
1. IP负载均衡与负载调度
负栽均衡技术有很多实现方案,有基于DNS.域名轮流解析的方法,有基于客户端调度访问的方法,还有基于应用层系统负栽的调度方法,还有基于p地址的调度方法。在这些负栽 调度算法中,执行效率最卨的是IP负栽均衡技术。
LVS 的IP负栽均衡技术是通过IPVS模块来实现的。IPVS是LVS集群系统的核心软件, 它的主要作用是:安装在Director Server上,同时在Director Server ..上虚拟出一个IP地址, 用户必须通过这个虚拟的IP地址访问服务器,这个虚拟IP —般称为LVS的VIP,即Virtual IP 访问的请求首先经过VIP到达负栽调度器,然后由负栽调度器从Real Server列表中选取 一个服务节点响应用户的请求。 在用户的清求到达负栽调度器后,调度器如何将请求发送到提供服务的Real Server节 点,而Real Server节点如何返回数据给用户,是IPVS实现的重点技术。IPVS实现负栽均 衡的方式有4种.分别是NAT|Full NAT、TUN和DR。下面进行详细介绍。
IPVS/NAT :
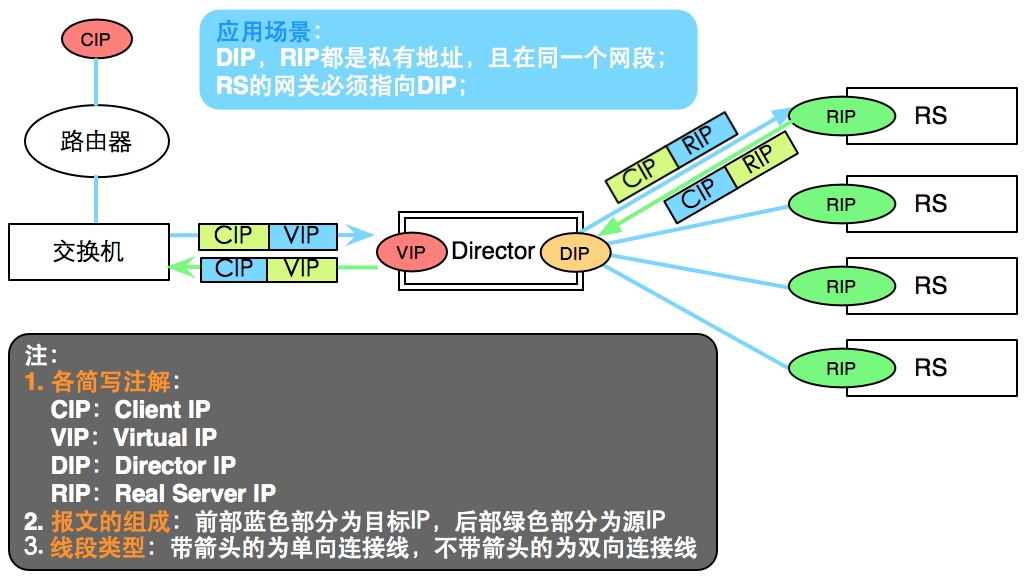
即 Virtual Server via Network Address Translation,也就是网络地址翻译技术实现虚拟服务器。当用户请求到达调度器时,调度器将请求报文的目标地址(即 虚拟IP地址)改写成选定的Real Server地址,同时将报文的目标端口也改成选定的 Real Server的相应端口,最后将报文请求发送到选定的Real Server。在服务器端得到数据后,Real Server将数据返回给用户时,需要再次经过负栽调度器将报文的源地址和源端口改成虚拟IP地址和相应端口,然后把数据发送给用户,完成整个负栽调度过 程。可以看出,在NAT方式下,用户请求和响应报文都必须经过Director Server地址重写, 当用户请求越来越多时,调度器的处理能力将成为瓶颈. 如下图所示:IPVS/NAT 架构图
NAT:多目标的DNAT
特性:
RS应该使用私有地址;
RS的网关必须指向DIP;
RIP和DIP必须在同一网段内;
请求和响应的报文都得经过Director;(在高负载应用场景中,Director很可能成为系统性能瓶颈)
支持端口映射;
RS可以使用任意支持集群服务的OS(如Windows)
适用场景:非高并发请求场景,10个RS以内;可隐藏内部的DIP和RIP地址;
结构图:
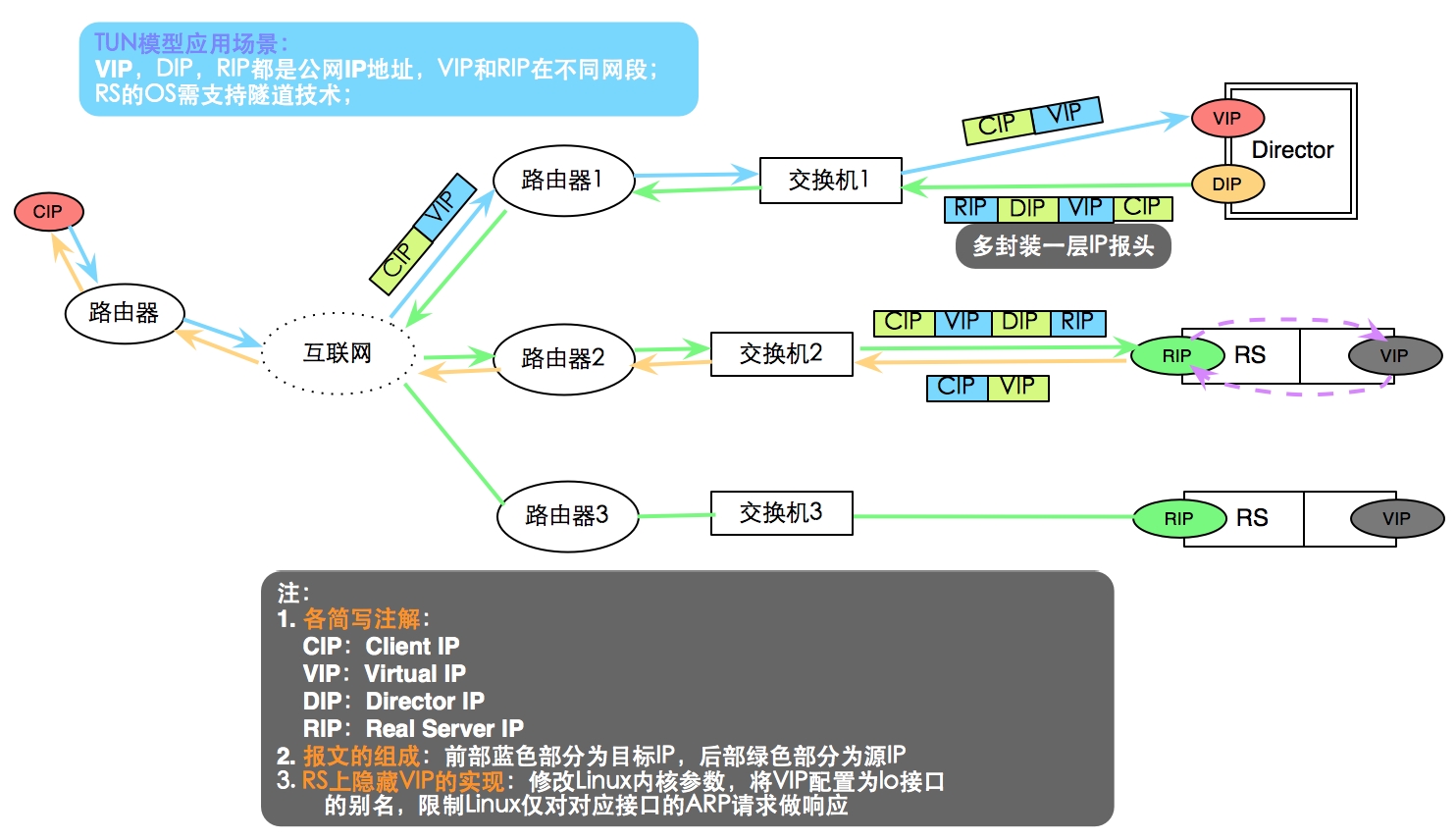
LVS/TUN :
即Virtual Server via IP Tunneling,也就是通过IP隧道技术实现虚拟服务器。这种方式的连接调度度和管理与VS/NAT方式一样,只是报文转发方法不同。在 VS/TUN方式中,调度器采用IP隧道技术将用户清求转发到某个Real Server,而这 个Real Server 将直接响应用户的请求,不再经过前端调度器。此外,对Real Server 的地域位置没有要求,可以和Director Server位于同一个网段,也可以在独立的一个 网络中。因此,在TUN方式中,调度器将只处理用户的报文请求,从而使集群系统 的吞吐量大大提高。如下图所示VS/TUN 架构图:
TUN:IP隧道,即含有多个IP报头
特性:
RIP、DIP、VIP都得是公网地址;
RS的网关不会指向也不可能指向DIP;
请求报文经过Director,但响应报文一定不经过Director;
不支持端口映射;
RS的操作系统必须得支持隧道功能,即部署ipip模块
适用场景:跨互联网的请求转发
结构图:
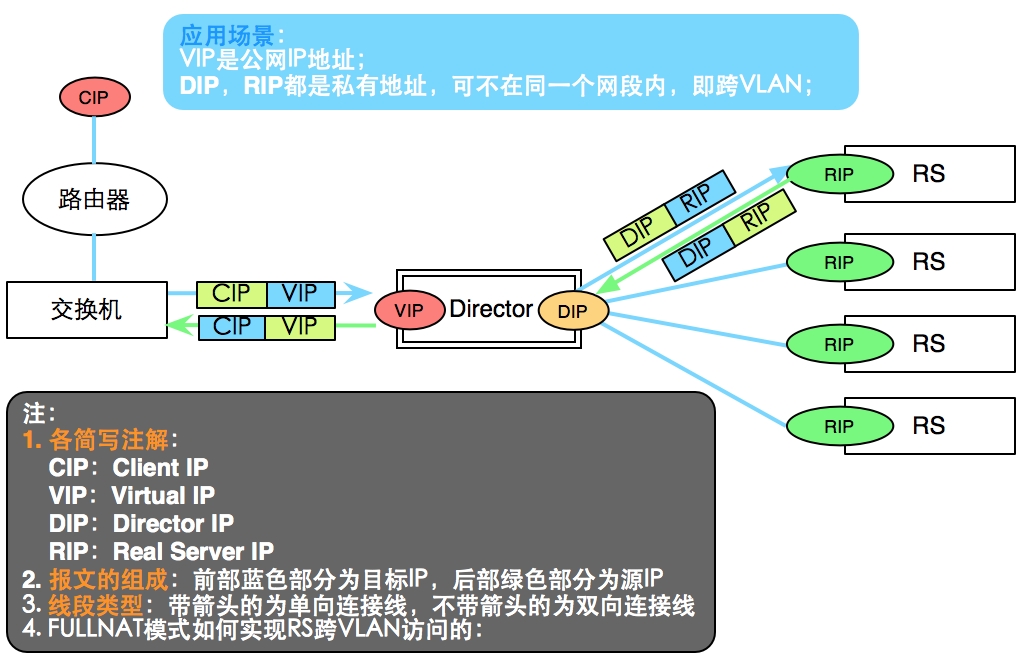
FULLNAT是一种新的转发模式
– 主要思想:引入local address(内网ip地址),cip-vip转 换为lip->rip,而 lip和rip均为IDC内网ip,可以跨vlan通 讯;
FULLNAT:NAT模型的改进版
特性:
实现RS间跨VLAN通信,是NAT模式的改进版;
默认内核不支持,需重新编译内核,才能使用;
适用场景:内网服务器跨VLAN的负载分担
结构图:
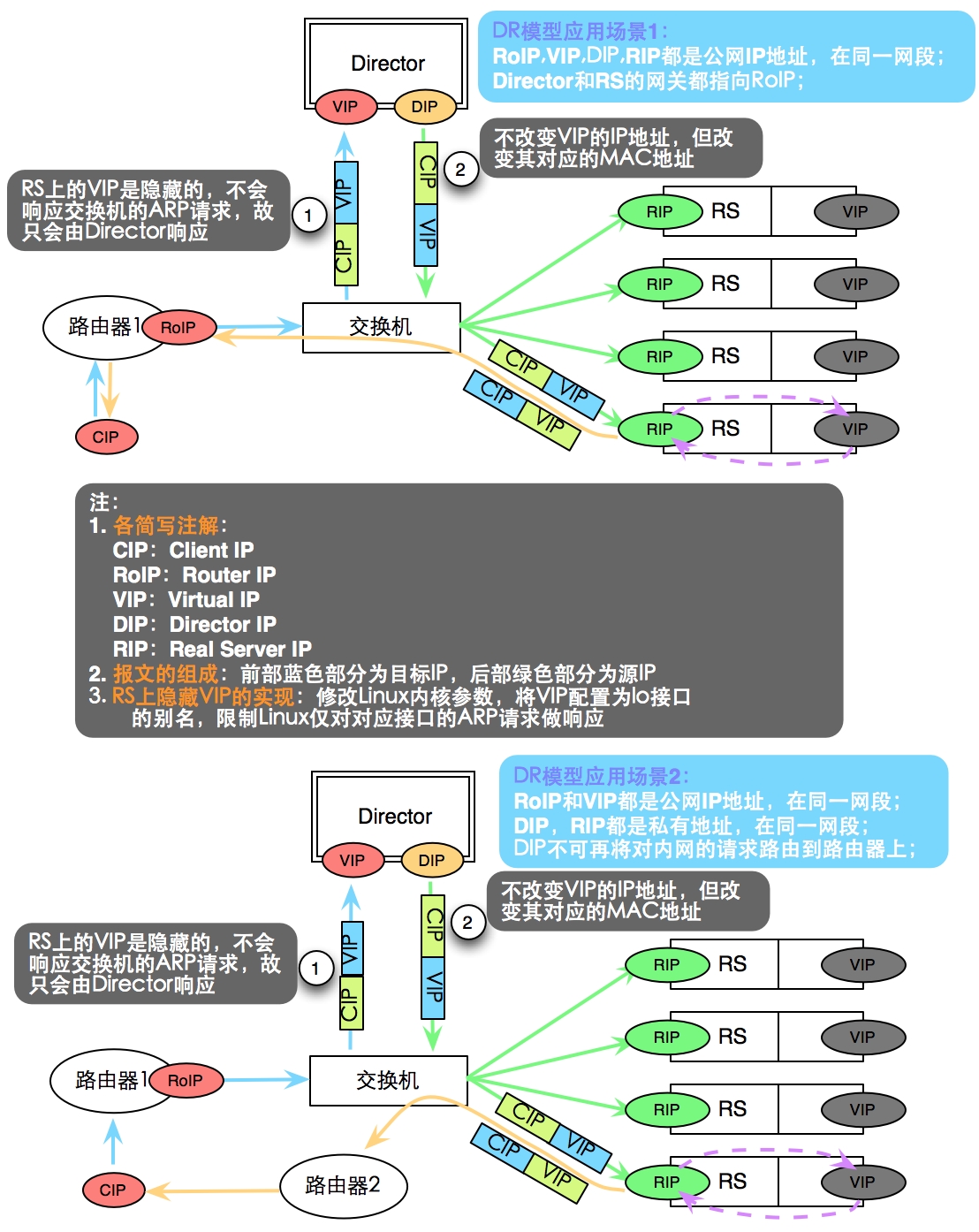
LVS/DR:
即Virtual Server via Direct Routing,也就是用直接路由技术实现虚拟服务器。 这种方式的连按调度和管理与前两种一样,但它的报文转发方法又有所不同,VS/DR 通过改写请求报文的MAC地址,将请求发送到Real Server,而Real Server将响应直接返回给客户.免去了VS/TUN中的IP隧道开销,这种方式是3种负莪调度方式中 性能最好的,但是要求Director Server与Real Server必须由一块网卡连在同一物理网段上。
如下图所示:VS/DR 架构图
DR:Direct Routing
需解决的关键问题: 让前端路由将请求发往VIP时,只能是Director上的VIP进行响应;实现方式是修改RS上的Linux内核参数,将RS上的VIP配置为lo接口的别名,并限制Linux仅对对应接口的ARP请求做响应
特性:
RS可以使用私有地址,但也可以使用公网地址,此时可以直接通过互联网连入RS以实现配置,监控等;
RS的网关一定不能指向DIP;
RS和Director要在同一物理网络(即不能由路由器分隔)
请求报文经过Director,但响应报文一定不进过Director;
不支持端口映射;
RS可以使用大多数的操作系统
适用场景:因为响应报文不经过Director,极大的减轻了Director的负载压力,故Director可以支持更大的并发访问,一般RS在100台以内;
结构图:
LVS-DR配置架构根据其VIP与RIP是否在同一个网段内又分为两种模型:
LVS调度算法
静态方法:仅根据算法本身进行调度
1 2 3 4 | |
动态方法:根据算法及RS当前的负载情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
前面介绍过,负载调度器是根据各个服务器的负栽情况,动态地选择一台Real Server响 应用户请求。那么动态选择是如何实现呢?其实就是通过这里要说的负栽调度算法。根据不同的网络眼务需求和眼务器配IPVS实现T8种负栽调度算法。这里详 细讲述最常用的4 种调度算法。
1、 轮询(round robin, rr),加权轮询(Weighted round robin, wrr)——新的连接请求被轮流分配至各RealServer;算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。轮叫调度 算法假设所有服务器处理性能均相同,不管服务器的当前连接数和响应速度。该算法相对简单,不适用于服务器组中处理性能不一的情况,而且当请求服务时间变化 比较大时,轮叫调度算法容易导致服务器间的负载不平衡。
