http://security.tencent.com/index.php/blog/msg/38
1、bootloader是什么?
简单地说,bootloader 就是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核准备好正确的环境。
Android系统基于Linux,所以bootloader部分也是与传统的嵌入式设备上运行的Linux没有什么区别。由于除Google外的大部分Android厂商都没有提供bootloader的源代码,所以分析手机设备的bootloader需要使用逆向工程的手段,当然由于有了Google官方的开源bootloader代码做参考,能让分析工作轻松不少。本文中使用的分析工具为IDA 6.5,针对的手机设备为N9006,固件版本为N9006ZCUDMK2。
2、bootloader典型结构
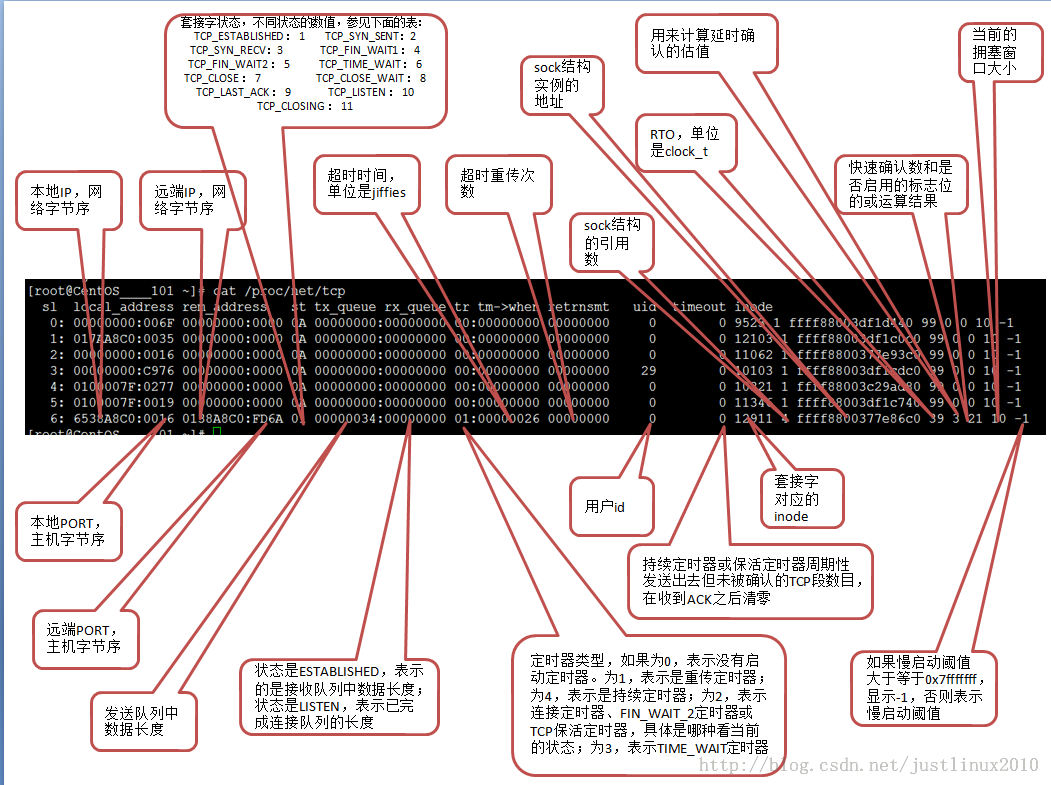
这部分会以高通MSM8960为例子介绍下Bootloader的典型结构。
高通MSM8960中包含多个运算单元,分别负责引导过程中的不同功能,sbl1的代码负责加载sbl2,sbl2加载tz和sbl3,sbl3加载apppsbl,appsbl加载HLOS。
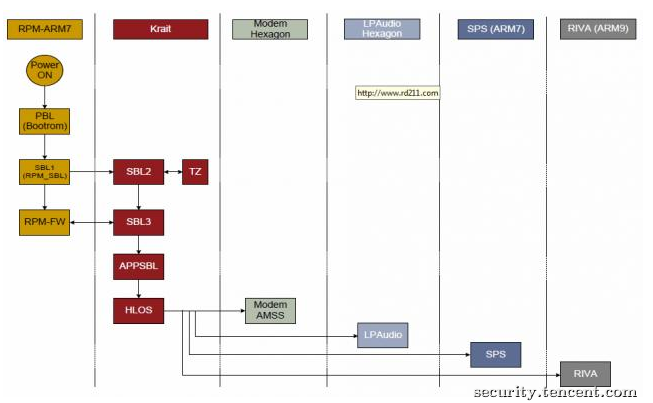
图1 SecureBoot 3.0 的Code Flow
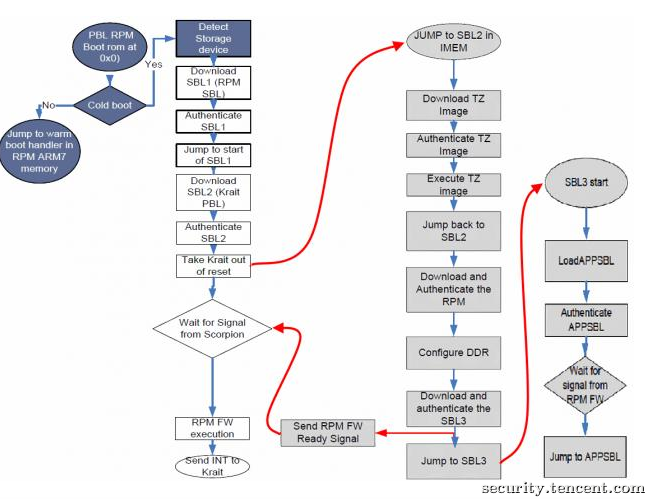
图2 MSM8960引导过程简化流程图
3、Note3的bootloader结构分析
