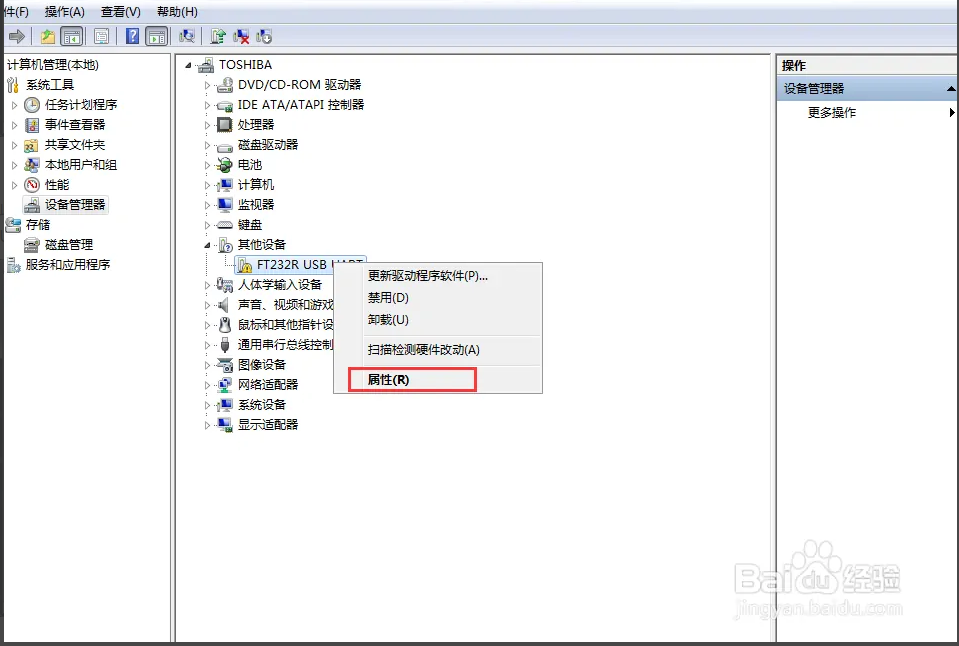
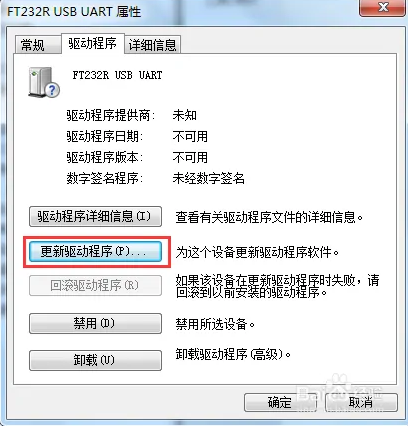
https://blog.csdn.net/weixin_39371711/article/details/79432848
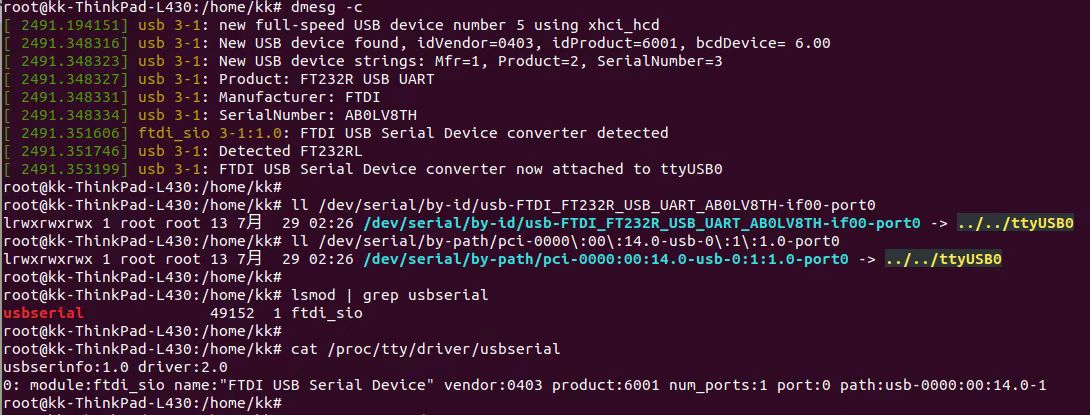
tty
1
| |
screen
1
| |
minicom
1
| |
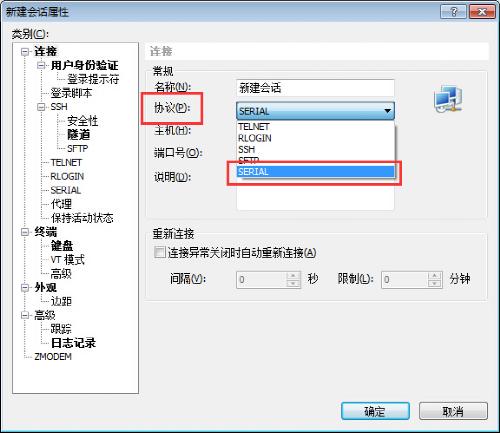
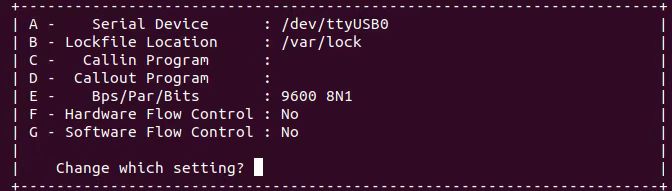
选择
Serial port setup


https://blog.csdn.net/weixin_39371711/article/details/79432848
1
| |
1
| |
1
| |
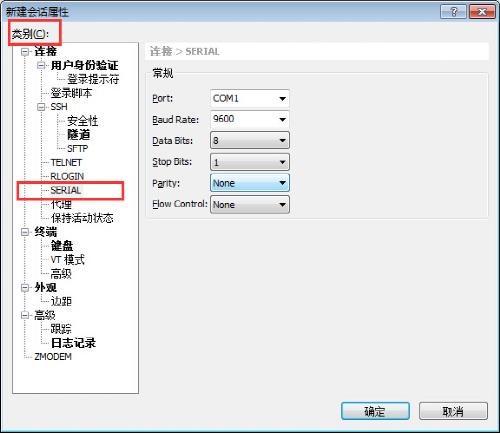
选择
Serial port setup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |