https://www.runoob.com/w3cnote/js-get-url-param.html
1 2 3 4 5 6 7 8 9 10 | |


https://www.runoob.com/w3cnote/js-get-url-param.html
1 2 3 4 5 6 7 8 9 10 | |
https://blog.csdn.net/cr27225/article/details/118603543
https://www.cnblogs.com/phpfensi/p/8143367.html
1 2 3 4 5 6 7 | |
浮点数的精度有限。尽管取决于系统,PHP 通常使用 IEEE 754 双精度格式,则由于取整而导致的最大相对误差为 1.11e-16。非基本数学运算可能会给出更大误差,并且要考虑到进行复合运算时的误差传递。
此外,以十进制能够精确表示的有理数如 0.1 或 0.7,无论有多少尾数都不能被内部所使用的二进制精确表示,因此不能在不丢失一点点精度的情况下转换为二进制的格式。
这就会造成混乱的结果:例如,floor((0.1+0.7)*10) 通常会返回 7 而不是预期中的 8,因为该结果内部的表示其实是类似 7.9999999999999991118…
所以永远不要相信浮点数结果精确到了最后一位,也永远不要比较两个浮点数是否相等。如果确实需要更高的精度,应该使用任意精度数学函数或者 gmp 函数。
bcadd — 两个任意精度数字的加法计算
bccomp — 比较两个任意精度的数字
bcdiv — 两个任意精度的数字除法计算
bcmod — 任意精度数字取模
bcmul — 两个任意精度数字乘法计算
bcpow — 任意精度数字的乘方
bcpowmod — Raise an arbitrary precision number to another, reduced by a specified modulus
bcscale — 设置/获取所有 bc math 函数的默认小数点保留位数
bcsqrt — 任意精度数字的二次方根
bcsub — 两个任意精度数字的减法
https://www.weisay.com/blog/firefox-ns-binding-aborted.html
https://blog.51cto.com/phpme/2692985
之前网站一直有一个问题,就是从首页或者列表页点击进入一篇文章页,使用FireFox自带的开发者工具查看的时候,会发现有一个NS_BINDING_ABORTED错误。
因为有个js效果,点击链接会出现“页面载入中……”字样。由于使用了location.href跳转但没有屏蔽链接本身的跳转,发生了两次请求,第一次请求就被火狐浏览器终止了,报了NS_BINDING_ABORTED错误。
1 2 3 4 5 6 7 8 9 10 11 12 | |
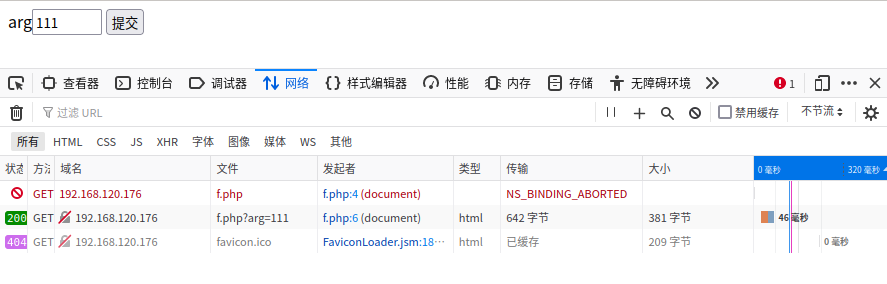
这个问题改起来也比较简单,最简单的就是去掉这个js效果,点击链接进入链接即可。
当然如果想保留这个效果,加个preventDefault事件就行,preventDefault() 方法阻止元素发生默认的行为,就可以屏蔽链接本身的跳转。