国行版Note3(N9006)使用的CPU是MSM8974,它的bootloader结构与典型的MSM8960差不多,最大的区别就是把sbl1,sbl2,sbl3整合进了一个文件sbl1中,TrustZone和APPSBL都由sbl1进行验证和加载,以下为几个主要功能的加载代码分析。
sbl1的功能是对硬件进行初始化并加载其他模块,需要加载的模块信息按顺序保存在sbl1中,对应每个模块的数据是一段大小为0x64字节的模块信息数据内,sbl1中有一个循环负责验证和加载所有需要的其他模块(tz,rpm,wdt,appsbl),加载代码会根据模块信息内的数据调用不同的加载器加载和验证的代码,具体代码如下图。

图3 sbl1中循环加载全部模块的代码

图4 sbl1中对待加载模块进行验证
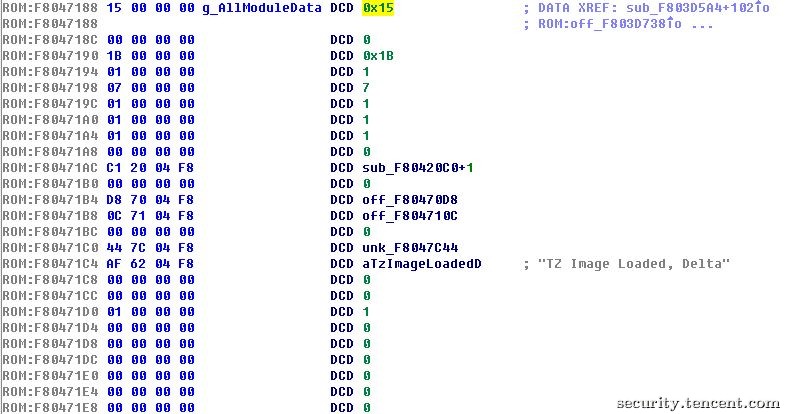
图5 TZ模块信息数据

图6 APPSBL模块信息数据
固件包里的tz.mbn是加载在TrustZone中的模块,模块格式为elf,这个模块中的代码和系统其他模块代码运行在互相隔离的区域内,权限也比其他模块更高,三星KNOX的很多底层安全特性也是在这部分中实现,关于TrustZone的更多资料可以参考arm官方的说明。
固件包里的aboot.mbn就是APPSBL模块,模块格式为bin,文件最前面的0x28字节的头部描述了bin的加载地址等信息,后面的数据就是实际加载到内存中的映像,整个bootloader中这个模块的代码量最大(很大一部分是openssl的代码),linux内核的验证和加载(正常启动和Recovery模式),ODIN模式等等代码都包含在这个模块内。

