http://blog.sina.com.cn/s/blog_49d5604e010008bn.html
等待队列可以参考net/ipv4/tcp_probe.c的实现
简单样例
Linux内核中的等待队列
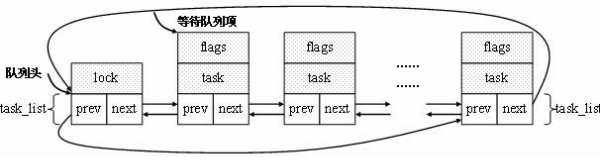
Linux内核的等待队列是以双循环链表为基础数据结构,与进程调度机制紧密结合,能够用于实现核心的异步事件通知机制。在Linux2.4.21中,等待队列在源代码树include/linux/wait.h中,这是一个通过list_head连接的典型双循环链表,
如下图所示。
在这个链表中,有两种数据结构:等待队列头(wait_queue_head_t)和等待队列项(wait_queue_t)。等待队列头和等待队列项中都包含一个list_head类型的域作为"连接件"。由于我们只需要对队列进行添加和删除操作,并不会修改其中的对象(等待队列项),因此,我们只需要提供一把保护整个基础设施和所有对象的锁,这把锁保存在等待队列头中,为wq_lock_t类型。在实现中,可以支持读写锁(rwlock)或自旋锁(spinlock)两种类型,通过一个宏定义来切换。如果使用读写锁,将wq_lock_t定义为rwlock_t类型;如果是自旋锁,将wq_lock_t定义为spinlock_t类型。无论哪种情况,分别相应设置wq_read_lock、wq_read_unlock、wq_read_lock_irqsave、wq_read_unlock_irqrestore、wq_write_lock_irq、wq_write_unlock、wq_write_lock_irqsave和wq_write_unlock_irqrestore等宏。
等待队列头
1
2
3
4
5
struct __wait_queue_head {
wq_lock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
前面已经说过,等待队列的主体是进程,这反映在每个等待队列项中,是一个任务结构指针(struct task_struct * task)。flags为该进程的等待标志,当前只支持互斥。
等待队列项
1
2
3
4
5
6
7
struct __wait_queue {
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
struct task_struct * task;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t;
声明和初始化
1
2
3
4
5
6
#define DECLARE_WAITQUEUE(name, tsk) \
wait_queue_t name = __WAITQUEUE_INITIALIZER(name, tsk)
#define __WAITQUEUE_INITIALIZER(name, tsk) { \
task: tsk, \
task_list: { NULL, NULL }, \
__WAITQUEUE_DEBUG_INIT(name)}
通过DECLARE_WAITQUEUE宏将等待队列项初始化成对应的任务结构,并且用于连接的相关指针均设置为空。其中加入了调试相关代码。
1
2
3
4
5
6
#define DECLARE_WAIT_QUEUE_HEAD(name) \
wait_queue_head_t name = __WAIT_QUEUE_HEAD_INITIALIZER(name)
#define __WAIT_QUEUE_HEAD_INITIALIZER(name) { \
lock: WAITQUEUE_RW_LOCK_UNLOCKED, \
task_list: { &(name).task_list, &(name).task_list }, \
__WAITQUEUE_HEAD_DEBUG_INIT(name)}
通过DECLARE_WAIT_QUEUE_HEAD宏初始化一个等待队列头,使得其所在链表为空,并设置链表为"未上锁"状态。其中加入了调试相关代码。
1
static inline void init_waitqueue_head(wait_queue_head_t *q)
该函数初始化一个已经存在的等待队列头,它将整个队列设置为"未上锁"状态,并将链表指针prev和next指向它自身。
1
2
3
4
5
{
q->lock = WAITQUEUE_RW_LOCK_UNLOCKED;
INIT_LIST_HEAD(&q->task_list);
}
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
该函数初始化一个已经存在的等待队列项,它设置对应的任务结构,同时将标志位清0。
1
2
3
4
5
{
q->flags = 0;
q->task = p;
}
static inline int waitqueue_active(wait_queue_head_t *q)
该函数检查等待队列是否为空。
1
2
3
4
{
return !list_empty(&q->task_list);
}
static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
将指定的等待队列项new添加到等待队列头head所在的链表头部,该函数假设已经获得锁。
1
2
3
4
{
list_add(&new->task_list, &head->task_list);
}
static inline void __add_wait_queue_tail(wait_queue_head_t *head, wait_queue_t *new)
将指定的等待队列项new添加到等待队列头head所在的链表尾部,该函数假设已经获得锁。
1
2
3
4
{
list_add_tail(&new->task_list, &head->task_list);
}
static inline void __remove_wait_queue(wait_queue_head_t *head, wait_queue_t *old)
将函数从等待队列头head所在的链表中删除指定等待队列项old,该函数假设已经获得锁,并且old在head所在链表中。
1
2
3
{
list_del(&old->task_list);
}
睡眠和唤醒操作
对等待队列的操作包括睡眠和唤醒(相关函数保存在源代码树的/kernel/sched.c和include/linux/sched.h中)。思想是更改当前进程(CURRENT)的任务状态,并要求重新调度,因为这时这个进程的状态已经改变,不再在调度表的就绪队列中,因此无法再获得执行机会,进入"睡眠"状态,直至被"唤醒",即其任务状态重新被修改回就绪态。
常用的睡眠操作有interruptible_sleep_on和sleep_on。两个函数类似,只不过前者将进程的状态从就绪态(TASK_RUNNING)设置为TASK_INTERRUPTIBLE,允许通过发送signal唤醒它(即可中断的睡眠状态);而后者将进程的状态设置为TASK_UNINTERRUPTIBLE,在这种状态下,不接收任何singal。
以interruptible_sleep_on为例,其展开后的代码是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void interruptible_sleep_on(wait_queue_head_t *q)
{
unsigned long flags;
wait_queue_t wait;
/* 构造当前进程对应的等待队列项 */
init_waitqueue_entry(&wait, current);