2、 最少连接(least connected, lc), 加权最少连接(weighted least connection, wlc)——新的连接请求将被分配至当前连接数最少的RealServer;最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务 器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中止或超时,其连接数减一。
3、 基于局部性的最少链接调度(Locality-Based Least Connections Scheduling,lblc)——针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群中客户请求报文 的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同 一台服务器,来提高各台服务器的访问局部性和主存Cache命中率,从而整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP地址找出该目标 IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于其一半的工作负载,则 用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。
4、 带复制的基于局部性最少链接调度(Locality-Based Least Connections with Replication Scheduling,lblcr)——也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个 目标IP地址到一组服务器的映射,而 LBLC算法维护从一个目标IP地址到一台服务器的映射。对于一个“热门”站点的服务请求,一台Cache 服务器可能会忙不过来处理这些请求。这时,LBLC调度算法会从所有的Cache服务器中按“最小连接”原则选出一台Cache服务器,映射该“热门”站 点到这台Cache服务器,很快这台Cache服务器也会超载,就会重复上述过程选出新的Cache服务器。这样,可能会导致该“热门”站点的映像会出现 在所有的Cache服务器上,降低了Cache服务器的使用效率。LBLCR调度算法将“热门”站点映射到一组Cache服务器(服务器集合),当该“热 门”站点的请求负载增加时,会增加集合里的Cache服务器,来处理不断增长的负载;当该“热门”站点的请求负载降低时,会减少集合里的Cache服务器 数目。这样,该“热门”站点的映像不太可能出现在所有的Cache服务器上,从而提供Cache集群系统的使用效率。LBLCR算法先根据请求的目标IP 地址找出该目标IP地址对应的服务器组;按“最小连接”原则从该服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载;则按 “最小连接”原则从整个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服 务器从服务器组中删除,以降低复制的程度。
5、 目标地址散列调度(Destination Hashing,dh)算法也是针对目标IP地址的负载均衡,但它是一种静态映射算法,通过一个散列(Hash)函数将一个目标IP地址映射到一台服务 器。目标地址散列调度算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
6、 源地址散列调度(Source Hashing,sh)算法正好与目标地址散列调度算法相反,它根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法 的相同。除了将请求的目标IP地址换成请求的源IP地址外,它的算法流程与目标地址散列调度算法的基本相似。在实际应用中,源地址散列调度和目标地址散列 调度可以结合使用在防火墙集群中,它们可以保证整个系统的唯一出入口。
7、加权最少连接调度(Weighted Least Connections)。 “加 权最少连接调度”是“最少连接调度”的超集。每个服务节点可以用相应的权值表示其处理能力,而系统管理员可以动态地设置相应的权值,默认权值为1。加权最 小连接调 度在分新连接请求时尽可能使服务节点的已建立连接数和其权值成正比。算法: overhead=active*256+inactive/weight overhead最小值胜出;
8、sed:shorttest expect delay 最小期望延迟(改进的wlc) 算法:overhead=(active+1)*256/weight,案例:假如DFG三台机器分别权重123,连接数也分别是123.那么如果使用WLC算法的话一个新请求进入时它可能会分给DFG中的任意一个。使用sed算法后会进行这样一个运算:
D(1+1)/1
F(1+2)/2
G(1+3)/3
9、nq:nerver queue 增强改进的sed算法.如果有台real Server的连接数=0直接分配,不需要再进行sed运算
2.高可用性
LVS 是一个基于内核级别的应用软件,因此具有很髙的处理性能。由LVS构建的负载 均衡集群系统具有优秀的处理能力,每个服务节点的故障不会影响整个系统的正常使用,又能够实现负载的合理均衡,使应用具有超高负荷的服务能力,可支持上百 万个并发连接请 求。如配置百兆网卡,采用VS/TUN或VS/DR调度技术,整个集群系统的吞吐量可高达 1 Gbit/s;又如配置千兆网卡,系统的最大吞吐量可接近10Gbit/s。
3.高可靠性
LVS负载均衡集群软件已经在 企业和学校中得到了很好的普及,国内外很多大型的、关键性的Web站点也都采用了 LVS集群软件,所以它的可靠性在实践中得到了很好印证。有 很多由LVS构成的负载均衡系统,运行很长时间,从未进行过重新启动。这些都说明了 LVS 的髙稳定性和高可靠性。
4、配置LVS
1、定义在Director上进行dispatching的服务(service),以及哪此服务器(server)用来提供此服务;
2、为每台同时提供某一种服务的服务器定义其权重(即概据服务器性能确定的其承担负载的能力);
注:权重用整数来表示,有时候也可以将其设置为atomic_t;其有效表示值范围为24bit整数空间,即(224-1);
因此,ipvsadm命令的主要作用表现在以下方面:
1、添加服务(通过设定其权重>0);
2、关闭服务(通过设定其权重>0);此应用场景中,已经连接的用户将可以继续使用此服务,直到其退出或超时;新的连接请求将被拒绝;
3、保存ipvs设置,通过使用“ipvsadm-sav > ipvsadm.sav”命令实现;
4、恢复ipvs设置,通过使用“ipvsadm-sav < ipvsadm.sav”命令实现;
5、显示ip_vs的版本号,下面的命令显示ipvs的hash表的大小为4k;
1 2 | |
6、显示ipvsadm的版本号
1 2 | |
二、ipvsadm使用中应注意的问题
