https://www.cnblogs.com/skyfsm/p/6287787.html
一、基本的udp socket编程
1. UDP编程框架
要使用UDP协议进行程序开发,我们必须首先得理解什么是什么是UDP?这里简单概括一下。
UDP(user datagram protocol)的中文叫用户数据报协议,属于传输层。UDP是面向非连接的协议,它不与对方建立连接,而是直接把我要发的数据报发给对方。所以UDP适用于一次传输数据量很少、对可靠性要求不高的或对实时性要求高的应用场景。正因为UDP无需建立类如三次握手的连接,而使得通信效率很高。
UDP的应用非常广泛,比如一些知名的应用层协议(SNMP、DNS)都是基于UDP的,想一想,如果SNMP使用的是TCP的话,每次查询请求都得进行三次握手,这个花费的时间估计是使用者不能忍受的,因为这会产生明显的卡顿。所以UDP就是SNMP的一个很好的选择了,要是查询过程发生丢包错包也没关系的,我们再发起一个查询就好了,因为丢包的情况不多,这样总比每次查询都卡顿一下更容易让人接受吧。
UDP通信的流程比较简单,因此要搭建这么一个常用的UDP通信框架也是比较简单的。以下是UDP的框架图。
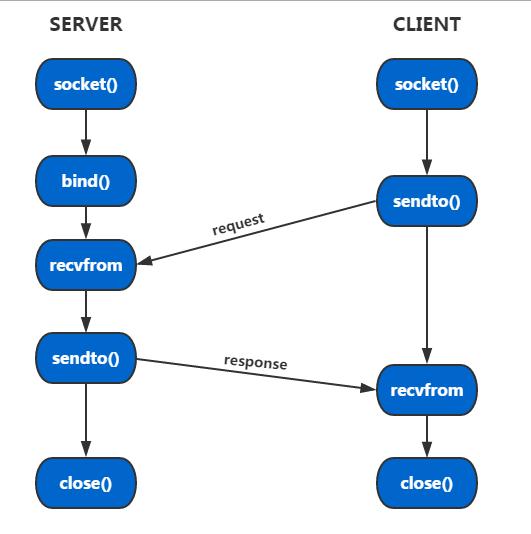
由以上框图可以看出,客户端要发起一次请求,仅仅需要两个步骤(socket和sendto),而服务器端也仅仅需要三个步骤即可接收到来自客户端的消息(socket、bind、recvfrom)。
2. UDP程序设计常用函数
1
2
3
| #include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
|
参数domain:用于设置网络通信的域,socket根据这个参数选择信息协议的族
1
2
3
4
5
6
7
8
9
10
11
12
| Name Purpose
AF_UNIX, AF_LOCAL Local communication
AF_INET IPv4 Internet protocols //用于IPV4
AF_INET6 IPv6 Internet protocols //用于IPV6
AF_IPX IPX - Novell protocols
AF_NETLINK Kernel user interface device
AF_X25 ITU-T X.25 / ISO-8208 protocol
AF_AX25 Amateur radio AX.25 protocol
AF_ATMPVC Access to raw ATM PVCs
AF_APPLETALK AppleTalk
AF_PACKET Low level packet interface
AF_ALG Interface to kernel crypto API
|
对于该参数我们仅需熟记AF_INET和AF_INET6即可
小插曲:PF_XXX和AF_XXX
我们在看Linux网络编程相关代码时会发现PF_XXX和AF_XXX会混着用,他们俩有什么区别呢?以下内容摘自《UNP》。
AF_ 前缀表示地址族(Address Family),而PF_前缀表示协议族(Protocol Family)。历史上曾有这样的想法:单个协议族可以支持多个地址族,PF_的值可以用来创建套接字,而AF_值用于套接字的地址结构。但实际上,支持多个地址族的协议族从来就没实现过,而头文件 <sys/socket.h> 中为一给定的协议定义的PF_值总是与此协议的AF_值相同。
所以我在实际编程时还是偏向于使用AF_XXX。
参数type(只列出最重要的三个):
1
2
3
| SOCK_STREAM Provides sequenced, reliable, two-way, connection-based byte streams. //用于TCP
SOCK_DGRAM Supports datagrams (connectionless, unreliable messages ). //用于UDP
SOCK_RAW Provides raw network protocol access. //RAW类型,用于提供原始网络访问
|
参数protocol:置0即可
返回值:
成功:非负的文件描述符
失败:-1
1
2
3
4
| #include <sys/types.h>
#include <sys/socket.h>
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
