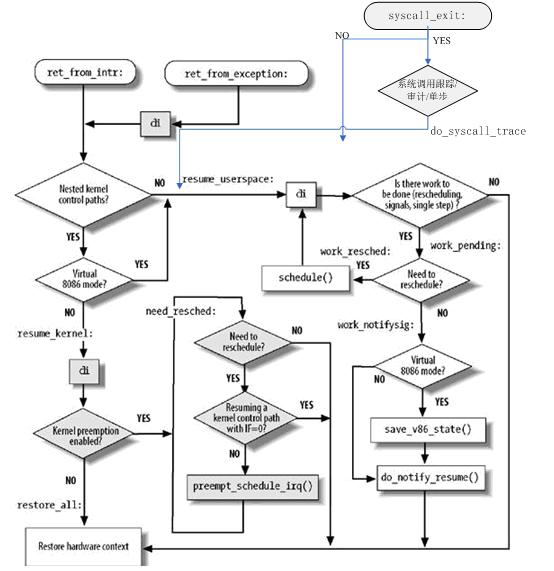
内核从2.6开始就支持内核抢占,对于非内核抢占系统,内核代码可以一直执行,直到完成,也就是说当进程处于内核态时,是不能被抢占的(当然,运行于内核态的进程可以主动放弃CPU,比如,在系统调用服务例程中,由于内核代码由于等待资源而放弃CPU,这种情况叫做计划性进程切换(planned process switch))。但是,对于由异步事件(比如中断)引起的进程切换,抢占式内核与非抢占式是有区别的,对于前者叫做强制性进程切换(forced process switch)。
//kernel/softirq.c
void local_bh_enable(void)
{
WARN_ON(irqs_disabled());
/*
* Keep preemption disabled until we are done with
* softirq processing:
*/
//软中断计数器值减1
preempt_count() -= SOFTIRQ_OFFSET - 1;
if (unlikely(!in_interrupt() && local_softirq_pending()))
do_softirq(); //软中断处理
//抢占计数据器值减1
dec_preempt_count();
//检查是否需要进行内核抢占调度
preempt_check_resched();
}
//include/linux/preempt.h
#define preempt_check_resched() \
do { \
//检查need_resched
if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) \
//抢占调度
preempt_schedule(); \
} while (0)
//kernel/sched.c
asmlinkage void __sched preempt_schedule(void)
{
struct thread_info *ti = current_thread_info();
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
//检查是否允许抢占,本地中断关闭,或者抢占计数器值不为0时不允许抢占
if (unlikely(ti->preempt_count || irqs_disabled()))
return;
need_resched:
ti->preempt_count = PREEMPT_ACTIVE;
//发生调度
schedule();
ti->preempt_count = 0;
/* we could miss a preemption opportunity between schedule and now */
barrier();
if (unlikely(test_thread_flag(TIF_NEED_RESCHED)))
goto need_resched;
}
/*返回用户空间,只需要检查need_resched*/
ENTRY(resume_userspace) #返回用户空间,中断或异常发生时,任务处于用户空间
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx # is there any work to be done on
# int/exception return?
jne work_pending #还有其它工作要做
jmp restore_all #所有工作都做完,则恢复处理器状态
#恢复处理器状态
restore_all:
RESTORE_ALL
# perform work that needs to be done immediately before resumption
ALIGN
#完成其它工作
work_pending:
testb $_TIF_NEED_RESCHED, %cl #检查是否需要重新调度
jz work_notifysig #不需要重新调度
#需要重新调度
work_resched:
call schedule #调度进程
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
/*检查是否还有其它的事要做*/
andl $_TIF_WORK_MASK, %ecx # is there any work to be done other
# than syscall tracing?
jz restore_all #没有其它的事,则恢复处理器状态
testb $_TIF_NEED_RESCHED, %cl
jnz work_resched #如果need_resched再次置位,则继续调度
#VM和信号检测
work_notifysig: # deal with pending signals and
# notify-resume requests
testl $VM_MASK, EFLAGS(%esp) #检查是否是VM模式
movl %esp, %eax
jne work_notifysig_v86 # returning to kernel-space or
# vm86-space
xorl %edx, %edx
#进行信号处理
call do_notify_resume
jmp restore_all
ALIGN
work_notifysig_v86:
pushl %ecx # save ti_flags for do_notify_resume
call save_v86_state # %eax contains pt_regs pointer
popl %ecx
movl %eax, %esp
xorl %edx, %edx
call do_notify_resume #信号处理
jmp restore_all