RunAsDate 修改时间运行,达到永久试用
RunAsDate.zip
运行32位版本
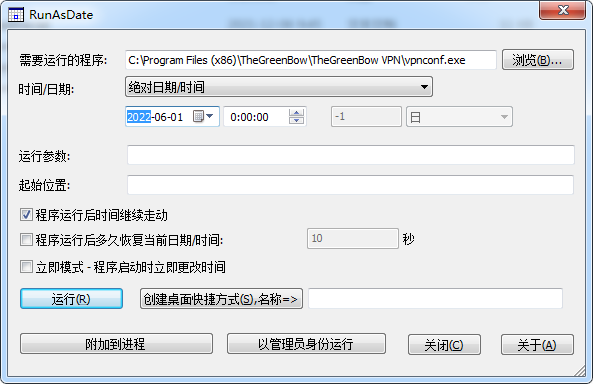
需要运行的程序 C:\Program Files (x86)\TheGreenBow\TheGreenBow VPN\vpnconf.exe
时间/日期 调到安装之前
可以运行 或者 创建桌面快捷方式
server
1
2
3
4
| setenforce 0
vim /etc/sysconfig/selinux
SELINUX=enforcing => SELINUX=disabled
|
vim /etc/strongswan/strongswan.d/charon.conf
vim /etc/strongswan/swanctl/swanctl.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| # Include config snippets
include conf.d/*.conf
connections {
# cp www.abcxyzkk.xyz_apache/root_bundle.crt /etc/strongswan/swanctl/x509ca/
# cp www.abcxyzkk.xyz_apache/www.abcxyzkk.xyz.crt /etc/strongswan/swanctl/x509/
# cp www.abcxyzkk.xyz_apache/www.abcxyzkk.xyz.key /etc/strongswan/swanctl/private/
# EAP android 客户端 https://download.strongswan.org/Android/
# EAP android 客户端 https://raw.githubusercontent.com/abcdxyzk/abcdxyzk.github.io_files/master/tools/vpn/strongSwan-2.3.3.apk
# EAP 服务端转发上网 iptables -t nat -A POSTROUTING -s 100.64.0.0/24 -o eth0 -j MASQUERADE
# echo 1 > /proc/sys/net/ipv4/ip_forward
testEAP {
version = 2
proposals = default
local_addrs = 192.168.100.178
pools = pool1
rekey_time = 24h
local {
certs = www.npcable.cn.crt
id = www.npcable.cn
}
remote {
auth = eap-mschapv2
id = %any
}
children {
testEAP_child {
# local_ts = 0.0.0.0/0
local_ts = 192.168.100.0/24
#remote_ts = 100.64.0.0/24
esp_proposals = default
rekey_time = 24h
}
}
}
}
secrets {
private-www {
file = www.npcable.cn.key
}
eap-user {
id = abc
secret = abc123
}
eap-user1 {
id = abc1
secret = abc123
}
}
pools {
pool1 {
addrs = 100.64.0.0/24
# hk的时候必须要填
dns = 8.8.8.8
}
}
|
1
2
3
4
| service strongswan restart
swanctl --load-all
swanctl --list-sas
|
exe
https://raw.githubusercontent.com/abcdxyzk/abcdxyzk.github.io_files/master/tools/vpn/TheGreenBow_VPN_Client_6.64.3.2.exe
https://raw.githubusercontent.com/abcdxyzk/abcdxyzk.github.io_files/master/tools/vpn/tgbvpnvirtm.inf_amd64_6.1.zip
https://raw.githubusercontent.com/abcdxyzk/abcdxyzk.github.io_files/master/tools/vpn/tgbmpenum.inf_amd64_6.1.zip
先调系统时间
改到2035年左右,这样可以一直试用。时间改太大也不行?
