https://www.cnblogs.com/logon/p/3748020.html
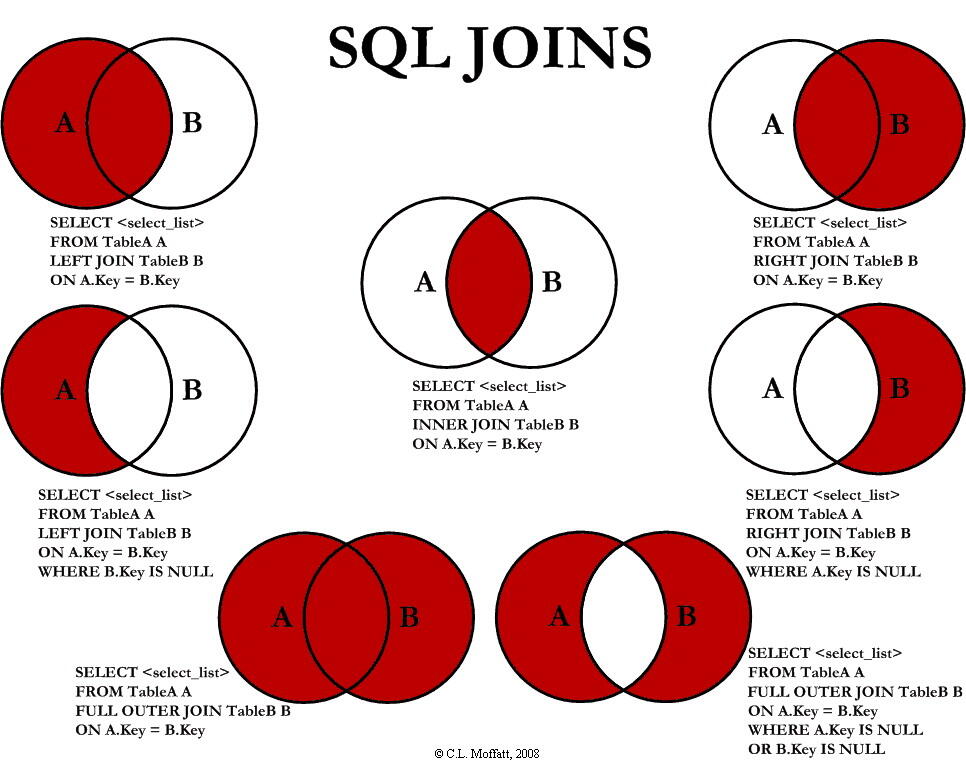
对于SQL的Join,在学习起来可能是比较乱的。我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚。Coding Horror上有一篇文章,通过文氏图 Venn diagrams 解释了SQL的Join。我觉得清楚易懂,转过来。
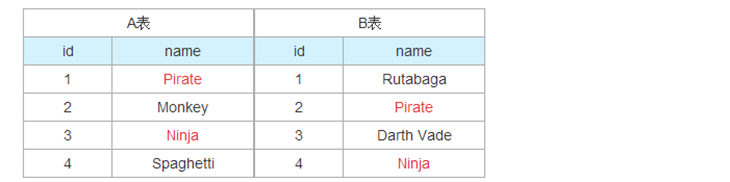
假设我们有两张表。Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的,如下所示:让我们看看不同JOIN的不同
1.INNER JOIN
1
| |

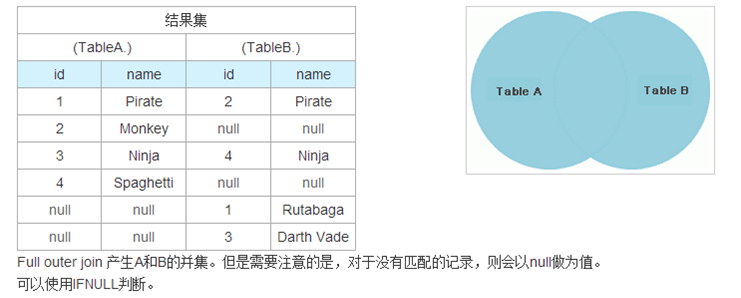
2.FULL [OUTER] JOIN
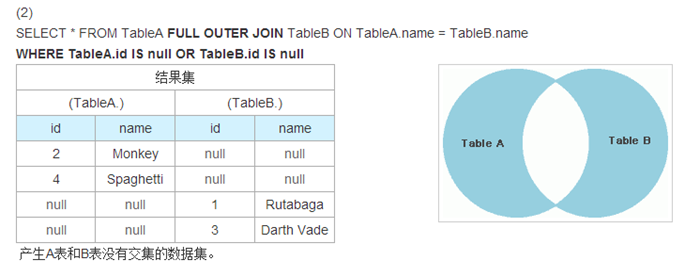
(1)
1
| |

4.RIGHT [OUTER] JOIN
RIGHT OUTERJOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。这里不介绍了。
5.UNION 与 UNION ALL
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 只选取记录,而UNION ALL会列出所有记录。
(1)
1
| |

选取不同值
(2)
1
| |
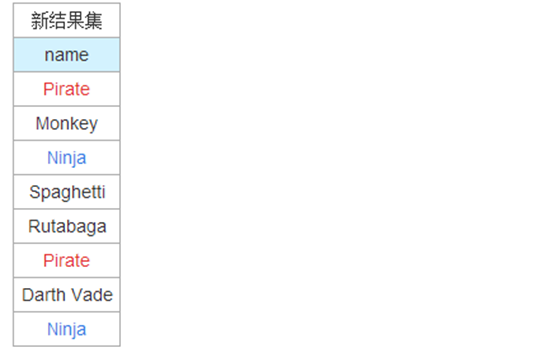
全部列出来
(3)注意:
1
| |
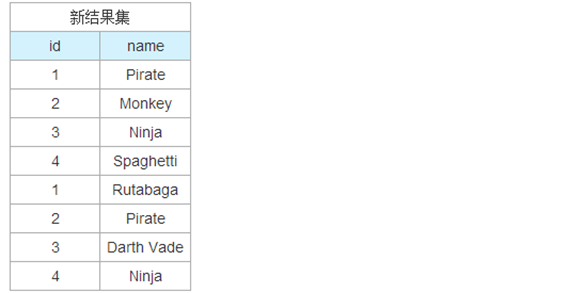
由于 id 1 Pirate 与 id 2 Pirate 并不相同,不合并
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个 N*M 的组合,即笛卡尔积。表达式如下:SELECT * FROM TableA CROSS JOIN TableB
这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。