默认情况下,ipvsadm在输出主机信息时使用其主机名而非IP地址,因此,Director需要使用名称解析服务。如果没有设置名称解析服务、服务不可 用或设置错误,ipvsadm将会一直等到名称解析超时后才返回。当然,ipvsadm需要解析的名称仅限于RealServer,考虑到DNS提供名称 解析服务效率不高的情况,建议将所有RealServer的名称解析通过/etc/hosts文件来实现;
三、调度算法
Director在接收到来自于Client的请求时,会基于"schedule"从RealServer中选择一个响应给Client。ipvs支持以下调度算法:
四、关于LVS追踪标记fwmark:
如果LVS放置于多防火墙的网络中,并且每个防火墙都用到了状态追踪的机制,那么在回应一个针对于LVS的连接请求时必须经过此请求连接进来时的防火墙,否则,这个响应的数据包将会被丢弃。
常用命令:
1 2 3 4 5 6 7 8 9 10 | |
VS/NAT
LVS- NAT基于cisco的LocalDirector。VS/NAT不需要在RealServer上做任何设置,其只要能提供一个tcp/ip的协议栈即 可,甚至其无论基于什么OS。基于VS/NAT,所有的入站数据包均由Director进行目标地址转换后转发至内部的 RealServer,RealServer响应的数据包再由Director转换源地址后发回客户端。
VS/NAT模式不能与netfilter兼容,因此,不能将VS/NAT模式的Director运行在netfilter的保护范围之中。现在已经有补丁可以解决此问题,但尚未被整合进ip_vs code。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
设置VS/NAT模式的LVS(这里以web服务为例) Director:
1 2 3 4 5 6 7 8 9 10 11 | |
服务控制脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
Real Server:
route add default gw 192.168.10.10 注释:在real server 上网关一定要指向director服务器的DIP,不然用户请求的数据报文,在LVS/NAT模型中将无法发送出去.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
ARP问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
在如上图的VS/DR或VS/TUN 应用的一种模型中(所有机器都在同一个物理网络),所有机器(包括Director和RealServer)都使用了一个额外的IP地址,即VIP。当一 个客户端向VIP发出一个连接请求时,此请求必须要连接至Director的VIP,而不能是RealServer的。因为,LVS的主要目标就是要 Director负责调度这些连接请求至RealServer的。
因此,在Client发出至VIP的连接请求后,只能由Director将其 MAC地址响应给客户端(也可能是直接与Director连接的路由设备),而Director则会相应的更新其ipvsadm table以追踪此连接,而后将其转发至后端的RealServer之一。
如果Client在请求建立至VIP的连接时由某RealServer 响应了其请求,则Client会在其MAC table中建立起一个VIP至RealServer的对就关系,并以至进行后面的通信。此时,在Client看来只有一个RealServer而无法意 识到其它服务器的存在。
为了解决此问题,可以通过在路由器上设置其转发规则来实现。当然,如果没有权限访问路由器并做出相应的设置,则只能通过传统的本地方式来解决此问题了。这些方法包括:
1、禁止RealServer响应对VIP的ARP请求;
2、在RealServer上隐藏VIP,以使得它们无法获知网络上的ARP请求;
3、基于“透明代理(Transparent Proxy)”或者“fwmark (firewall mark)”;
4、禁止ARP请求发往RealServers;
传统认为,解决ARP问题可以基于网络接口,也可以基于主机来实现。Linux采用了基于主机的方式,因为其可以在大多场景中工作良好,但LVS却并不属于 这些场景之一,因此,过去实现此功能相当麻烦。现在可以通过设置arp_ignore和arp_announce,这变得相对简单的多了。
Linux 2.2和2.4(2.4.26之前的版本)的内核解决“ARP问题”的方法各不相同,且比较麻烦。幸运的是,2.4.26和2.6的内核中引入了两个新的 调整ARP栈的标志(device flags):arp_announce和arp_ignore。基于此,在DR/TUN的环境中,所有IPVS相关的设定均可使用 arp_announce=2和arp_ignore=½/3来解决“ARP问题”了。
arp_annouce:Define different restriction levels for announcing the local source IP address from IP packets in ARP requests sent on interface;
0 - (default) Use any local address, configured on any interface.
1 - Try to avoid local addresses that are not in the target’s subnet for this interface.
2 - Always use the best local address for this target.
arp_ignore: Define different modes for sending replies in response to received ARP requests that resolve local target IP address.
0 - (default): reply for any local target IP address, configured on any interface.
1 - reply only if the target IP address is local address configured on the incoming interface.
2 - reply only if the target IP address is local address configured on the incoming interface and both with the sender’s IP address are part from same subnet on this interface.
3 - do not reply for local address configured with scope host, only resolutions for golbal and link addresses are replied.
4-7 - reserved
8 - do not reply for all local addresses