win10
安装 6.64.3.2 就 OK
win7
先安装 6.64.3.2 , 再调整两个驱动: 网络适配器、系统设备
调整驱动 TheGreenBow Virtual Miniport Adapter
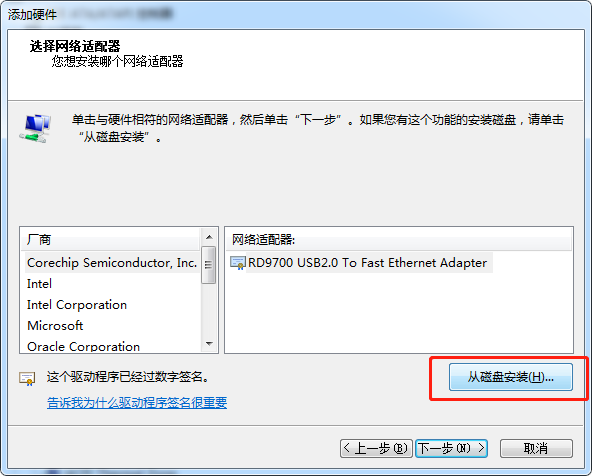
计算机管理 –> 设备管理器 –> 点击"网络适配器", 再点击"菜单"上的"操作", 再点击"添加过时硬件(L)"
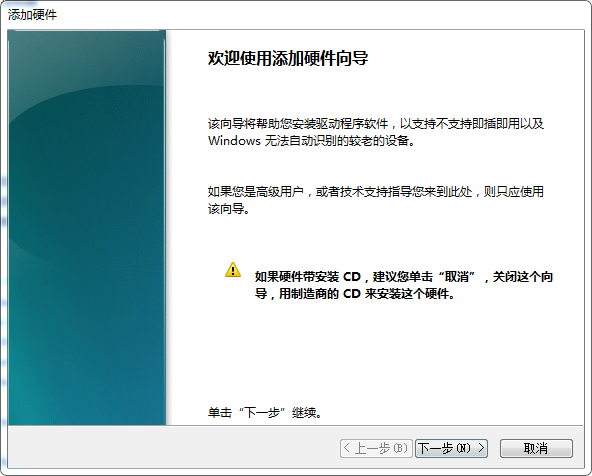
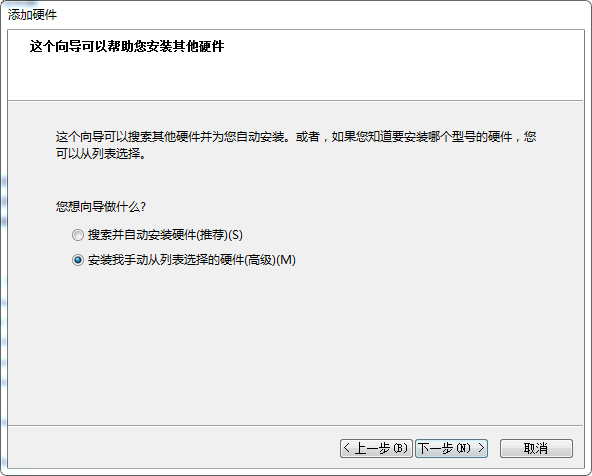
