e2fsck 1.38 (30-Jun-2005)
fsck.ext3: while determining whether /dev/sda2 is mounted.
/: recovering journal
/: clean, 100877/4653056 files, 1236284/4648809 blocks
Mounting root filesystem.
Trying mount -t ext4 /dev/sda2 /sysroot
Trying mount -t ext3 /dev/sda2 /sysroot
Using ext3 on root filesystem
Switching to new root and running init.
^MINIT: version 2.86 booting^M
Welcome to CentOS release 5.8 (Final)
Press 'I' to enter interactive startup.
Cannot access the Hardware Clock via any known method.
Use the --debug option to see the details of our search for an access method.
Setting clock (utc): Tue Aug 5 19:18:49 PDT 2014 [ OK ]^M
Starting udev: [ OK ]^M
The point is to not touch the default kdump.conf, and mkdumprd should just work, like it does in RHEL6.
If I do put the ext3 and path directives into kdump.conf, then of course things work fine, but it shouldn’t be needed for the stock case where you just want to dump to /var/crash on your local filesystem.
–
Yeah… I saw how RHEL6 handles this, will try to backport it to RHEL5.
Thanks!
… almost. I’m pretty sure that the RHEL6 default mkdumprd uses makedumpfile by default so it isn’t just using “cp” to create the vmcore file.
The currently-patched version appears to just use “cp” instead.
–
Yeah, this is expected, because we don’t have a chance to change the default core_collector to makedumpfile on RHEL5, so “cp” is still the default one. :)
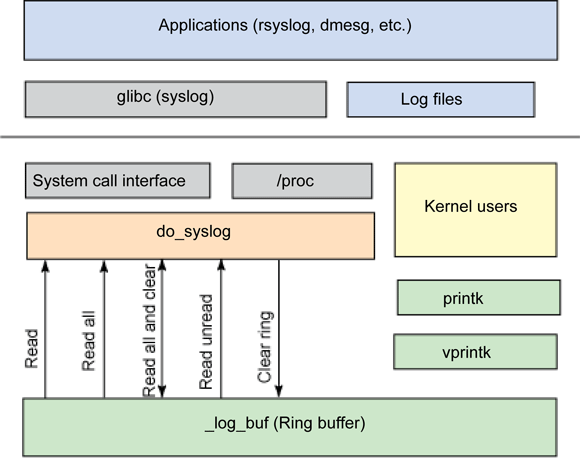
How to read it the ring buffer? Here is a beautiful illustration from IBM Developerworks
dmesg would be your first resort! How does dmesg accomplish its task? By a call to syslog()! How does syslog do its job? Through the system call interface which in turn call do_syslog(). do_syslog() does the finishing act like this