读

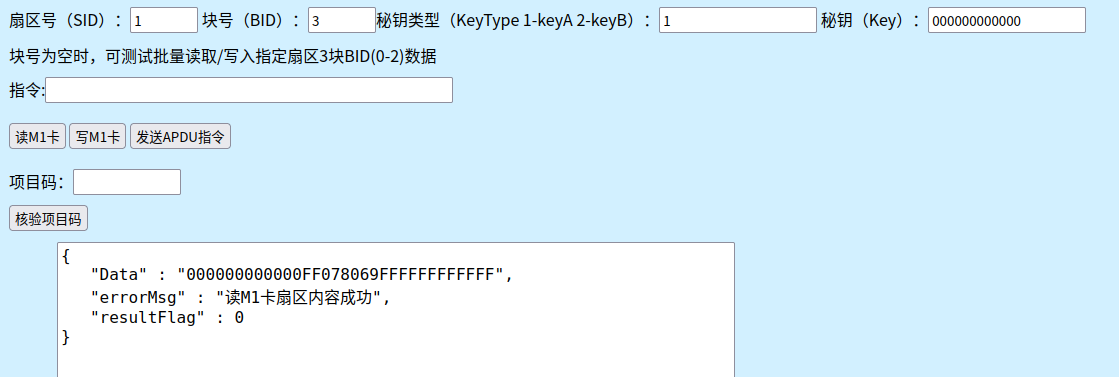
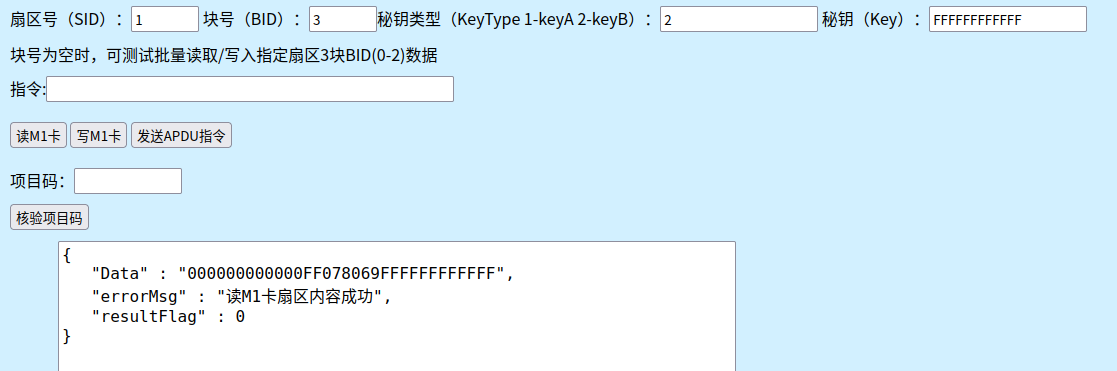
写
写完之后再读,就必须输 key
读出的 keyA 不显示??? keyB会变化
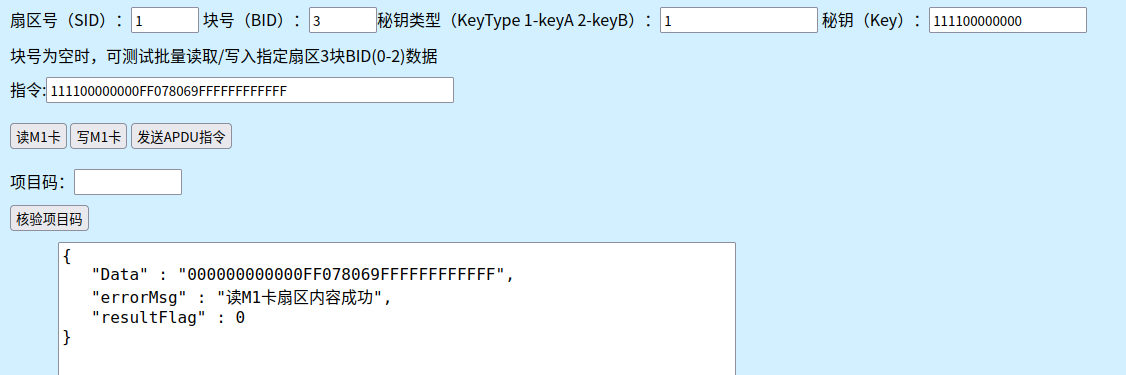
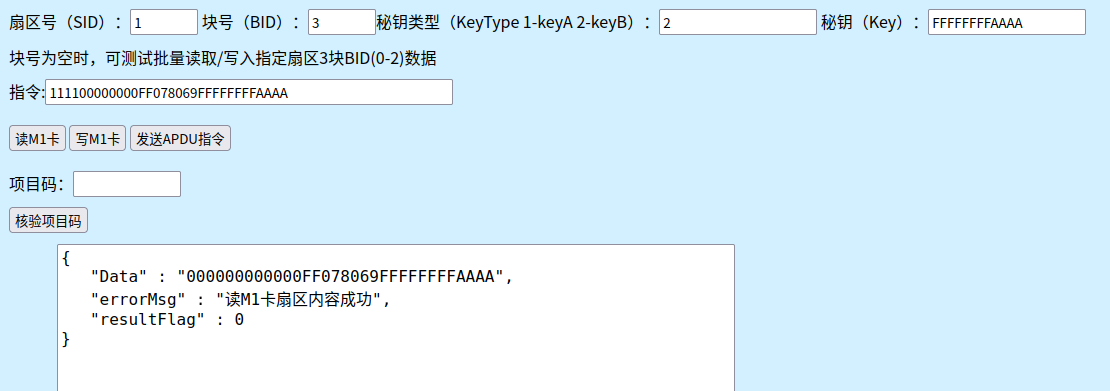
https://nfctool.cn/42
一、M1卡数据结构
Mifare Classic提供1k-4k的容量,现在国内门禁采用的多数是Mifare Classic 1k(S50)[后面简称M1卡]。
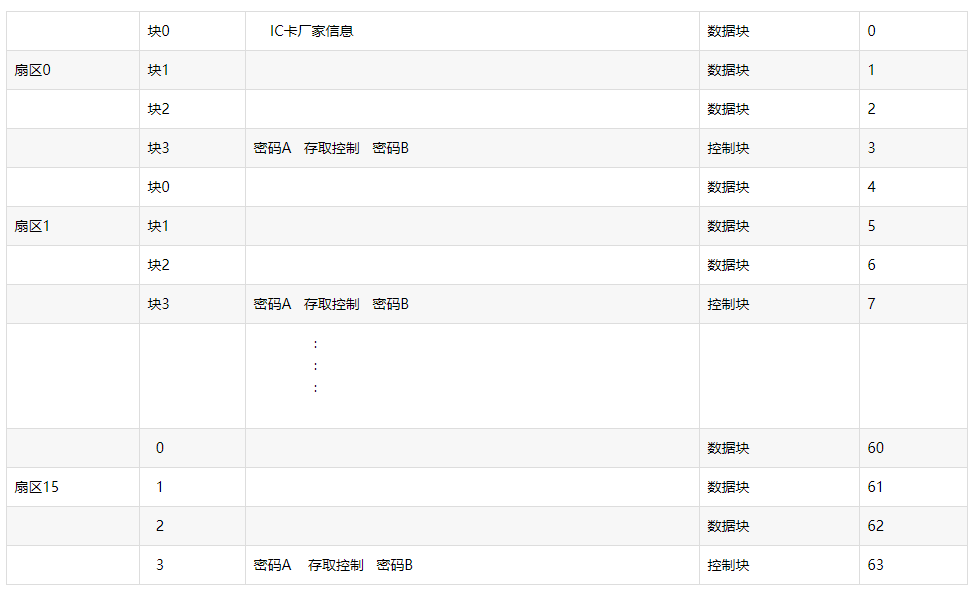
M1卡有从0到15共16个扇区,每个扇区配备了从0到3共4个段,每个段可以保存16字节的内容,为什么这里要强调从0开始呢?这跟C语言里面数组下标默认从0开始是差不多的,好计算地址偏移,我们不必太过在意,只是要记住是从0开始,写入数据的时候不要写错地方就可以了。每个扇区的第4个段(也就是3段)是用来保存KeyA,KeyB和控制位的,因为M1卡允许每个扇区有一对独立的密码保护,这样能够更加灵活的控制数据的操作,控制位就是这个扇区各种详细权限计算出来的结果。
每张M1卡都有一个全球唯一的UID号,这个UID号保存在卡的第一个扇区(0扇区)的第一段(0段),也称为厂商段,其中前4个字节(就是前8位,两位一个字节)是卡的UID,第5个字节是卡UID的校验位,剩下的是厂商数据。并且这个段在出厂之前就会被设置了写入保护,只能读取不能修改,当然也有例外,有种叫UID卡的特殊卡,UID是没有设置保护的,其实就是厂家不按规范生产的卡,M1卡出厂是要求要锁死UID的。下图很清晰的列出了M1卡的结构。
二、M1卡种类
普通IC卡,0扇区不可以修改,其他扇区可反复擦写,我们使用的电梯卡、门禁卡等智能卡发卡商所使用的都是 M1 卡,可以理解为物业发的母卡。其他IC卡都是后门卡,可通过各种写入方法修改0扇区,实现复制母卡的目的。
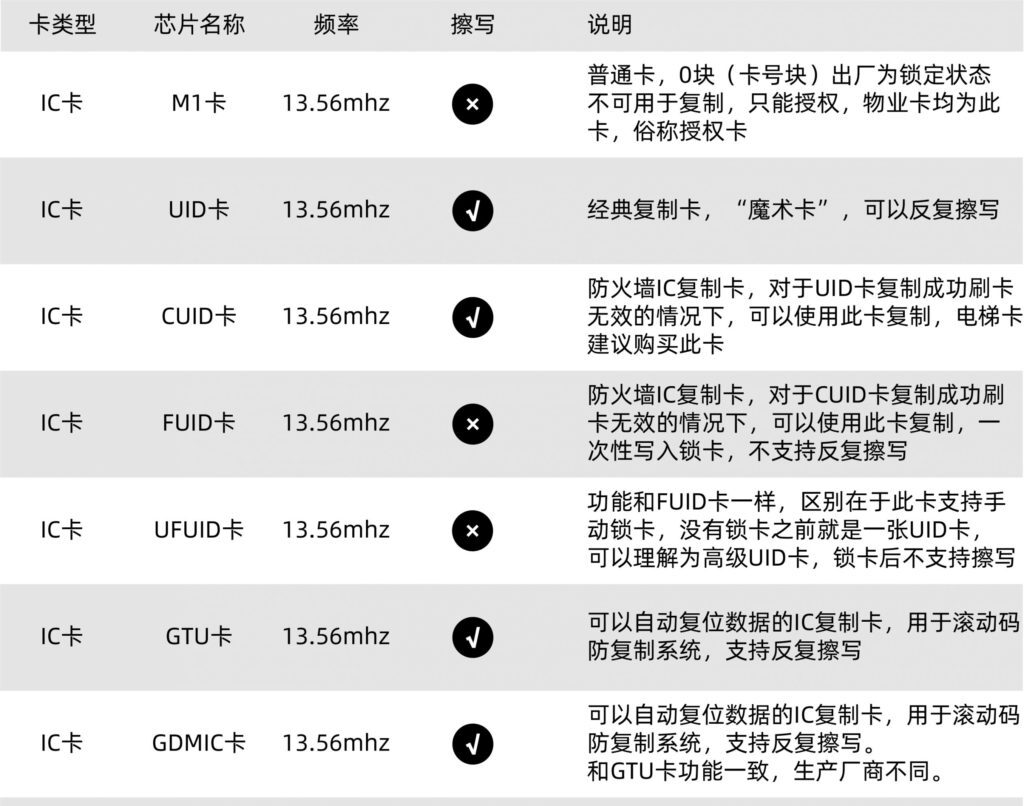