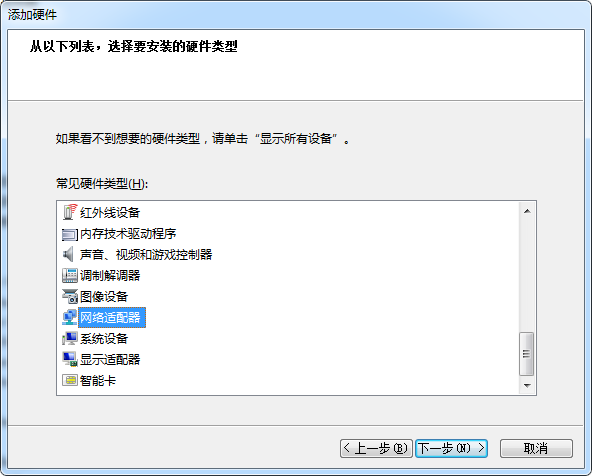
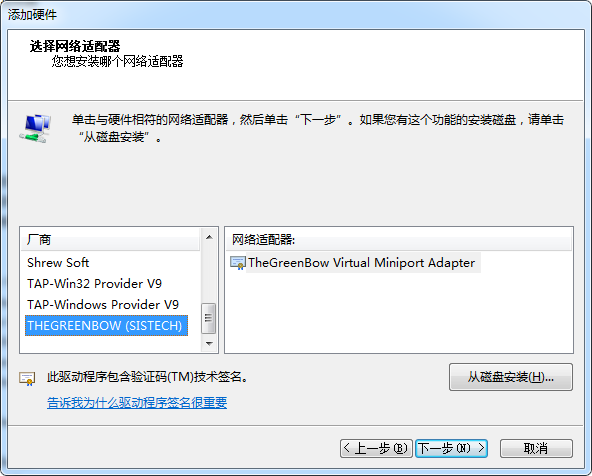
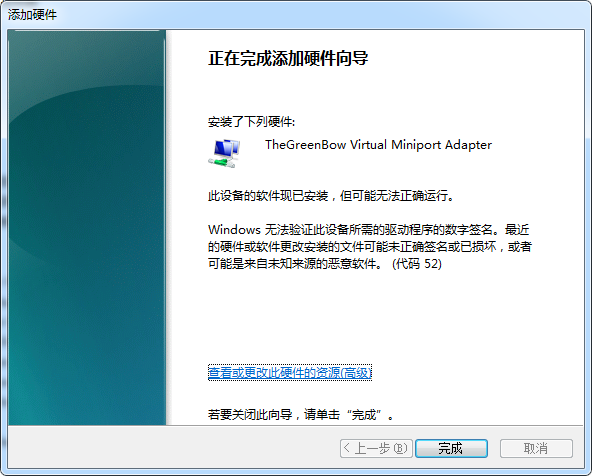

再卸载这个设备,同时勾选"删除此设备的驱动程序软件"
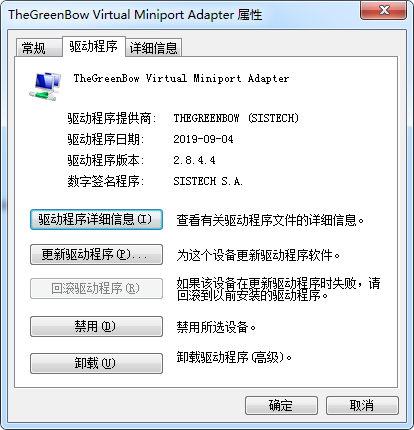
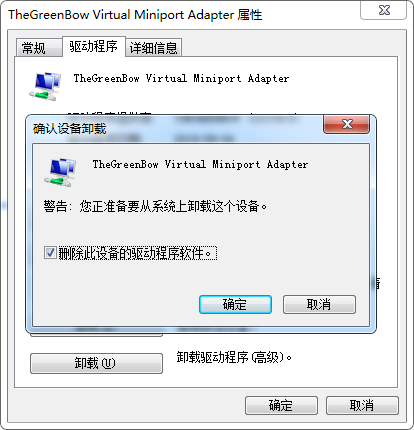
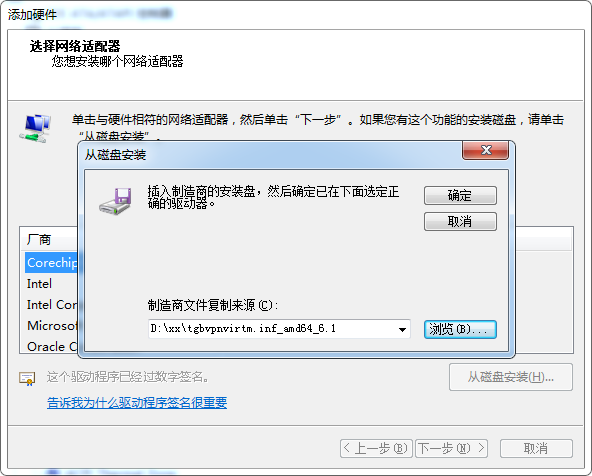
再添加从 6.10.14.4 那里copy来的驱动