在RealServers上,VIP配置在本地回环接口lo上。如果回应给Client的数据包路由到了eth0接口上,则arp通告或请应该通过eth0实现,因此,需要在sysctl.conf文件中定义如下配置:
1 2 3 4 5 | |
以上选项需要在启用VIP之前进行,否则,则需要在Drector上清空arp表才能正常使用LVS。
到 达Director的数据包首先会经过PREROUTING,而后经过路由发现其目标地址为本地某接口的地址,因此,接着就会将数据包发往 INPUT(LOCAL_IN HOOK)。此时,正在运行内核中的ipvs(始终监控着LOCAL_IN HOOK)进程会发现此数据包请求的是一个集群服务,因为其目标地址是VIP。于是,此数据包的本来到达本机(Director)目标行程被改变为经由 POSTROUTING HOOK发往RealServer。这种改变数据包正常行程的过程是根据IPVS表(由管理员通过ipvsadm定义)来实现的。
如果有 多台Realserver,在某些应用场景中,Director还需要基于“连接追踪”实现将由同一个客户机的请求始终发往其第一次被分配至的 Realserver,以保证其请求的完整性等。其连接追踪的功能由Hash table实现。Hash table的大小等属性可通过下面的命令查看:
1
| |
为了保证其时效性,Hash table中“连接追踪”信息被定义了“生存时间”。LVS为记录“连接超时”定义了三个计时器:
1、空闲TCP会话;
2、客户端正常断开连接后的TCP会话;
3、无连接的UDP数据包(记录其两次发送数据包的时间间隔);
上面三个计时器的默认值可以由类似下面的命令修改,其后面的值依次对应于上述的三个计时器:
1
| |
数据包在由Direcotr发往 Realserver时,只有目标MAC地址发生了改变(变成了Realserver的MAC地址)。Realserver在接收到数据包后会根据本地路 由表将数据包路由至本地回环设备,接着,监听于本地回环设备VIP上的服务则对进来的数据库进行相应的处理,而后将处理结果回应至RIP,但数据包的原地 址依然是VIP。
ipvs的持久连接:
无论基于什么样的算法,只要期望源于同一个客户端的请求都由同一台Realserver响应时,就需要用到持久连接。比如,某一用户连续打开了三个telnet连接请求时,根据RR算法,其请求很可能会被分配至不同的Realserver,这通常不符合使用要求。
2、IPVS/DR
Director:
IP分配
VIP=192.168.0.210
RIP1=192.168.0.221
RIP2=192.168.0.222
1、下载安装ipvsadm
1
| |
2、编写并运行脚本(LVS服务器的脚本)
vim director.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | |
3、给脚本加权限,并执行
1 2 3 | |
4、配置后端的WEB服务器脚本
vim realserver.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
5、给脚本加权限,并执行
1 2 3 | |
IPvsadm 的用法和格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
集群相关的命令参数:
1 2 3 4 5 6 7 | |
RS相关的命令参数:
1 2 | |
LVS 类型:
1 2 3 4 5 6 | |