图7 aboot.mbn文件头
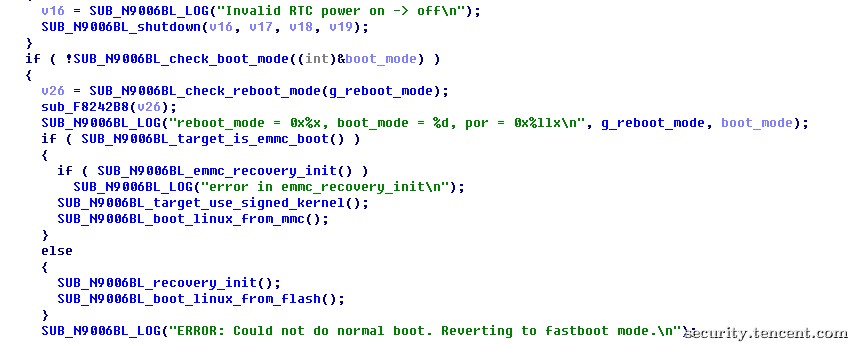
图8 根据按键和共享内存中的数据确定引导模式
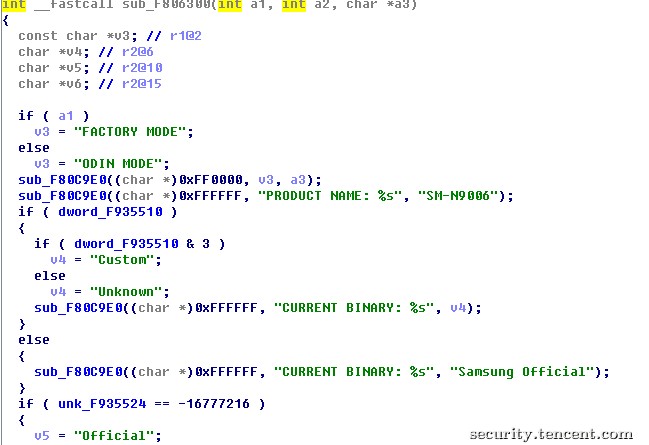
图9 三星特有的ODIN刷机模式代码
4、Note3的bootloader中KNOX系统的底层代码初步分析
Note3提供了一个企业安全套装KNOX,这个系统包含了底层的Customizable Secure Boot和TrustZone-based Integrity Measurement Architecture(TIMA,目前为2.0版本),系统层的SecurityEnhancements for Android(SE-Android)和应用层的Samsung KNOX Container,Encrypted File System(EFS),Virtual Private Network(VPN),其中Customizable Secure Boot和TIMA的代码包含在Bootloader的aboot.mbn,tz.mbn,NON-HLOS.bin中,功能为保障加载的内核在加载时和运行期的完整性。
通过前面的分析,我们已经知道了tz.mbn和aboot.mbn在加载时已经由sbl1验证过完整性,tz.mbn加载后会在CPU的安全环境下运行,从高权限的隔离区域内对系统的完整性进行监控,而负责加载android内核的aboot.mbn中包含对内核的完整性检测,三星在bootloader每一部分的结尾都会加上自己的签名,加载前会对签名进行验证,以保障系统未被修改过。