UID 卡(国外称GEN1)
普通复制卡,主要应用在IC卡复制上,遇到带有防火墙的门禁读卡器就会失效。这类门禁读卡器在刷卡的时候会默认发出后门指令修改UID卡卡号,导致UID卡无法再次使用,即UID卡只能使用一次。UID卡失效后可通过比对卡号是否被修改来判断门禁读卡器是否带防火墙。
由于只有读卡器才能发出后门指令,手机不支持发送后门指令,所以UID卡只能通过读卡器修改卡号和免密读写,无法使用手机修改卡号。UID卡即使写入时数据错误,也可以通过后门指令强行格式化救活。
CUID 卡(国外称GEN2)
可擦写防屏蔽卡,可以重复擦写所有扇区,门禁读卡器带防火墙的话,就可以使用CUID绕过防火墙。CUID无需锁卡自动起防屏蔽作用,不会像FUID或UFUID等需要锁卡后才起到防屏蔽作用。
CUID卡不响应后门指令,直接使用普通指令就可以修改卡号,所以可以用手机修改卡号。不过正因为CUID卡不响应后门指令,所以一旦写入过程数据出错,那么卡片将直接报废。
FUID 卡(国外称GEN2)
不可擦写防屏蔽卡,此卡的特点是0扇区只能写入一次,写入一次后FUID就变成普通 M1 卡,CUID卡绕过防火墙失败的话可以使用FUID尝试。
UFUID 卡
高级复制卡,我们可理解为是 UID 和 FUID 的合成卡,执行锁卡操作后变为 普通M1 卡,过程不可逆,不锁卡就是 UID 卡。市面上支持锁卡指令的读卡器和软件很少,我们的APP和读卡器支持UFUID卡的锁卡指令。
GTU/GUID/GDMIC卡
滚动码复制卡,用于滚动码防复制电梯系统,GTU卡锁卡后数据不再改变,每次断电后都会恢复为锁卡前的数据,从而使滚动码电梯系统无法正常滚动卡内数据,实现破解滚动码系统的目的。GTU可解锁,解锁后可通过GTU专用指令进行数据修改。
3.M1卡详解
https://blog.csdn.net/hiwoshixiaoyu/article/details/104048663
M1卡分为16个扇区,每个扇区4块(块0~3),共64块。第0扇区的块0(即绝对地址0块)用于存放厂商代码,已经固化,不可更改。
其他各扇区的块0、块1、块2为 数据块 ,用于存贮数据;块3为 控制块 ,存放密码A、存取控制、密码B,其结构如下:
控制字节
https://blog.51cto.com/u_16213651/11127776
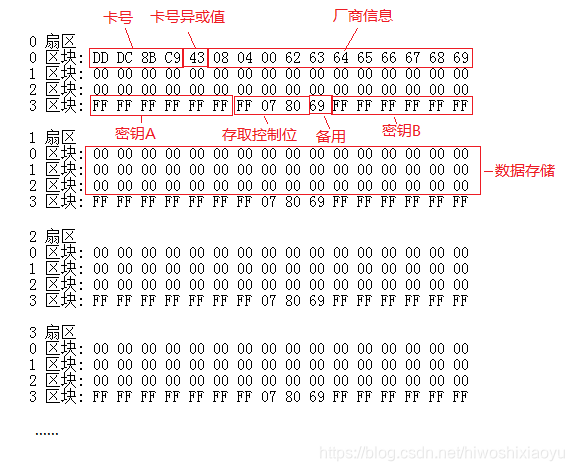
Mifare1S50卡 出厂默认每个扇区的数据块3中的数据都是:
FF FF FF FF FF FF FF 07 80 69 FF FF FF FF FF FF
其中:
FF FF FF FF FF FF 为A密钥
FF 07 80 69 为控制字节
FF FF FF FF FF FF为B密钥
控制字节FF 07 80 69所表示的控制权限含义:可用广州慧斯佳智能科技有限公司开发的M1S50卡控制字节工具进行解析得到
常见控制字节组
控制字节的组合方式虽然多,但实际用得比较多的主要是以下4种:
FF 07 80 69
这种字节组合方式是最常见的;只要A密钥或者B密钥验证通过,便可以读写数据块数据,修改A、B密钥,修改控制字节
优点在于:控制字节直接出厂默认,无需重新设置。读写数据,修改密钥都比较方便。缺点在于:安全性能差,数据和密钥容易泄露和被修改

7F 07 88 69
这种字节组合方式是:只要A密钥或者B密钥验证通过,便可以读写数据块数据,修改A、B密钥,控制字节都需要B密钥验证通过才可以
优点在于:密钥B权限最高,只要知道密钥B,就可以对A密钥和控制字节进行改写。应用上一般是由最高管理员掌握密钥B,配置多个密钥A给到对应的管理员。缺点在于:密钥B很重要,一旦忘记,卡就不能再改写密钥

08 77 8F 69
这种字节组合:由密钥A读密钥B来写,可以说是上面一种组合的变体,对于密钥B有更强的保护

FF 00 F0 69
这种字节组合:数据块不具有写入权限;只能读取。最常见用于门禁机发卡;在发卡阶段写入合法的身份识别数据之后;卡片的数据便再也不能修改

已知控制字节·解析权限过程详述
以最常见的 FF 07 80 69 字节组合为例
6: FF 7: 07 8: 80 9: 69
其中字节9目前是作为保留字节,一般固定为0x69;主要是看字节6,7,8这3个字节
步骤1:将字节6,7,8转换成对应的二进制格式,如下表
6: FF 1111 1111
7: 07 0000 0111
8: 80 1000 0000