LVS的持久连接:
持久连接即是不考虑LVS的转发方法,确保所有来自同一个用户的连接转发到同一个RealServer上
lvs持久连接适用于大部分调度算法。当某一种请求需要定向到一个real server 时,就要用到持久连接 一般应用到:ssl(http.https等),ftp。。
-p //表示此连接为持久连接
N //表示维持此持久连接的时间。默认6分钟。当超过这个时间后,如果网页还没有关掉,仍处于激活状态,重新复位时间为2分钟。
持久连接的类型:
1.PCC(persistent client connector,持久用户连接)同一个用户所有的请求在超时范围之内都被定位到同一个RealServer上,这个时候在指定端口的时候使用的是0端口,就是所有的请求都转发出去。
2.PPC(persistent port connector)用户的所有请求在超时范围内按照端口定位到不同的RS上。
3.防火墙标记:把相关联的端口在防火墙上打上同样的标记,用户在访问两个相关联的服务的时候,就会定位到同一个RealServer上。
4.FTP connection:由于ftp使用的是两个端口号,所以需要单独列出来。
A.PCC实例:
1 2 3 4 | |
Directory上的配置:
1 2 3 4 5 6 7 | |
RealServer1上的配置:
1 2 3 4 5 6 7 8 9 10 | |
RealServer2上的配置:
1 2 3 4 5 6 7 8 9 10 | |
在浏览其中输入 http://192.168.1.80 然后刷新页面,可以看到页面一直不变,然后我们再使用ssh登录到192.168.1.10,使用ifconfig查看,和网页所在的RealServer同样,实验完成!
B.PPC就是根据服务的不同,定向到不同的RealServer上,在Directory上多写几个ipvsadm指向,注意端口要区分开来就行了
C.防火墙标记的持久连接
依然是上面的图 两个RealServer配置不变 在Directory上重新配置:
1 2 3 4 5 | |
测试: 在浏览其中输入 http://192.168.1.10 可以访问到网页,但是如果使用ssh连接192.168.1.10的话,就只能呗定向到192.168.1.12上也就是Directory上,实验完成
D.使用防火墙标记实现http&&https姻亲关系:
依然使用上面的拓扑图:
1.首先在RS上做证书
1 2 3 4 5 6 7 8 9 10 | |
2.其他的配置和上面一样,同样RealServer2上也采取同样的配置,我这里就不演示了
3.Directory上的配置如下:
只需要在iptables上多添加一条命令如下
1 2 | |
测试:在浏览器中输入 http://192.168.1.80 和 https://192.168.1.80 发现访问的是同一个页面,就证明成功啦!
因为LVS自身本没有多后端real server 做健康状态检测的功能所以:
编写健康状态监测脚本:
LVS负载均衡器本身是没有对后端服务器做健康状态监测的功能的;所以我们可以编写一个小小的脚本来完成这个功能; 注释:这些脚本的列子很粗糙,只是让你们了解整个过程是怎样的;
健康状态监测脚本实例:
RS健康状态检查脚本示例第一版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
RS健康状态检查脚本示例第二版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |