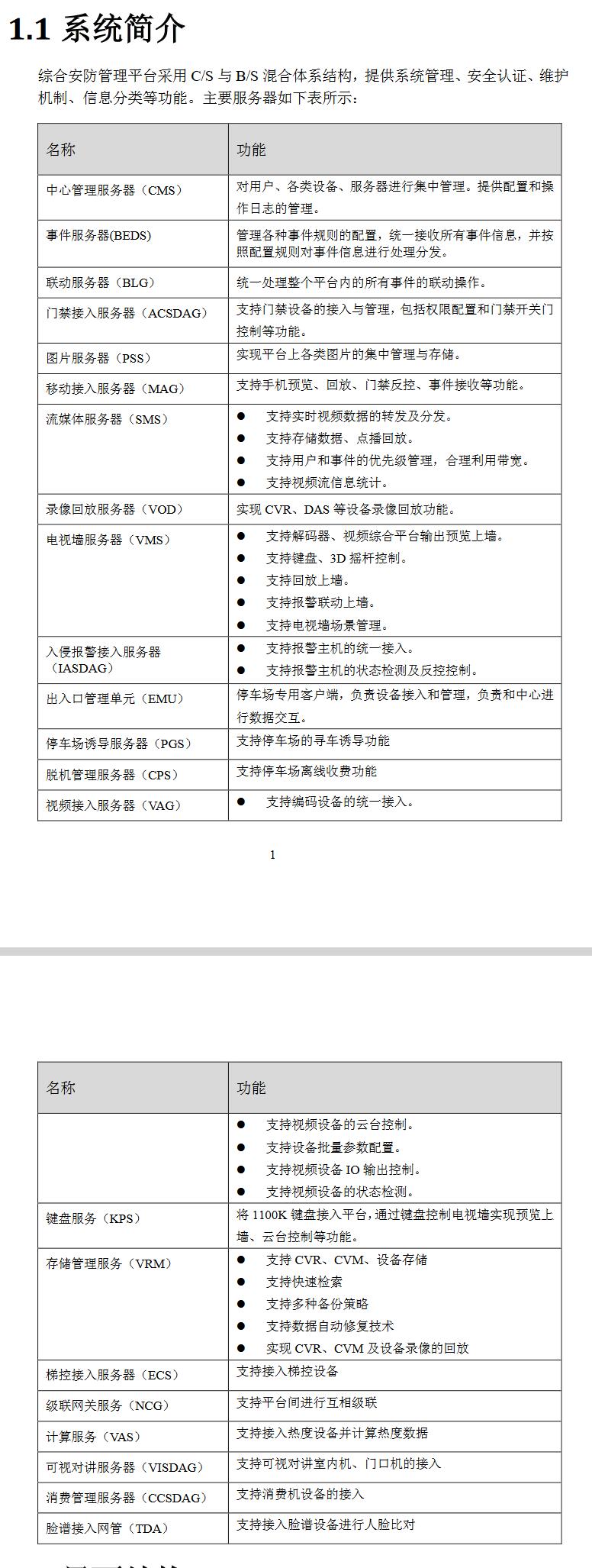
https://www.win7zhijia.cn/jiaocheng/win7_32893.html
步骤如下:
1、按WIN+R调出 “运行” 栏,输入 cmd , 以管理员身份运行。
输入命令
1
| |
启动虚拟wifi网卡,其中ssid等于后的参数为网络名,key为密钥。输入命令后,enter键回车,会提示启动承载网络。
- 打开网络共享中心,点击 “更改适配器"。我们会看到一个名叫 "无线网络连接2” 的网络连接,这就是Win7自带的虚拟wifi网卡,
接着右键点击 “正在连接的网络” ,属性,看到 “共享” 选项卡,点击进入,勾选 “允许其他网络用户通过此计算机的Internet连接来连接” ,并选择 “无线网络连接2” 来连接
3、打开命令提示符,输入命令,
1
| |
启动承载网络,打开手机的wlan,会搜到一个名叫 “kktest” 的网络,此时输入刚设好的密钥 12345678 ,就可以了。
4、输入命令,
1
| |
即可查看所创建网络的基本信息,如wifi名称、最大连接数、已连接数,
使用
1
| |
可以查看所创建网络的密码