步骤2:对字节6,7,8进行相应的处理
字节6处理操作:8位2进制数进行按位取反
6: FF 1111 1111 => 0000 0000
字节7处理操作:高4位2进制数保留;低4位2进制数取反
7: 07 0000 0111 => 0000 1000
字节8处理操作:8位2进制数不做任何处理,直接保留
8: 80 1000 0000 => 1000 0000
步骤3:将处理后的字节6,7,8的8位2进制数组成1张表格;如下表
| bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
权限增值表中的 符号 | C23_b
| C22_b
| C21_b
| C20_b
| C13_b
| C12_b
| C11_b
| C10_b
|
字节6
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
权限增值表中的 符号 | C13 | C12 | C11 | C10 | C33_b
| C32_b
| C31_b
| C30_b
|
字节7
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
权限增值表中的 符号 | C33 | C32 | C31 | C30 | C23 | C22 | C21 | C20 |
字节8
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
其中:
C10C20C30组合:表示扇区中数据块0的权限;具体权限需要对应下图的数据块权限真值表
C11C21C31组合:表示扇区中数据块1的权限;具体权限需要对应下图的数据块权限真值表
C12C22C32组合:表示扇区中数据块2的权限;具体权限需要对应下图的数据块权限真值表
C13C23C33组合:表示扇区中密钥数据块(即数据块3)的权限;具体权限需要对应下图的密钥块权限真值表
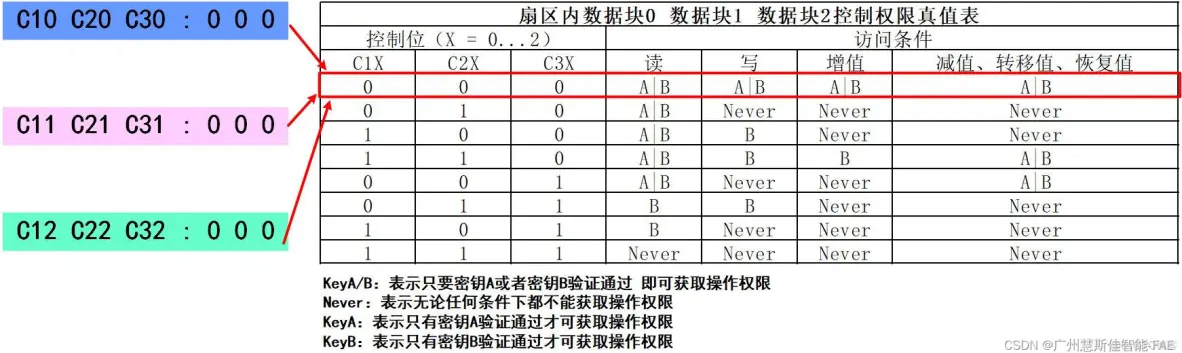
组合C10C20C30,C11C21C31,C12C22C32的值均为 0 0 0,对应到数据块控制权限真值表中权限为:读:A|B 写:A|B 增值:A|B 减值、转移值、恢复值:A|B
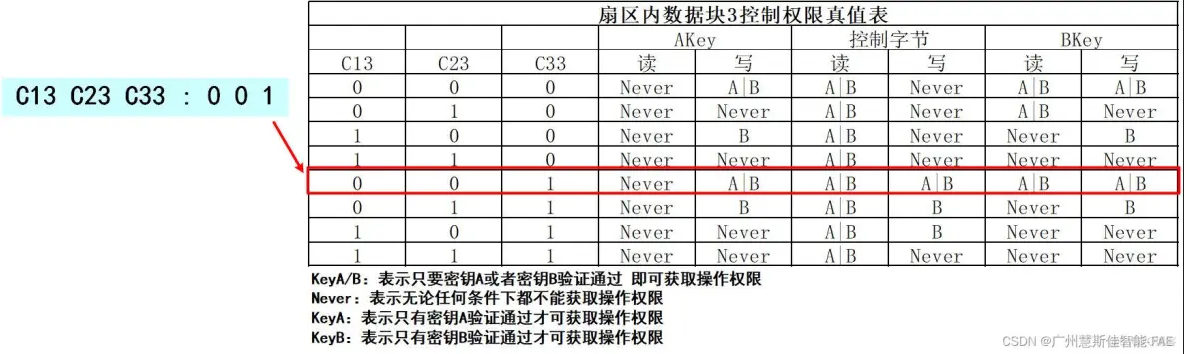
组合C13C23C33的值为 0 0 1,对应到密钥块控制权限真值表中权限为:
AKey:读:Never 写:A|B
控制字节:读:A|B 写:A|B
BKey:读:A|B 写:A|B
综上:FF 07 80 69
数据块权限为:读:A|B 写:A|B 增值:A|B 减值、转移值、恢复值:A|B
密钥块权限为:AKey:读:Never 写:A|B
控制字节:读:A|B 写:A|B
BKey:读:A|B 写:A|B
所以控制字节FF 07 80 69的控制权限是:
只要A密钥或者B密钥验证通过,便可以读写数据块0,1,2;还可以对数据块0,1,2进行增值,减值, 转移值,恢复值等操作
只要A密钥或者B密钥验证通过,便可以写入A密钥;读写控制字节,读写B密钥;但无论任何条件下,都无法读取A密钥
根据所需要权限·生成对应控制字节
假设~~~现在对扇区中数据块0,1,2,密钥块的控制权限分别是以下需求:
1.数据块0:只有B密钥验证通过;才可以读取数据;但无论任何条件下,都不可以写入数据;不可以进行增值,减值, 转移值,恢复值等操作
2.数据块1:只要A密钥或者B密钥验证通过,就可以读取数据;但无论任何条件下,都不可以写入数据;不可以进行增值,减值, 转移值,恢复值等操作
3.数据块2:只有B密钥验证通过;才可以读取数据;但无论任何条件下,都不可以写入数据;不可以进行增值,减值, 转移值,恢复值等操作
4.密钥块:只要A密钥或者B密钥验证通过,就可以读取控制字节,但无论任何条件下,控制字节都不能被修改;只有B密钥验证通过;才可以修改A密钥和B密钥;但无论任何条件下,都不能读取A密钥和B密钥
结合上述需求分析:
数据块0权限值C10C20C30 和 数据块2权限值C12C22C32 均为下表红框中的值,既是C10C20C30 = 1 0 1;C12C22C32 = 1 0 1
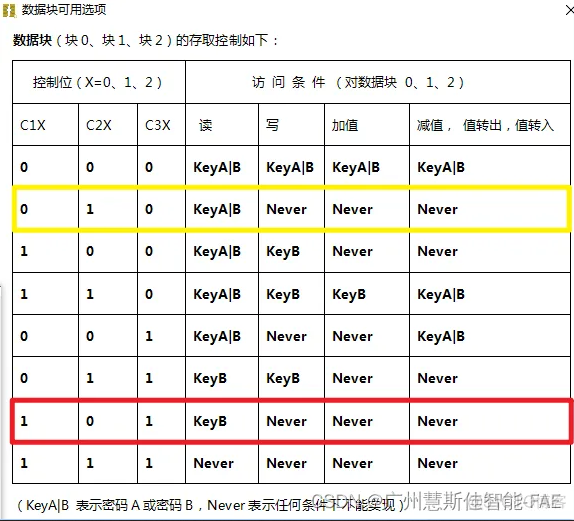
数据块1权限值C11C21C301为下表黄框中的值,既是C11C21C31 = 0 1 0
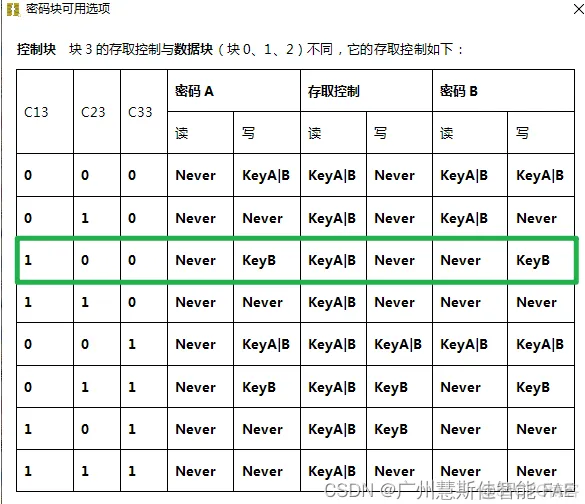
密钥块权限值C13C23C33为下表中绿框中的值,既是C13C23C33 = 1 0 0
步骤1:将分析需求得到的C10C20C30 = 1 0 1;C11C21C31 = 0 1 0;C12C22C32 = 1 0 1;C13C23C33 = 1 0 0;填入下表
| bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
权限增值表中的 符号 | C23_b
| C22_b
| C21_b
| C20_b
| C13_b
| C12_b
| C11_b
| C10_b
|
| | | | | | | | |
权限增值表中的 符号 | C13 | C12 | C11 | C10 | C33_b
| C32_b
| C31_b
| C30_b
|
| 1 | 1 | 0 | 1 | | | | |
权限增值表中的 符号 | C33 | C32 | C31 | C30 | C23 | C22 | C21 | C20 |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
步骤2:根据已经填入的值,对表格进行补全处理
补全处理:_b表示取反;例如C30_b表示是C30的取反值
| bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
权限增值表中的 符号 | C23_b
| C22_b
| C21_b
| C20_b
| C13_b
| C12_b
| C11_b
| C10_b
|
| 1
| 1
| 0
| 1
| 0
| 0
| 1
| 0
|
权限增值表中的 符号 | C13 | C12 | C11 | C10 | C33_b
| C32_b
| C31_b
| C30_b
|
| 1 | 1 | 0 | 1 | 1
| 0
| 1
| 0
|
权限增值表中的 符号 | C33 | C32 | C31 | C30 | C23 | C22 | C21 | C20 |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
步骤3:分别对3组8位2进制数进行格式转换
将8位2进制数C23_bC22_bC21_bC20_bC13_bC12_bC11_bC10_b转换成16进制格式:得到字节6
bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
C23_b
| C22_b
| C21_b
| C20_b
| C13_b
| C12_b
| C11_b
| C10_b
|
1
| 1
| 0
| 1
| 0
| 0
| 1
| 0
|
将8位2进制数 转换 成16进制格式;得到字节6
|
0xD2
|
将8位2进制数C13C12C11C10C33_bC32_bC31_bC30_b转换成16进制格式:得到字节7
bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
C13
| C12
| C11
| C10
| C33_b
| C32_b
| C31_b
| C30_b
|
1
| 1
| 0
| 1
| 1
| 0
| 1
| 0
|
将8位2进制数 转换 成16进制格式;得到字节7
|
0xDA
|
将8位2进制数C33C32C31C30C23C22C21C20转换成16进制格式:得到字节8
bit-7
| bit-6
| bit-5
| bit-4
| bit-3
| bit-2
| bit-1
| bit-0
|
C33
| C32
| C31
| C30
| C23
| C22
| C21
| C20
|
0
| 1
| 0
| 1
| 0
| 0
| 1
| 0
|
将8位2进制数 转换 成16进制格式;得到字节8
|
0x52
|
结合上述3个表格得到:字节6:0xD2;字节7:0xDA;字节8:0x52;字节9一般固定为0x69
所以根据需求最终生成的控制字节是:D2 DA 52 69
https://www.cnblogs.com/water-wells/p/18071238
https://www.cnblogs.com/smartlife/articles/14643023.html
https://worktile.com/kb/ask/454988.html