/* 将当前进程的状态从TASK_RUNNING改为TASK_INTERRUPTIBLE */
current->state = TASK_INTERRUPTIBLE;
/* 将等待队列项添加到指定链表中 */
wq_write_lock_irqsave(&q->lock,flags);
__add_wait_queue(q, &wait);
wq_write_unlock(&q->lock);
/* 进程重新调度,放弃执行权 */
schedule();
/* 本进程被唤醒,重新获得执行权,首要之事是将等待队列项从链表中删除 */
wq_write_lock_irq(&q->lock);
__remove_wait_queue(q, &wait);
wq_write_unlock_irqrestore(&q->lock,flags);
/* 至此,等待过程结束,本进程可以正常执行下面的逻辑 */
}
对应的唤醒操作包括wake_up_interruptible和wake_up。wake_up函数不仅可以唤醒状态为TASK_UNINTERRUPTIBLE的进程,而且可以唤醒状态为TASK_INTERRUPTIBLE的进程。
wake_up_interruptible只负责唤醒状态为TASK_INTERRUPTIBLE的进程。这两个宏的定义如下:
1
2
#define wake_up(x) __wake_up((x),TASK_UNINTERRUPTIBLE | TASK_INTERRUPTIBLE, 1)
#define wake_up_interruptible(x) __wake_up((x),TASK_INTERRUPTIBLE, 1)
wake_up函数主要是获取队列操作的锁,具体工作是调用 wake_up_common完成的。
1
2
3
4
5
6
7
8
9
void __wake_up(wait_queue_head_t *q, unsigned int mode, int nr)
{
if (q) {
unsigned long flags;
wq_read_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr, 0);
wq_read_unlock_irqrestore(&q->lock, flags);
}
}
/ The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just wake everything up. If it’s an exclusive wakeup (nr_exclusive == small +ve number) then we wake all the non-exclusive tasks and one exclusive task.
There are circumstances in which we can try to wake a task which has already started to run but is not in state TASK_RUNNING. try_to_wake_up() returns zero in this (rare) case, and we handle it by contonuing to scan the queue. /
1
static inline void __wake_up_common (wait_queue_head_t *q, unsigned int mode, int nr_exclusive, const int sync)
参数q表示要操作的等待队列,mode表示要唤醒任务的状态,如TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE等。nr_exclusive是要唤醒的互斥进程数目,在这之前遇到的非互斥进程将被无条件唤醒。sync表示???
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
{
struct list_head *tmp;
struct task_struct *p;
CHECK_MAGIC_WQHEAD(q);
WQ_CHECK_LIST_HEAD(&q->task_list);
/* 遍历等待队列 */
list_for_each(tmp,&q->task_list) {
unsigned int state;
/* 获得当前等待队列项 */
wait_queue_t *curr = list_entry(tmp, wait_queue_t, task_list);
CHECK_MAGIC(curr->__magic);
/* 获得对应的进程 */
p = curr->task;
state = p->state;
/* 如果我们需要处理这种状态的进程 */
if (state & mode) {
WQ_NOTE_WAKER(curr);
if (try_to_wake_up(p, sync) && (curr->flags&WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
}
/ 唤醒一个进程,将它放到运行队列中,如果它还不在运行队列的话。"当前"进程总是在运行队列中的(except when the actual re-schedule is in progress),and as such you’re allowed to do the simpler “current->state = TASK_RUNNING” to mark yourself runnable without the overhead of this. /
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static inline int try_to_wake_up(struct task_struct * p, int synchronous)
{
unsigned long flags;
int success = 0;
/* 由于我们需要操作运行队列,必须获得对应的锁 */
spin_lock_irqsave(&runqueue_lock, flags);
/* 将进程状态设置为TASK_RUNNING */
p->state = TASK_RUNNING;
/* 如果进程已经在运行队列中,释放锁退出 */
if (task_on_runqueue(p))
goto out;
/* 否则将进程添加到运行队列中 */
add_to_runqueue(p);
/* 如果设置了同步标志 */
if (!synchronous || !(p->cpus_allowed & (1UL << smp_processor_id())))
reschedule_idle(p);
/* 唤醒成功,释放锁退出 */
success = 1;
out:
spin_unlock_irqrestore(&runqueue_lock, flags);
return success;
}
等待队列应用模式
等待队列的的应用涉及两个进程,假设为A和B。A是资源的消费者,B是资源的生产者。A在消费的时候必须确保资源已经生产出来,为此定义一个资源等待队列。这个队列同时要被进程A和进程B使用,我们可以将它定义为一个全局变量。
1
DECLARE_WAIT_QUEUE_HEAD(rsc_queue); /* 全局变量 */
在进程A中,执行逻辑如下:
1
2
3
4
while (resource is unavaiable) {
interruptible_sleep_on( &wq );
}
consume_resource();
在进程B中,执行逻辑如下:
1
2
produce_resource();
wake_up_interruptible( &wq );