点击"网络适配器", 再点击"菜单"上的"操作", 再点击"添加过时硬件(L)"
tgbvpnvirtm.inf_amd64_6.1.zip
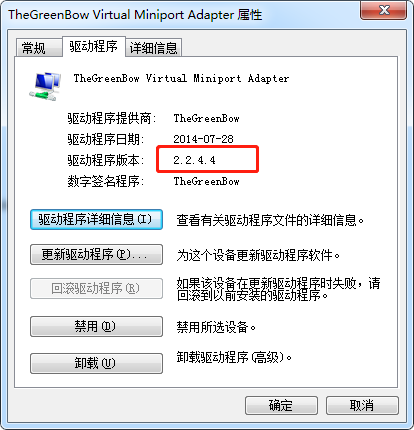
调整驱动 TheGreenBow VPN Miniport Enumerator
不用先添加,可以直接卸载。同时勾选"删除此设备的驱动程序软件"
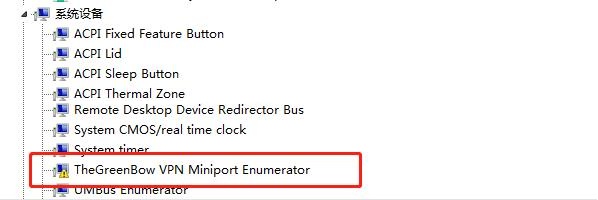
再添加从 6.10.14.4 那里copy来的驱动
点击"系统设备", 再点击"菜单"上的"操作", 再点击"添加过时硬件(L)"
tgbmpenum.inf_amd64_6.1.zip
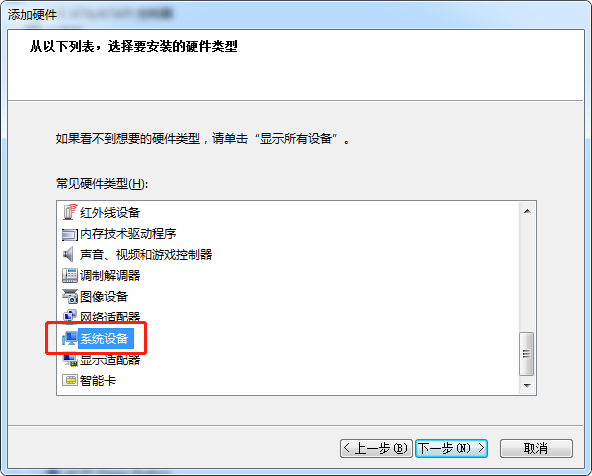
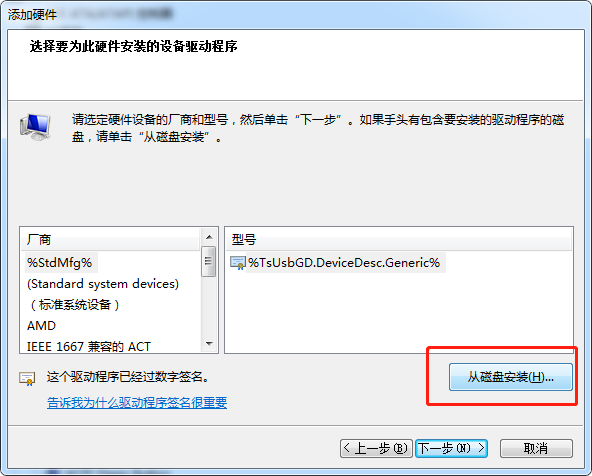
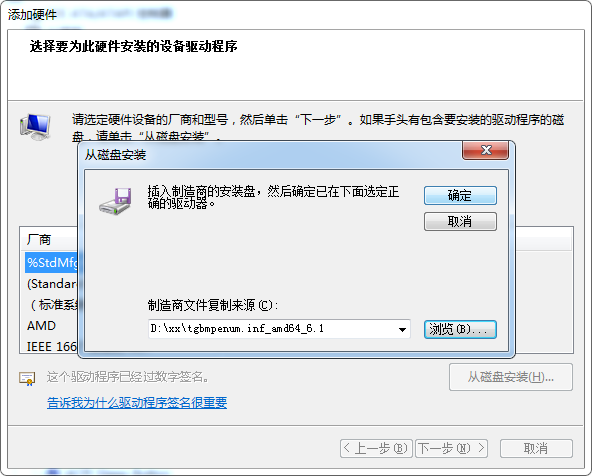
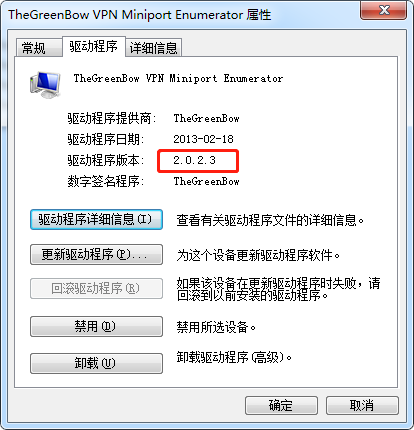
配置
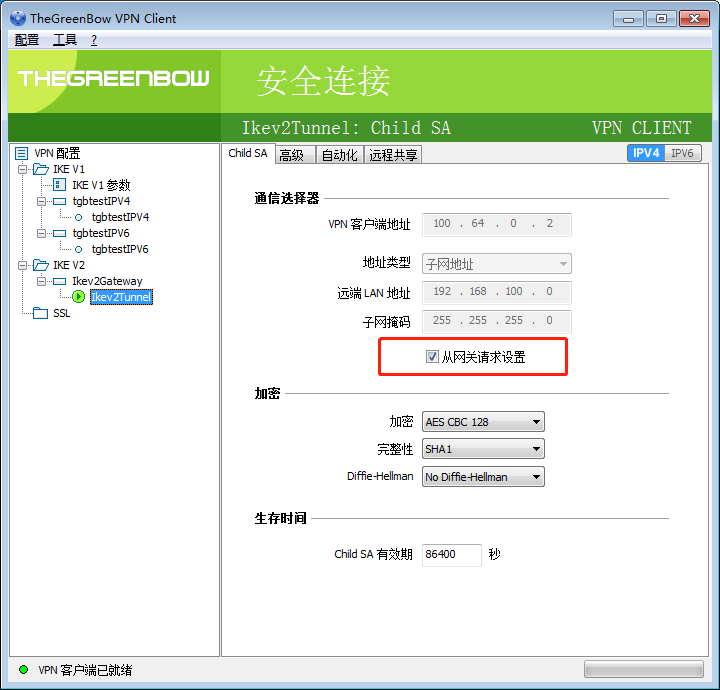
rekey可能失败,改长 ike_sa, ipsec_sa 的存活时间
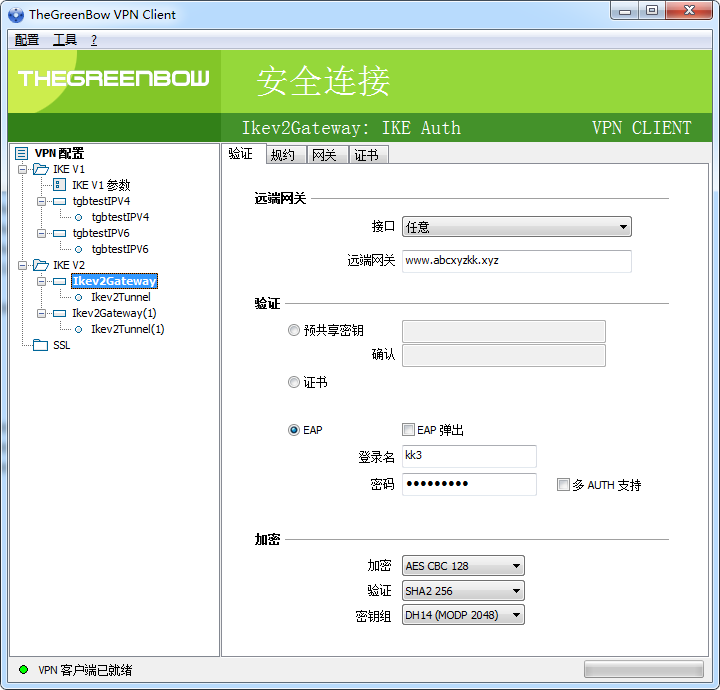
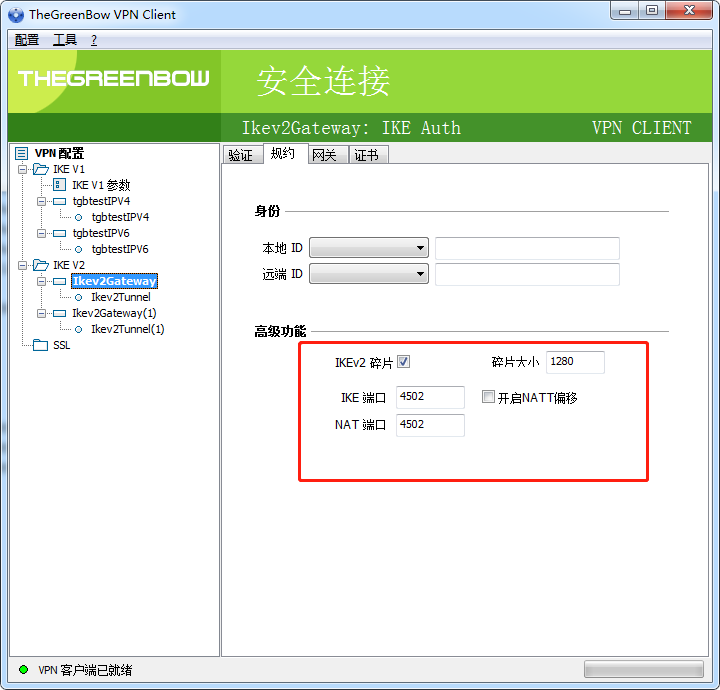
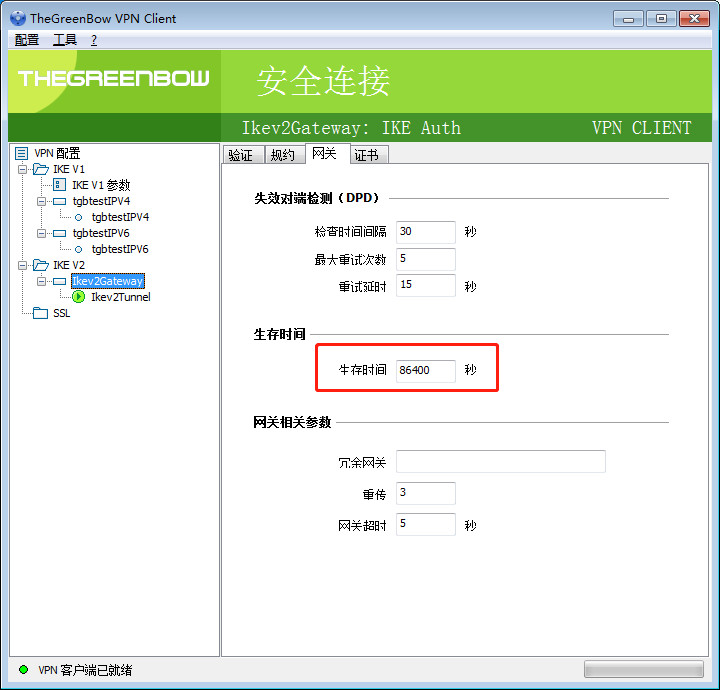
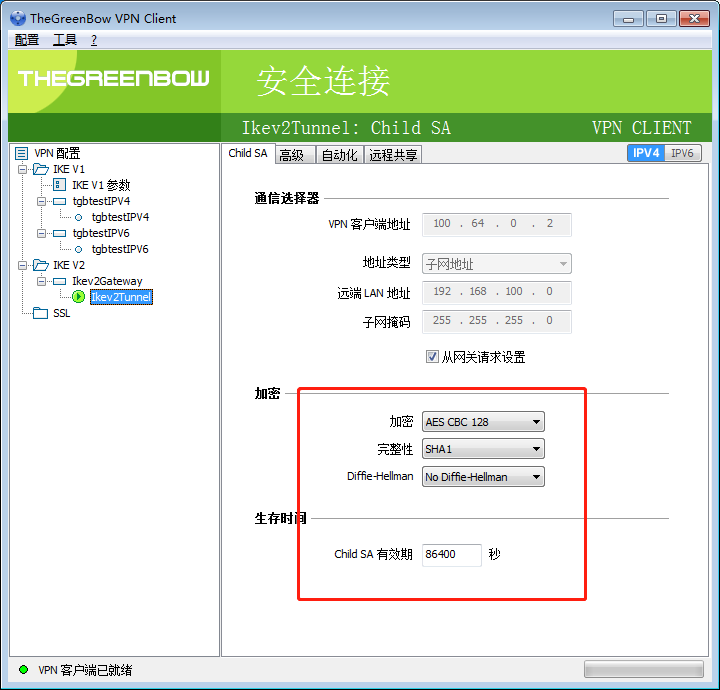
win7 在连接的时候有一定的失败概率
多网卡可能会失败,禁用掉其他网卡
点两下 “从网关请求设置” 好像能恢复。
破解
似乎是这个字段,但基本无法破解
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\TgbIke.exe
sBoot32