|
第一个参数sockfd:正在监听端口的套接口文件描述符,通过socket获得
第二个参数buf:发送缓冲区,往往是使用者定义的数组,该数组装有要发送的数据
第三个参数len:发送缓冲区的大小,单位是字节
第四个参数flags:填0即可
第五个参数dest_addr:指向接收数据的主机地址信息的结构体,也就是该参数指定数据要发送到哪个主机哪个进程
第六个参数addrlen:表示第五个参数所指向内容的长度
返回值:
成功:返回发送成功的数据长度
失败: -1
1
2
3
4
| #include <sys/types.h>
#include <sys/socket.h>
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
|
第一个参数sockfd:正在监听端口的套接口文件描述符,通过socket获得
第二个参数buf:接收缓冲区,往往是使用者定义的数组,该数组装有接收到的数据
第三个参数len:接收缓冲区的大小,单位是字节
第四个参数flags:填0即可
第五个参数src_addr:指向发送数据的主机地址信息的结构体,也就是我们可以从该参数获取到数据是谁发出的
第六个参数addrlen:表示第五个参数所指向内容的长度
返回值:
成功:返回接收成功的数据长度
失败: -1
1
2
3
| #include <sys/types.h>
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr* my_addr, socklen_t addrlen);
|
第一个参数sockfd:正在监听端口的套接口文件描述符,通过socket获得
第二个参数my_addr:需要绑定的IP和端口
第三个参数addrlen:my_addr的结构体的大小
返回值:
成功:0
失败:-1
1
2
| #include <unistd.h>
int close(int fd);
|
close函数比较简单,只要填入socket产生的fd即可。
3. 搭建UDP通信框架
server:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| #include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#define SERVER_PORT 8888
#define BUFF_LEN 1024
void handle_udp_msg(int fd)
{
char buf[BUFF_LEN]; //接收缓冲区,1024字节
socklen_t len;
int count;
struct sockaddr_in clent_addr; //clent_addr用于记录发送方的地址信息
while (1) {
memset(buf, 0, BUFF_LEN);
len = sizeof(clent_addr);
count = recvfrom(fd, buf, BUFF_LEN, 0, (struct sockaddr*)&clent_addr, &len); //recvfrom是拥塞函数,没有数据就一直拥塞
if (count == -1) {
printf("recieve data fail!\n");
return;
}
printf("client:%s\n",buf); //打印client发过来的信息
memset(buf, 0, BUFF_LEN);
sprintf(buf, "I have recieved %d bytes data!\n", count); //回复client
printf("server:%s\n",buf); //打印自己发送的信息给
sendto(fd, buf, BUFF_LEN, 0, (struct sockaddr*)&clent_addr, len); //发送信息给client,注意使用了clent_addr结构体指针
}
}
/*
server:
socket-->bind-->recvfrom-->sendto-->close
*/
int main(int argc, char* argv[])
{
int server_fd, ret;
struct sockaddr_in ser_addr;
server_fd = socket(AF_INET, SOCK_DGRAM, 0); //AF_INET:IPV4;SOCK_DGRAM:UDP
if (server_fd < 0) {
printf("create socket fail!\n");
return -1;
}
memset(&ser_addr, 0, sizeof(ser_addr));
ser_addr.sin_family = AF_INET;
ser_addr.sin_addr.s_addr = htonl(INADDR_ANY); //IP地址,需要进行网络序转换,INADDR_ANY:本地地址
ser_addr.sin_port = htons(SERVER_PORT); //端口号,需要网络序转换
ret = bind(server_fd, (struct sockaddr*)&ser_addr, sizeof(ser_addr));
if (ret < 0) {
printf("socket bind fail!\n");
return -1;
}
handle_udp_msg(server_fd); //处理接收到的数据
close(server_fd);
return 0;
}
|
client:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| #include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#define SERVER_PORT 8888
#define BUFF_LEN 512
#define SERVER_IP "172.0.5.182"
void udp_msg_sender(int fd, struct sockaddr* dst)
{
socklen_t len;
struct sockaddr_in src;
while (1) {
char buf[BUFF_LEN] = "TEST UDP MSG!\n";
len = sizeof(*dst);
printf("client:%s\n",buf); //打印自己发送的信息
sendto(fd, buf, BUFF_LEN, 0, dst, len);
memset(buf, 0, BUFF_LEN);
recvfrom(fd, buf, BUFF_LEN, 0, (struct sockaddr*)&src, &len); //接收来自server的信息
printf("server:%s\n",buf);
sleep(1); //一秒发送一次消息
}
}
/*
client:
socket-->sendto-->revcfrom-->close
*/
int main(int argc, char* argv[])
{
int client_fd;
struct sockaddr_in ser_addr;
client_fd = socket(AF_INET, SOCK_DGRAM, 0);
if (client_fd < 0) {
printf("create socket fail!\n");
return -1;
}
memset(&ser_addr, 0, sizeof(ser_addr));
ser_addr.sin_family = AF_INET;
//ser_addr.sin_addr.s_addr = inet_addr(SERVER_IP);
ser_addr.sin_addr.s_addr = htonl(INADDR_ANY); //注意网络序转换
ser_addr.sin_port = htons(SERVER_PORT); //注意网络序转换
udp_msg_sender(client_fd, (struct sockaddr*)&ser_addr);
close(client_fd);
return 0;
}
|
以上的框架用于一台主机不同端口的UDP通信,现象如下:
我们先建立server端,等待服务;然后我们建立client端请求服务。
server端:
client端:
自己主机跟自己通信不是很爽,我们想跟其他主机通信怎么搞?很简单,上面client的代码的第49行的注释打开,并注释掉下面那行,在宏定义里填入自己想通信的serverip就可以了。现象如下:
server端:
client端:
这样我们就实现了主机172.0.5.183和172.0.5.182之间的网络通信。
UDP通用框架搭建完成,我们可以利用该框架跟指定主机进行通信了。
如果想学习UDP的基础知识,以上的知识就足够了;如果想继续深入学习一下UDP SOCKET一些高级知识(奇技淫巧),可以花点时间往下看。
二、高级udp socket编程
1. udp的connect函数
什么?UDP也有conenct?connect不是用于TCP编程的吗?
是的,UDP网络编程中的确有connect函数,但它仅仅用于表示确定了另一方的地址,并没有其他含义。
有了以上认识后,我们可以知道UDP套接字有以下区分:
1)未连接的UDP套接字
2)已连接的UDP套接字
对于未连接的套接字,也就是我们常用的的UDP套接字,我们使用的是sendto/recvfrom进行信息的收发,目标主机的IP和端口是在调用sendto/recvfrom时确定的;
在一个未连接的UDP套接字上给两个数据报调用sendto函数内核将执行以下六个步骤:
1)连接套接字
2)输出第一个数据报
3)断开套接字连接
4)连接套接字
5)输出第二个数据报
6)断开套接字连接
对于已连接的UDP套接字,必须先经过connect来向目标服务器进行指定,然后调用read/write进行信息的收发,目标主机的IP和端口是在connect时确定的,也就是说,一旦conenct成功,我们就只能对该主机进行收发信息了。
已连接的UDP套接字给两个数据报调用write函数内核将执行以下三个步骤:
1)连接套接字
2)输出第一个数据报
3)输出第二个数据报
由此可以知道,当应用进程知道给同一个目的地址的端口号发送多个数据报时,显示套接字效率更高。
下面给出带connect函数的UDP通信框架
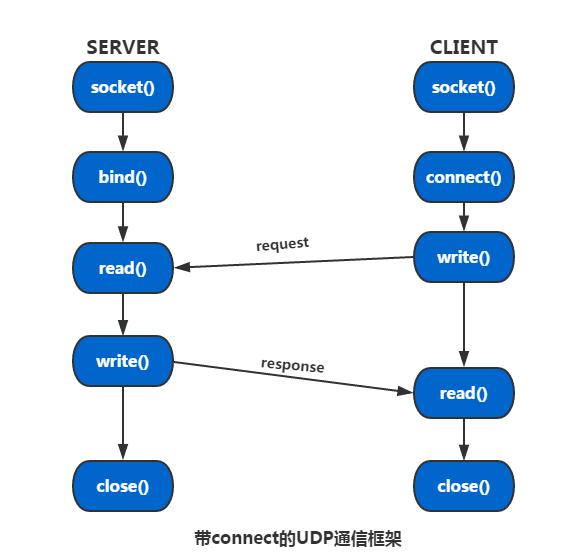
具体框架代码不再给出了,因为跟上面不带connect的代码大同小异,仅仅多出一个connect函数处理而已,下面给出处理conenct()的基本步骤。
1
2
3
4
5
6
7
8
9
10
| void udp_handler(int s, struct sockaddr* to)
{
char buf[1024] = "TEST UDP !";
int n = 0;
connect(s, to, sizeof(*to);
n = write(s, buf, 1024);
read(s, buf, n);
}
|
2. udp报文丢失问题
因为UDP自身的特点,决定了UDP会相对于TCP存在一些难以解决的问题。第一个就是UDP报文缺失问题。
在UDP服务器客户端的例子中,如果客户端发送的数据丢失,服务器会一直等待,直到客户端的合法数据过来。如果服务器的响应在中间被路由丢弃,则客户端会一直阻塞,直到服务器数据过来。
防止这样的永久阻塞的一般方法是给客户的recvfrom调用设置一个超时,大概有这么两种方法:
1)使用信号SIGALRM为recvfrom设置超时。首先我们为SIGALARM建立一个信号处理函数,并在每次调用前通过alarm设置一个5秒的超时。如果recvfrom被我们的信号处理函数中断了,那就超时重发信息;若正常读到数据了,就关闭报警时钟并继续进行下去。
2)使用select为recvfrom设置超时
设置select函数的第五个参数即可。
3. udp报文乱序问题
所谓乱序就是发送数据的顺序和接收数据的顺序不一致,例如发送数据的顺序为A、B、C,但是接收到的数据顺序却为:A、C、B。产生这个问题的原因在于,每个数据报走的路由并不一样,有的路由顺畅,有的却拥塞,这导致每个数据报到达目的地的顺序就不一样了。UDP协议并不保证数据报的按序接收。
解决这个问题的方法就是发送端在发送数据时加入数据报序号,这样接收端接收到报文后可以先检查数据报的序号,并将它们按序排队,形成有序的数据报。
4. udp流量控制问题
总所周知,TCP有滑动窗口进行流量控制和拥塞控制,反观UDP因为其特点无法做到。UDP接收数据时直接将数据放进缓冲区内,如果用户没有及时将缓冲区的内容复制出来放好的话,后面的到来的数据会接着往缓冲区放,当缓冲区满时,后来的到的数据就会覆盖先来的数据而造成数据丢失(因为内核使用的UDP缓冲区是环形缓冲区)。因此,一旦发送方在某个时间点爆发性发送消息,接收方将因为来不及接收而发生信息丢失。
解决方法一般采用增大UDP缓冲区,使得接收方的接收能力大于发送方的发送能力。
1
2
| int n = 220 * 1024; //220kB
setsocketopt(sockfd, SOL_SOCKET, SO_RCVBUF, &n, sizeof(n));
|
这样我们就把接收方的接收队列扩大了,从而尽量避免丢失数据的发生。