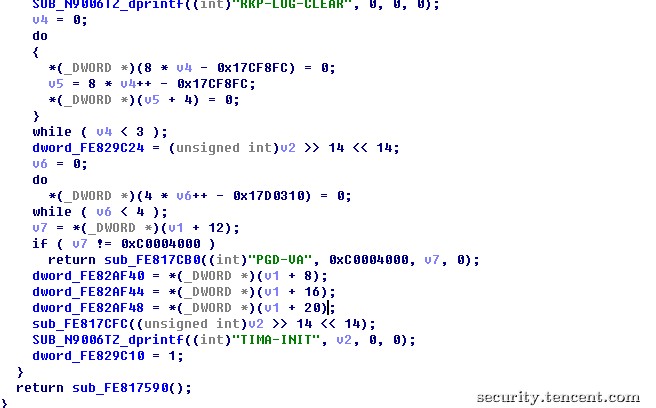
图10 tz.mbn中初始化TIMA系统的的代码

图11 aboot.mbn中对内核是否使用SEANDROID进行验证
当任何一部分检测代码发现系统异常状况后,就会调用SMC指令通知TrustZone中运行的TIMA系统设置fuse为系统完整性被破坏,此fuse数据一旦被设置后没有办法被重置,系统也无法再次进入KNOX系统。
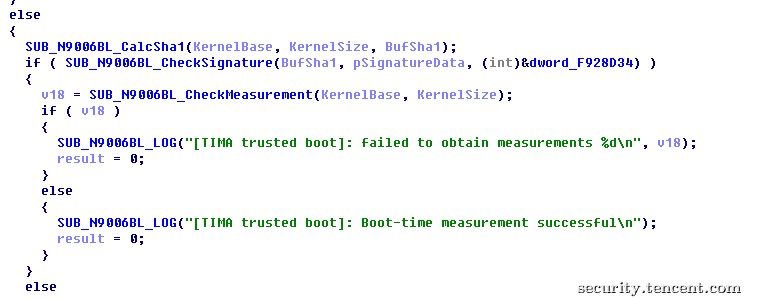
图12 加载内核前对内核签名和TIMA的测点进行验证

图13 系统完整性检测失败后设置fuse值
当以上所有检测都通过后,bootloader会把内核复制到指定的内存地址并跳到内核的入口继续执行,到此,就进入了系统内核代码的范畴,bootloader的使命也就完成了,跳到linux内核入口的代码见图14。
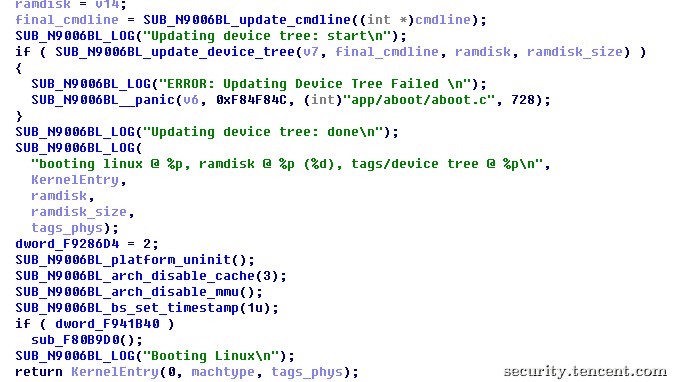
图14 内核加载和校验完成后跳到内核的入口点继续执行
另外,除了这两个模块外Modem固件相关的NON-HLOS.bin中也有大量TIMA系统相关的文件,由于TIMA系统包含大量硬件相关代码(使用三星猎户座CPU的N900中TIMA系统的实现与高通CPU的N9006差别很大),如果需要进行进一步的分析TIMA在modem中的行为,需要对TrustZone,modem工作方式等有更多了解。
图15 NON-HLOS.bin中包含的大量TIMA相关文件